前言
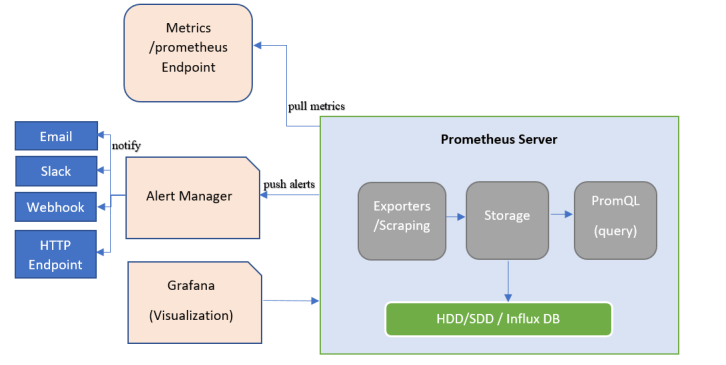
通过 基于 prometheus 打造监控报警后台 (4) - 使用 alertmanager 发送警报 我们已经能够在 prometheus 创建警报规则,并且使用 alertmanager 发送警报预警了。
但是 alertmanager 还有几个特性,并没有在上述文章讲述,本节继续延续上节的内容,讲一下 alertmanager 的几个概念。
1. 分组(Grouping)
Grouping 是把同类型的警报进行分组,合并多条警报到一个通知中。在生产环境中,特别是云环境下的业务之间密集耦合时,若出现多台 Instance 故障,可能会导致成千上百条警报触发。在这种情况下使用分组机制, 可以把这些被触发的警报合并为一个警报进行通知,从而避免瞬间突发性的接受大量警报通知,使得管理员无法对问题进行快速定位。
举个例子,比如我在 aws 的美西部署了 100 台服务器, 上面都部署了 node_exporter,然后突然有一天, aws 的美西服务商出现网络波动,导致 prometheus server 连接不到这 100 台服务器,这时候这 100 个节点就会全部触发告警, 瞬间往你的邮箱发送了 100 封邮件,直接给你造成邮件轰炸。
但是如果你有设置分组,将 100 台的主机的 up 检测都放到同一个分组内,那么这个 100 封告警就会合并成一条发送。