前言
通过 基于 prometheus 打造监控报警后台 (4) - 使用 alertmanager 发送警报 我们知道 prometheus 可以创建 警报规则 来触发警报,然后再把报警信息发送给 alertmanager ,然后 alertmanager 来发送报警通知。
但是其实 prometheus 还有一种规则,就是 记录规则
记录规则(recording rule)
记录规则允许您预先计算经常需要或计算量大的表达式,并将其结果保存为一组新的时间序列。查询预先计算的结果通常比每次需要时都执行原始表达式要快得多。这对于每次刷新时都需要重复查询相同表达式的仪表板特别有用。
也就是每一条记录规则,其实都会作为时间序列存入时序数据库,有点类似于 mysql 的 索引,这些都是有开销,所以也不能无止境的建记录规则,因为会有额外的开销。
关于记录规则的语法,其实跟警报规则一样,他们的配置差别仅仅在于 rules 小节下的第一个配置的 key 是 record 还是 alert。 其他都一样
所以语法这一块,之前在讲警报规则的时候,就讲解过了, 可以看之前讲警报规则的文章: 基于 prometheus 打造监控报警后台 (4) - 使用 alertmanager 发送警报
创建记录规则
延续之前的配置,之前有创建了一个 test-1.yml 来做警报规则的配置文件, 记录规则和警报规则 是可以写在同一个 rule 文件的。
当前也可以分开写,本例我们就分开写,放在单独的 rule 文件, /usr/local/prometheus/rules 创建一个新的文件,叫做 test-record.yml
然后记录两条规则:1
2
3
4# 当前内存使用率
node_memory_MemAvailable_bytes / node_memory_MemTotal_bytes * 100
# 当前 cpu 负载
100 - (avg by(instance) (rate(node_cpu_seconds_total{mode="idle"}[2m])) * 100)
然后将这个 rule 文件也放到 prometheus 的配置文件,并且生效。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54# 创建记录文件,并且将评估文件设置为 10s
[root@VM-64-9-centos rules]# cat test-record.yml
# rules/test-record.yml
groups:
- name: test-record
interval: 10s
rules:
- record: instance:memory:usage
expr: node_memory_MemAvailable_bytes / node_memory_MemTotal_bytes * 100
- record: instance:cpu:load
expr: 100 - (avg by(instance) (rate(node_cpu_seconds_total{mode="idle"}[2m])) * 100)
# 将 rules 的应用文件,改为整个 rules 目录的所有 yml 文件,这样子后面再增加 rule 文件就不需要调整 prometheus.yml 了
[root@VM-64-9-centos rules]# cat ../prometheus.yml
# my global config
global:
scrape_interval: 15s
evaluation_interval: 15s
alerting:
alertmanagers:
- static_configs:
- targets:
- "localhost:9093"
rule_files:
- "rules/*.yml"
scrape_configs:
- job_name: "prometheus"
static_configs:
- targets: ["localhost:9090"]
- job_name: "vmware-host"
static_configs:
- targets:
- localhost:9100
- 43.153.11.234:9100
# 校验文件格式
[root@VM-64-9-centos rules]# ../promtool check config ../prometheus.yml
Checking ../prometheus.yml
SUCCESS: 2 rule files found
SUCCESS: ../prometheus.yml is valid prometheus config file syntax
Checking ../rules/test-1.yml
SUCCESS: 3 rules found
Checking ../rules/test-record.yml
SUCCESS: 2 rules found
# 刷新配置文件
[root@VM-64-9-centos rules]# curl -X POST localhost:9090/-/reload
这样子我们就可以在 prometheus 的后台的 rules 页面看到这个 rule 文件的规则了
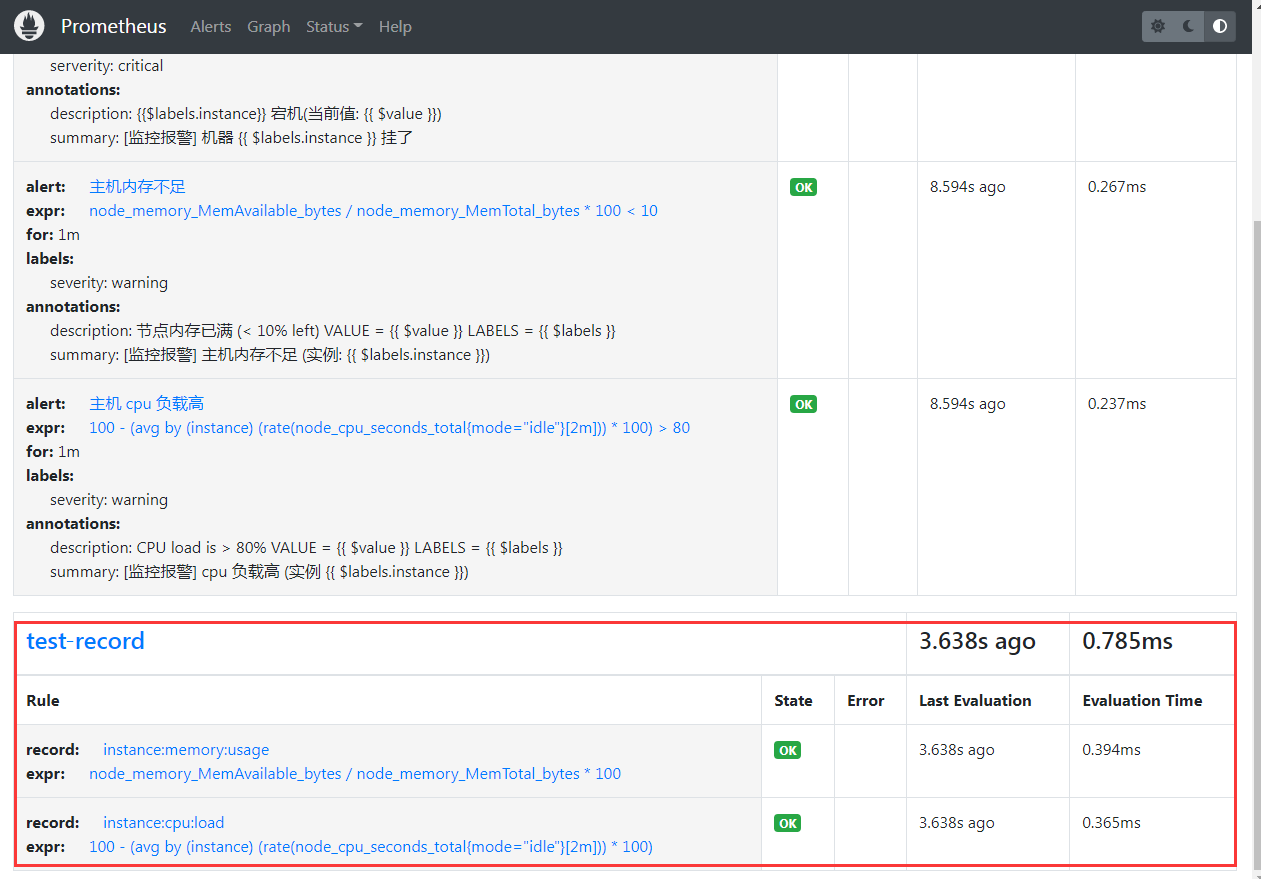
这样子一个记录规则文件就创建好了,注意几个细节
- 这个记录规则文件的这个组,我重新设置了评估时间为 10s (
interval: 10s), 如果不设置的话,就会读 prometheus.yml 设置的这个参数evaluation_interval: 15s, 这个就看具体的实际情况看是否吃默认配置 - 记录规则 的 expr 参数,他不需要跟 alert 的 expr 参数那样,得到的值是一个 Boolean 值,而是跟我们正常的指标的值一样
- 记录规则 的 指标名称,也就是 record 参数的值,一般是用
xxx:xxx:xxx的方式来定义,具有一定的语义化,跟我们正常 prometheus 采集的指标名称一样,只不过指标名称的连接符是_, 而记录规则的这种聚合指标为了跟正常采集的原始指标在写法上分开,所以一般采用:符号来分割
用法
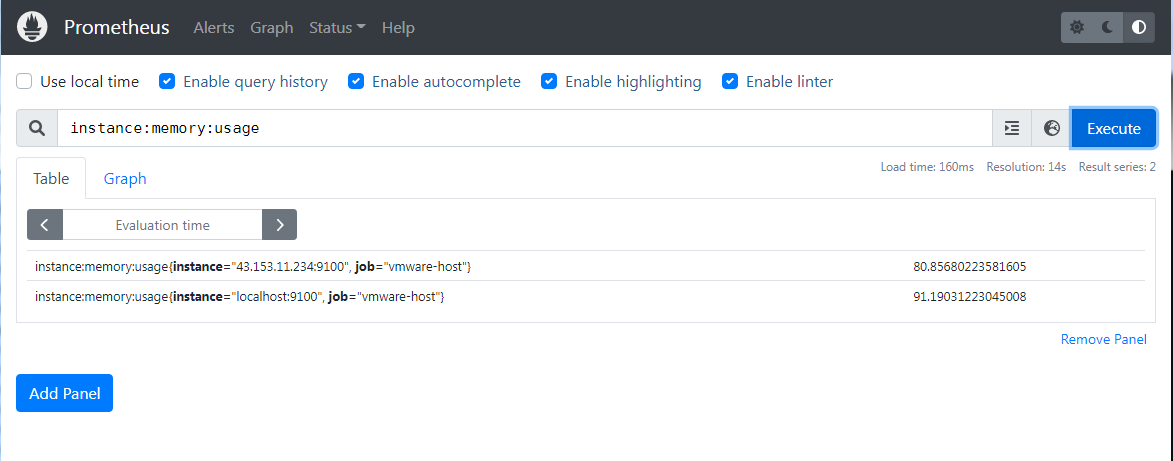
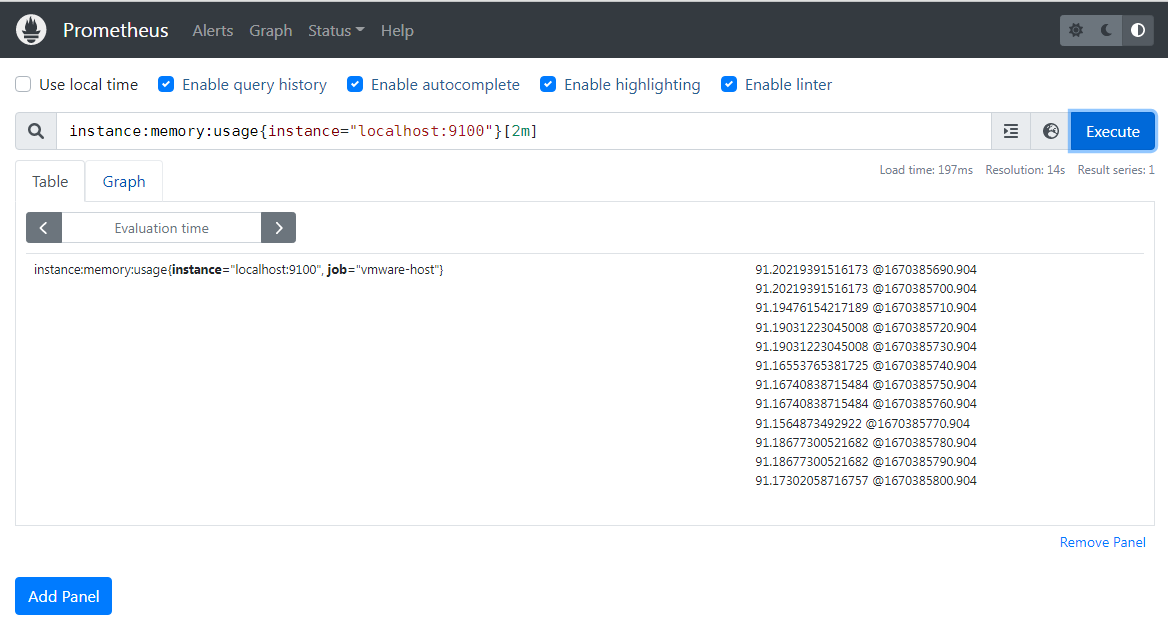
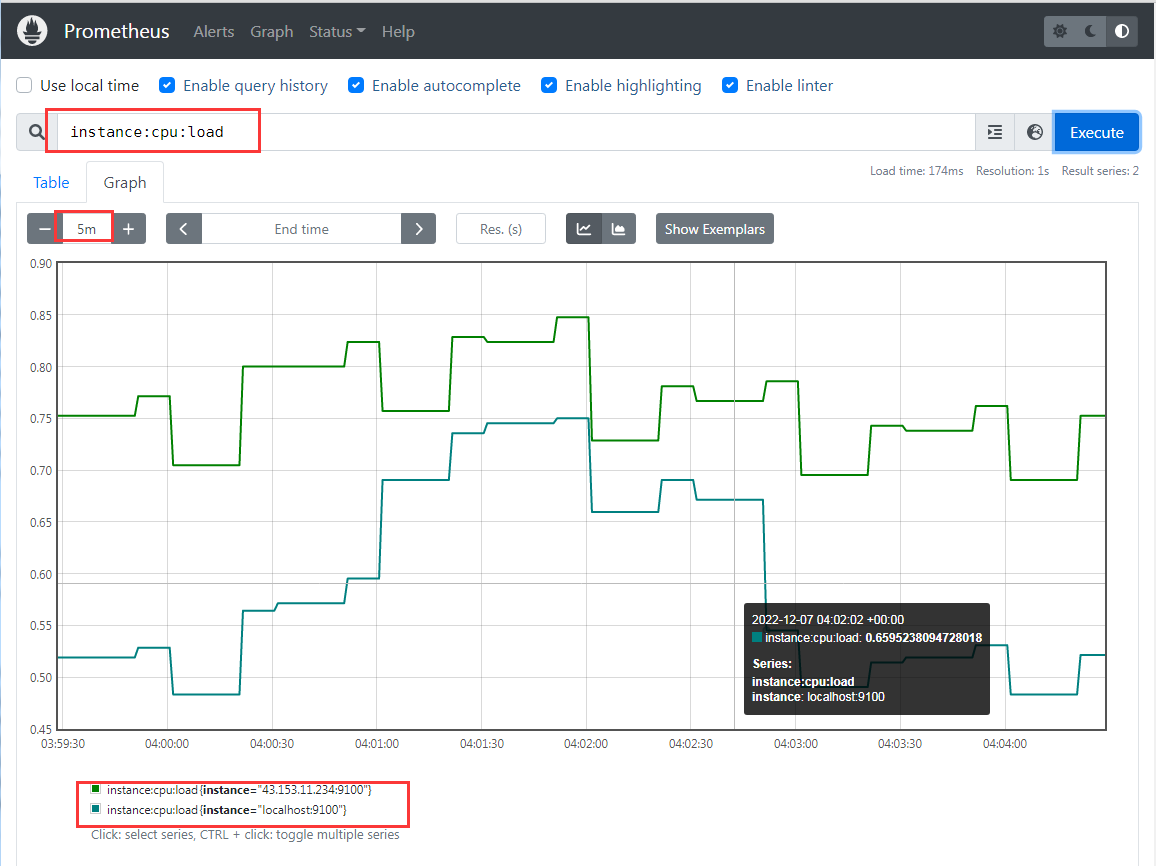
记录规则其实就是创建一个新的指标,只不过这个指标是由一个或者多个原生指标的相关计算得到的,但是用法上,他跟 prometheus 的原生指标没啥差别
比如我们可以在 prometheus 后台直接使用
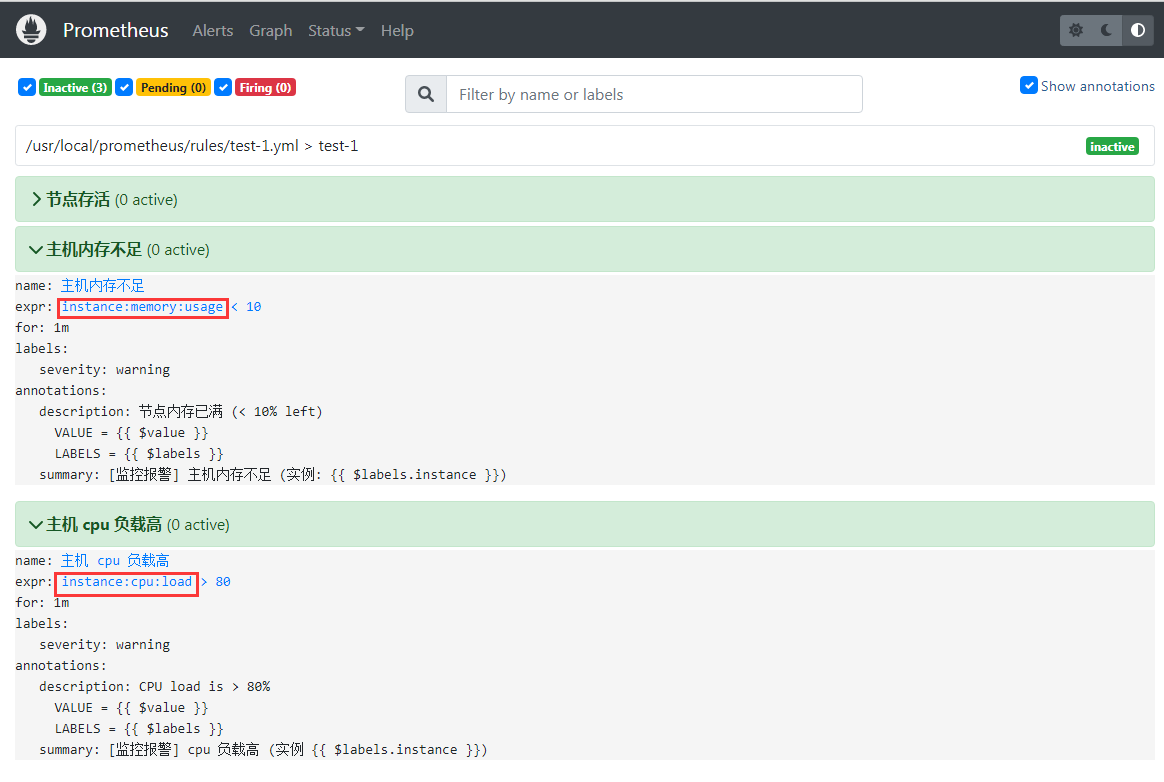
同时我们也可以修改我们的的警报邮件,将原先的1
2
3
4
5
6
7- alert: 主机内存不足
expr: node_memory_MemAvailable_bytes / node_memory_MemTotal_bytes * 100 < 10
...
- alert: 主机 cpu 负载高
expr: 100 - (avg by(instance) (rate(node_cpu_seconds_total{mode="idle"}[2m])) * 100) > 80
...
改成:1
2
3
4
5
6
7- alert: 主机内存不足
expr: instance:memory:usage < 10
...
- alert: 主机 cpu 负载高
expr: instance:cpu:load > 80
...
记录规则的命名
官方有针对记录规则推荐了最佳实践: 记录规则最佳实践
一般以这种形式命名 level:metric:operations. 其中 level 表示规则输出的聚合级别和标签, metric 是指标名称,operations 是应用于指标的操作行为列表
总结
我们可以通过创建记录规则来保存一些常见的 prometheus 计算表达式,并且将记录规则当做指标来进行查询。
参考资料: