前言
通过 基于 prometheus 打造监控报警后台 (4) - 使用 alertmanager 发送警报 我们已经能够在 prometheus 创建警报规则,并且使用 alertmanager 发送警报预警了。
但是 alertmanager 还有几个特性,并没有在上述文章讲述,本节继续延续上节的内容,讲一下 alertmanager 的几个概念。
1. 分组(Grouping)
Grouping 是把同类型的警报进行分组,合并多条警报到一个通知中。在生产环境中,特别是云环境下的业务之间密集耦合时,若出现多台 Instance 故障,可能会导致成千上百条警报触发。在这种情况下使用分组机制, 可以把这些被触发的警报合并为一个警报进行通知,从而避免瞬间突发性的接受大量警报通知,使得管理员无法对问题进行快速定位。
举个例子,比如我在 aws 的美西部署了 100 台服务器, 上面都部署了 node_exporter,然后突然有一天, aws 的美西服务商出现网络波动,导致 prometheus server 连接不到这 100 台服务器,这时候这 100 个节点就会全部触发告警, 瞬间往你的邮箱发送了 100 封邮件,直接给你造成邮件轰炸。
但是如果你有设置分组,将 100 台的主机的 up 检测都放到同一个分组内,那么这个 100 封告警就会合并成一条发送。
1.1 demo 1
事实上,我们之前的 alertmanager 配置的分组策略,就是按照标签 alertname 来分组的: alertmanager.yml1
2
3
4
5
6route:
group_by: ['alertname']
group_wait: 30s
group_interval: 5m
repeat_interval: 10m
receiver: default-receiver
而我们在 rules/test-1.yml 的配置的 alertname 就是 节点存活1
2
3rules:
- alert: 节点存活
expr: up{job="vmware-host"} == 0
所以只要是 job="vmware-host" 的节点,都是同一个组的,他们在 30s 的等待时间内(group_wait配置),如果都有触发警报,那么就会合在一起。
所以一旦出现两台节点都挂掉的情况下, 他们的警报信息就会合并成一封 (因为他们的 alertname 标签都是 节点存活)
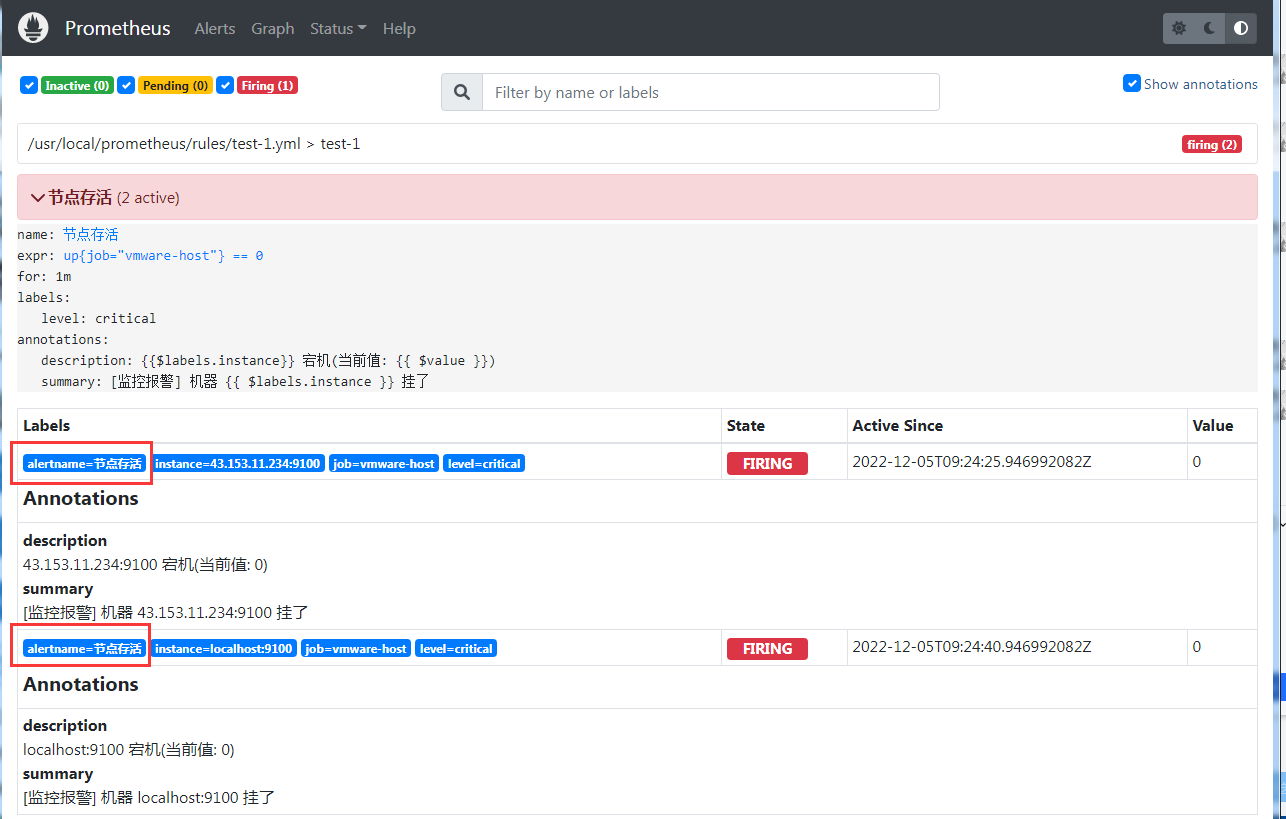
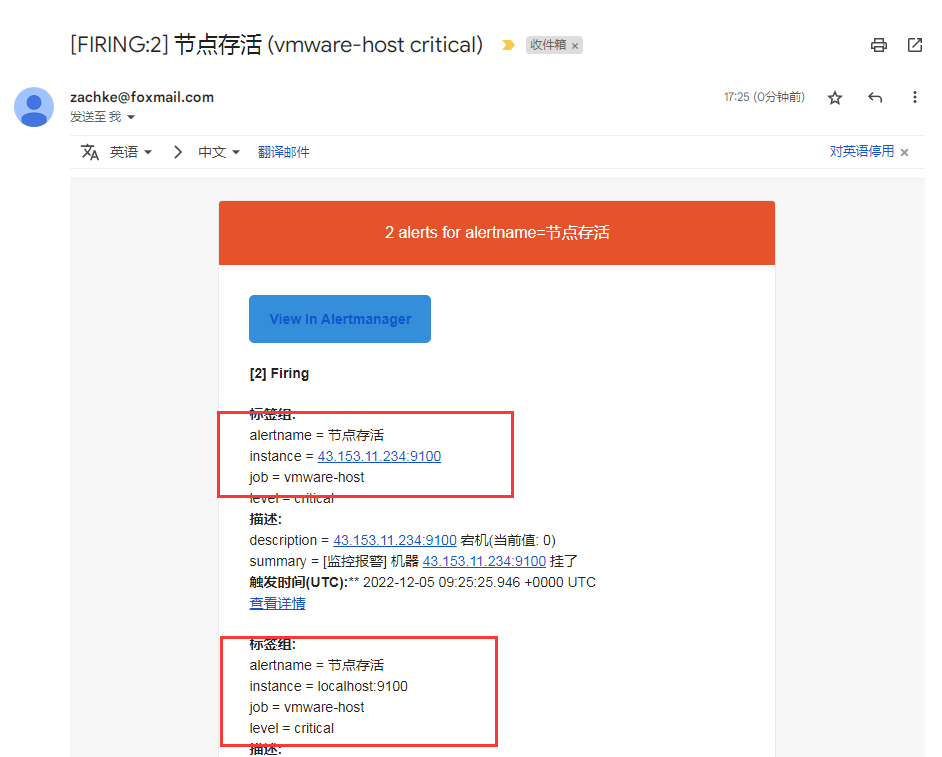
1.2 demo2
demo1 的 alertmanager 分组方式是按照 alertname 这个标签来分组,而这个标签是在生效 警报规则的时候,prometheus 的 指标追加进去的。 所以我们也可以用原先的指标的标签组来分组
为了方便测试,我这边再创建两个规则,用来监控主机的一些性能指标
一个是用来监控主机的内存不足预警(不足 10%),一个是监控主机的 cpu 负载(负载超过 80%),1
2
3
4# 内存不足 10%
node_memory_MemAvailable_bytes / node_memory_MemTotal_bytes * 100 < 10
# cpu 负载超过 80%
100 - (avg by(instance) (rate(node_cpu_seconds_total{mode="idle"}[2m])) * 100) > 80
但是测试机没有那么高的,所以条件反过来, 将 < 10 改成 > 10, 将 > 80 改成 < 80, 这样子就可以马上触发
其实就是在 test-1.yml 最下面增加这两串1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40# 修改 rule 规则文件
[root@VM-64-9-centos rules]# cat test-1.yml
# rules/test-1.yml
groups:
- name: test-1
rules:
- alert: 节点存活
expr: up{job="vmware-host"} == 0
for: 1m
labels:
serverity: critical
annotations:
summary: "[监控报警] 机器 {{ $labels.instance }} 挂了"
description: "{{$labels.instance}} 宕机(当前值: {{ $value }})"
- alert: 主机内存不足
expr: node_memory_MemAvailable_bytes / node_memory_MemTotal_bytes * 100 > 10
for: 1m
labels:
severity: warning
annotations:
summary: "[监控报警] 主机内存不足 (实例: {{ $labels.instance }})"
description: "节点内存已满 (< 10% left)\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
- alert: 主机 cpu 负载高
expr: 100 - (avg by(instance) (rate(node_cpu_seconds_total{mode="idle"}[2m])) * 100) < 80
for: 1m
labels:
severity: warning
annotations:
summary: "[监控报警] cpu 负载高 (实例 {{ $labels.instance }})"
description: "CPU load is > 80%\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
# 检验语法
[root@VM-64-9-centos rules]# ../promtool check rules test-1.yml
Checking test-1.yml
SUCCESS: 3 rules found
# 重刷生效
[root@VM-64-9-centos rules]# curl -X POST localhost:9090/-/reload
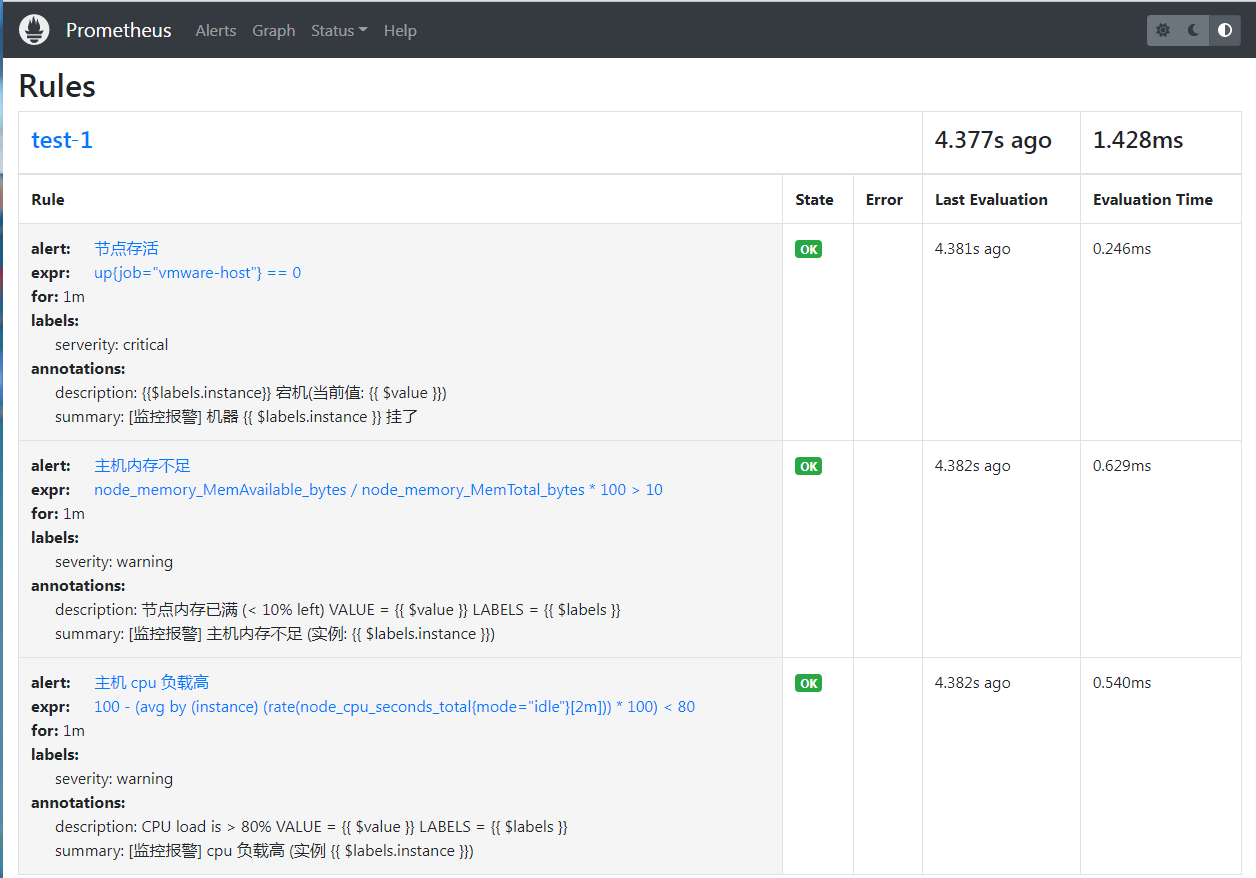
这时候就会触发警报,因为默认是按照 alertname 来分组的,所以就会分成两台警报 (之所以每一种有两条警报,是因为当前有两台主机都触发)

如果要将这两个警报合并成一台,就要改一下分组,改成用 severity="warning" 这个上述两个新增警报共有的标签来分组,所以 alertmanager.yml 要添加这个1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44[root@VM-64-9-centos alertmanager]# cat alertmanager.yml
global:
smtp_smarthost: 'smtp.qq.com:25'
smtp_from: 'z***e@foxmail.com'
smtp_auth_username: 'z***e@foxmail.com'
smtp_auth_password: 'ypgtxxxxxxxxxxxxx'
smtp_require_tls: false
templates:
- '/usr/local/prometheus/templates/mail.tmpl'
route:
group_by: ['alertname']
group_wait: 30s
group_interval: 5m
repeat_interval: 10m
receiver: default-receiver
# 子路由节点
routes:
- group_by: ["severity"]
matchers:
- severity="warning"
receivers:
- name: 'default-receiver'
email_configs:
- to: 'k****o@gmail.com'
send_resolved: true
headers:
subject: '{{ template "custom_mail_subject" . }}'
html: '{{ template "custom_mail_html" . }}'
webhook_configs:
- url: http://localhost:8070/dingtalk/webhook_1/send
send_resolved: true
[root@VM-64-9-centos alertmanager]# ./amtool check-config alertmanager.yml
Checking 'alertmanager.yml' SUCCESS
Found:
- global config
- route
- 0 inhibit rules
- 1 receivers
- 1 templates
SUCCESS
[root@VM-64-9-centos alertmanager]# curl -X POST localhost:9093/-/reload
其实就是加了一个子路由,来匹配 severity="warning", 并且警报的组别按 severity 标签排序1
2
3
4
5# 子路由节点
routes:
- group_by: ["severity"]
matchers:
- severity="warning"
这时候就可以看到 4 条警报合并成一起了 (因为有两台主机,所以会有 4 条)
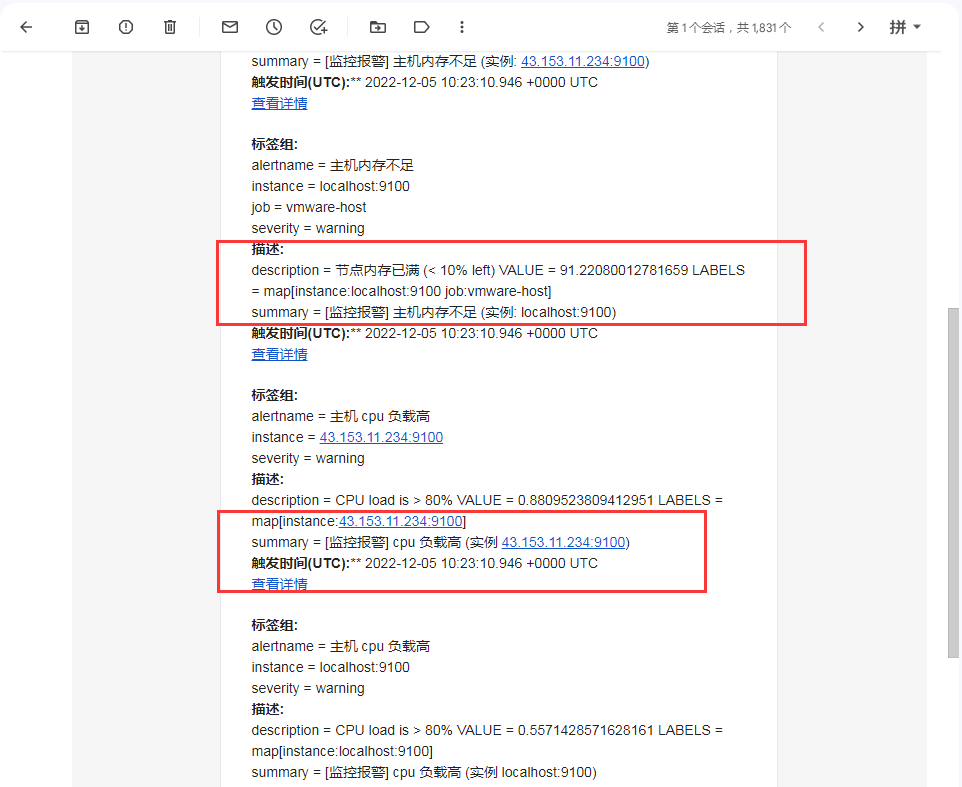
如果只想指定某一台, 可以设置多条匹配规则:1
2
3
4
5
6# 子路由节点
routes:
- group_by: ["severity"]
matchers:
- severity="warning"
- instance="localhost:9100"
这样子就只会指定 localhost 这一台的报警级别为 warning 的,才会合并成一条
2. 抑制(Inhibition)
抑制是一个概念,如果某些其他警报已经触发,则抑制某些警报的通知。
比如正在触发一个警报,通知整个集群无法访问。 alertmanager 可以配置为在触发该特定警报时将所有其他有关该集群的警报静音。这可以防止与实际问题无关的成百上千个触发警报的通知。
这个是需要配置在 alertmanager.yml 中的 inhibit_rules 节点, 具体规则如下: inhibit_rule1
2
3
4
5
6
7
8
9
10# 当前要判断被应用抑制规则的警报
target_matchers:
[ - <matcher> ... ]
# 已经存在的警报
source_matchers:
[ - <matcher> ... ]
# target 和 source 要存在相同的标签
[ equal: '[' <labelname>, ... ']' ]
当存在与另一组匹配器匹配的警报(源)时,禁止规则使匹配一组匹配器的警报(目标)静音。对于列表中的标签名称,目标和源警报必须具有相同的标签值equal。
从语义上讲,缺少标签和具有空值的标签是同一回事。因此,如果源警报和目标警报中都缺少 equal 中列出的所有标签名称,则将应用抑制规则。
举个例子,假设当我这一台节点挂的情况下,那么这一台节点报的其他的警报,都不要受理,也就是被 抑制住了,具体表现在当我这一台发生了 serverity="critical" 的警报的时候(比如节点挂掉),这时候其他发生的具有 severity="warning" 的警报(同一个实例)都将被抑制,不再触发(比如内存不足,cpu 过高)
因此在之前的基础上,我们调整了一下 alertmanager.yml, 去掉了刚才调整的分组子路由, 添加了 inhibit_rule 子节点1
2
3
4
5
6inhibit_rules:
- target_matchers:
- severity="warning"
source_matchers:
- severity="critical"
equal: ['instance']
也就是如果是同一个节点实例服务,如果已经存在 severity="critical" 的警报,那么 severity="warning" 就会被抑制住,不会发送通知
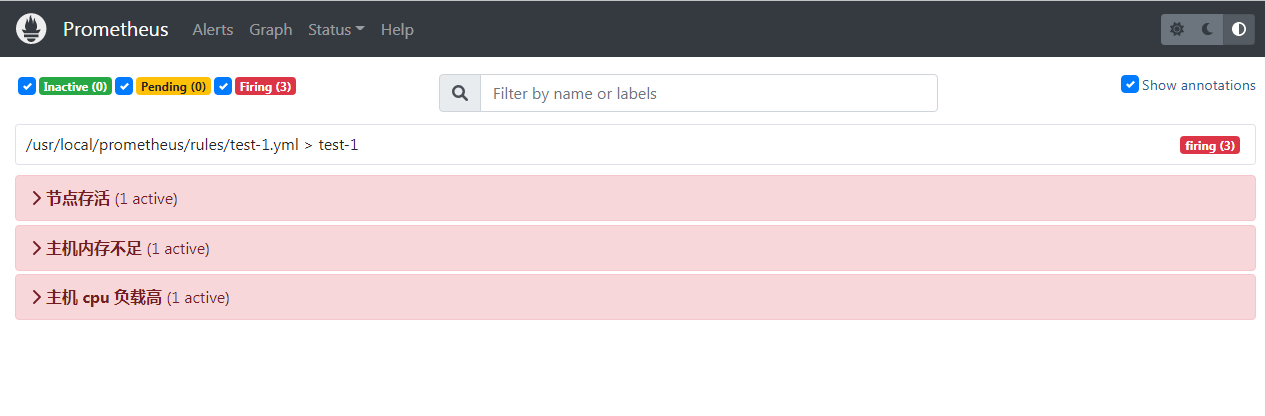
所以可以看到虽然 3 个警报都触发了,但是只收到了 节点存活 的 mail 通知, 另外两家就没有收到,因为被抑制了
下图只显示另一台主机 234 的 cpu 和 内存的警报,没有 localhost 这一台的,因为被抑制了

然后当我将 node 的节点重新启动的时候,这时候就可以收到这两封的警报了
3. 静默(Silences)
Silences 是一种简单的方法,可以在给定时间内使警报静音。
沉默是基于匹配器配置的,就像路由树一样。检查传入警报是否与活动静默的所有相等或正则表达式匹配器匹配。一旦匹配,就不会针对该警报发送任何通知。
这个其实很好理解,比如我们有个业务要维护,比如数据库升级,那么关于数据库的警报一定会触发,所以我们可以设置一个时间段再发送警告通知。
设置 Sliences 有两种方式:
- 通过 alertmanager 的 Web 界面设置
- 通过 amtool 工具在命令行进行设置
3.1 web ui 方式
比如我们可以在 alertmanager 后台添加一条静默规则
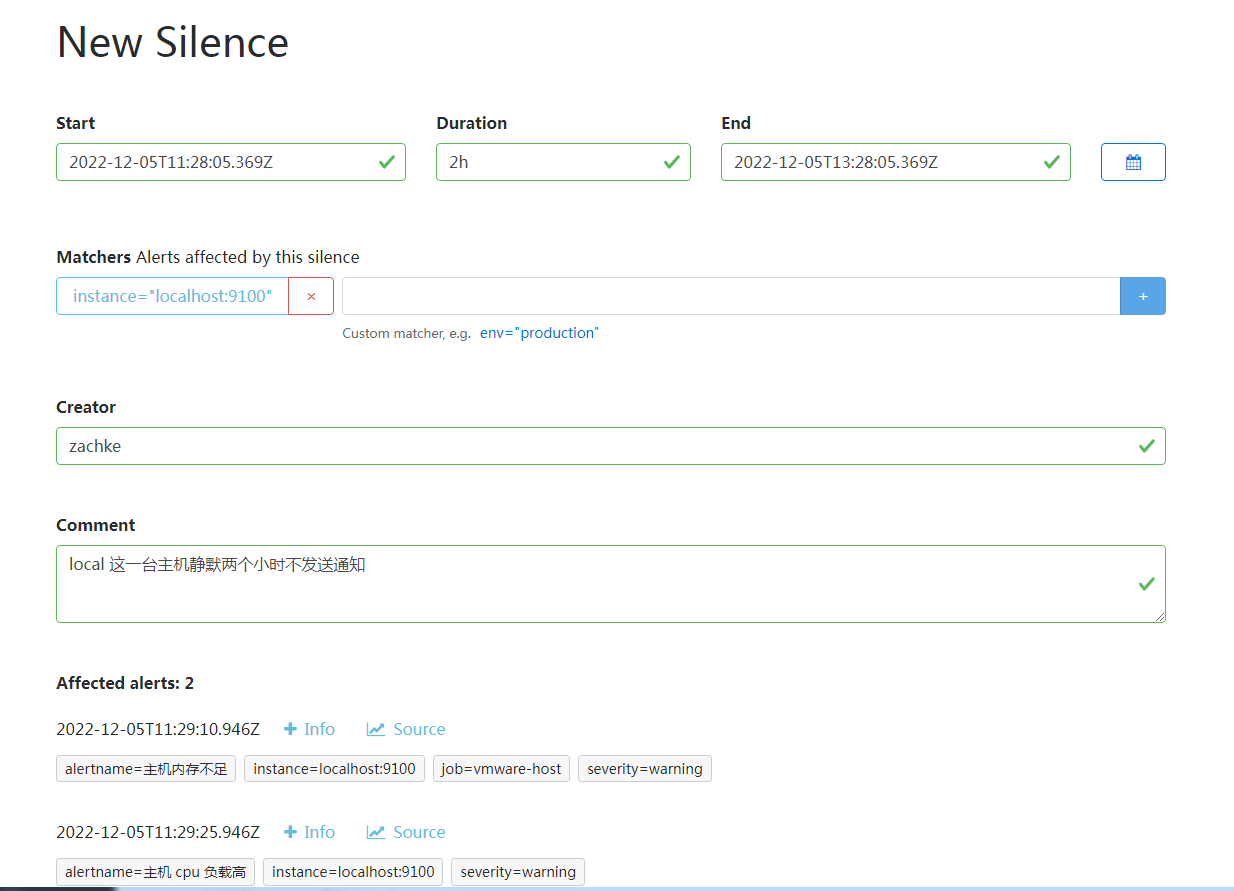
创建完之后,可以点击查看当前是否有警报会影响到,可以看到,当创建这一台静默规则的时候,现在正在触发的这两个警报,将会马上生效
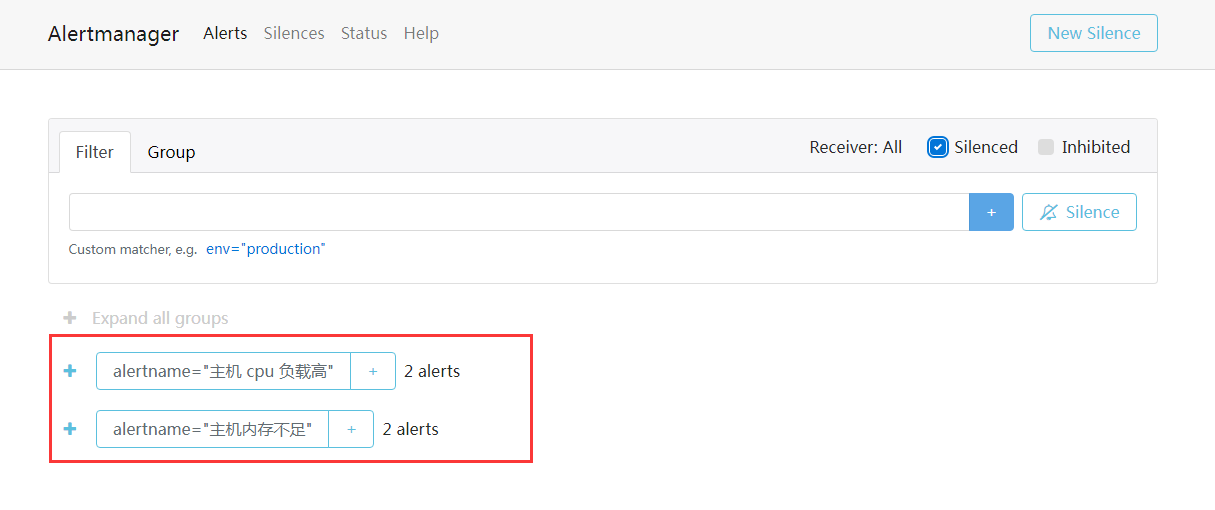
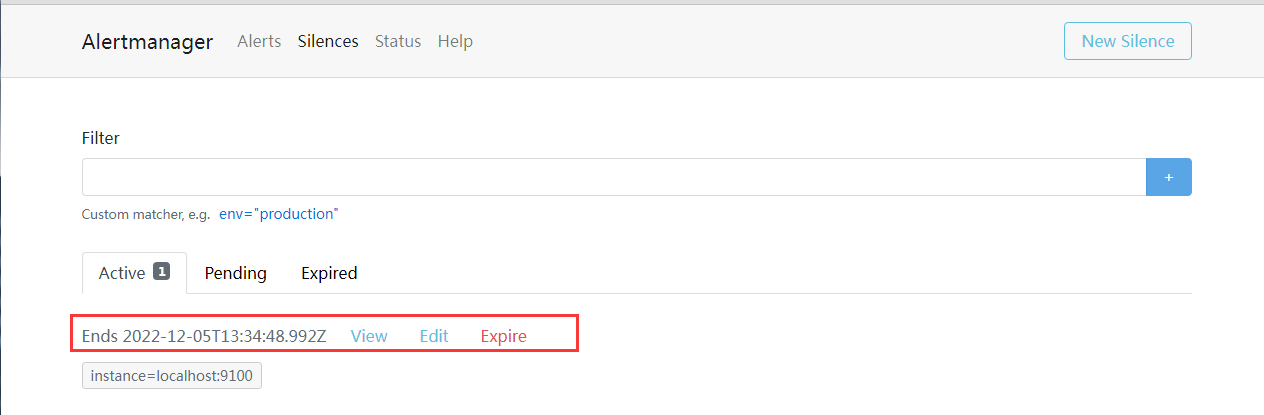
也就是接下来的这两个小时之内,这两个警报将不会再触发警告发送行为。 可以看到只收到 234 这一台的警报,不会再收到 localhost 这一台的警报了
这边还有一个 Expire 按钮,点击可以让这一条直接过期,可以用来模拟时间到期的情况
3.2 amtool 方式
关于使用 amtool 这个命令行来创建和查看静默(Sliences), 可以看: amtool1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26# 这个配置文件要先创建,指定具体的实例地址即可
[root@VM-64-9-centos alertmanager]# cat /etc/amtool/config.yml
# Define the path that `amtool` can find your `alertmanager` instance
alertmanager.url: "http://localhost:9093"
# Override the default author. (unset defaults to your username)
# author: me@example.com
#
# # Force amtool to give you an error if you don't include a comment on a silence
# comment_required: true
#
# # Set a default output format. (unset defaults to simple)
# output: extended
#
# # Set a default receiver
# receiver: team-X-pager
# 查询当前未过期的静默
[root@VM-64-9-centos alertmanager]# ./amtool silence query
ID Matchers Ends At Created By Comment
86a0e7e6-ccd9-49e3-b921-1879cbda4183 instance="localhost:9100" 2022-12-06 14:10:16 UTC zachke 1
# 将某一条静默规则设置为过期
[root@VM-64-9-centos alertmanager]# ./amtool silence expire 86a0e7e6-ccd9-49e3-b921-1879cbda4183
[root@VM-64-9-centos alertmanager]# ./amtool silence query
ID Matchers Ends At Created By Comment
更多的警报规则
其实要写好警报规则,尤其是一些现成的 exporter 的导出器,其实不仅仅是要熟悉他们抛送的指标含义,同时还要用好 promql 语法。
所以其实有一个站点就是: 很棒的普罗米修斯警报-报警规则集合
这个是一个非常棒的站点,上面列举上绝大多数我们日常用的服务的对应的警报规则, 直接拿过来用, 上述关于 node_exporter 的两条警报(内存和cpu)就是从这个站点摘抄的规则。
高可用
alertmanager 支持配置以创建集群以实现高可用性。这可以使用 –cluster-* 标志进行配置。
这个其实并不复杂,因为重要的是不要在 prometheus 和它的 alertmanagers 之间负载均衡流量,而是将 prometheus 指向所有 alertmanagers 的列表。 这样子就算有其他挂掉了,只要还有一台 alive, 那么就可以正常工作。
同理,为了提升 prometheus 的服务可靠性,我们会部署两个或多个的 prometheus 服务,两个 prometheus 具有相同的配置(Job配、告警规则、等),当其中一个 Down 掉了以后,可以保证 prometheus 持续可用。
alertmanager 自带警报分组机制,即使不同的 prometheus 分别发送相同的警报给 alertmanager,alertmanager 也会自动把这些警报合并处理。
关于 alertmanager 的高可用实践,后面可以单独搞个小节来讲。
总结
本节通过简单的讲述了一下 alertmanager 的 三个特性,来更近一步的强化对 alertmanager 的理解。
下一节我们将 prometheus 的另一种规则 – 记录规则
参考资料: