前言
之前我们有初步使用了 Jaeger 作为分布式链路追踪: 使用 jaeger 给你的微服务进行分布式链路追踪, 但是用的是仅供测试的 Jaeger All-in-one 一体包, 他的存储中心是直接存放在内存的。 所以用到生产环境肯定是不行的。
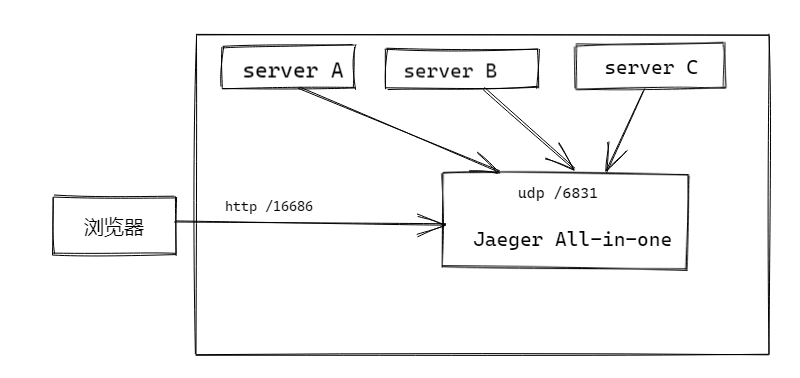
所以生产环境我们要单独安装以下组件
- Jaeger-Agent
- Jaeger-Collector
- Backend storage (Elasticsearch)
- Jaeger-Query (UI)
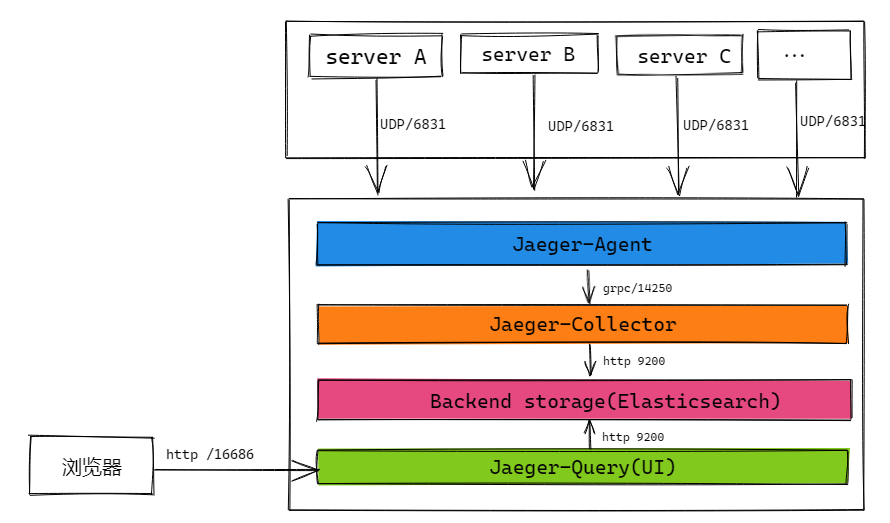
其他组件都一样,唯一不一样的就是我们将后端存储换成 Elasticsearch 来做存储
dockerfile 安装
看似好像要装很多东西,但是其实我们用 docker 来安装的话,只要写一个 docker-compose.yml 就可以了:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64version: "3"
services:
# 根据 https://www.jianshu.com/p/ffc597bb4ce8
# 即便设置了依赖关系, 让 es 先于其他容器启动,也会因为 es 容器启动成功但 es 服务本身初始化过慢问题导致 collector 和 query 在这段期间内连不上 es 而挂掉(agent不会挂,只是连不上collector)
# 解决方式:把 collector, agent, query 的重启策略改为 on-failure。 等 es 初始化成功后, collector,agent,query 也会在多次重启后趋于稳定
es:
image: "elasticsearch:7.10.1"
ports:
- "9200:9200"
- "9300:9300"
environment:
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
- "discovery.type=single-node"
volumes:
- "/data/docker/es/data:/usr/share/elasticsearch/data"
kibana:
image: "kibana:7.10.1"
ports:
- "5601:5601"
environment:
ELASTICSEARCH_HOSTS: http://es:9200
jaeger-agent:
image: "jaegertracing/jaeger-agent"
ports:
- "5775:5775/udp"
- "6831:6831/udp"
- "6832:6832/udp"
- "5778:5778"
command: ["--reporter.grpc.host-port=jaeger-collector:14250"]
restart: on-failure
depends_on:
- jaeger-collector
jaeger-collector:
image: "jaegertracing/jaeger-collector"
ports:
- "14269"
- "14268:14268"
- "14250"
- "9411:9411"
environment:
- "SPAN_STORAGE_TYPE=elasticsearch"
- "ES_SERVER_URLS=http://es:9200"
# tags 也作为field,便于在 es 中进行聚合分析时根据 tag 分析
- "ES_TAGS_AS_FIELDS_ALL=true"
depends_on:
- es
restart: on-failure
jaeger-query:
image: "jaegertracing/jaeger-query"
ports:
- "16686:16686"
- "16687"
environment:
- "SPAN_STORAGE_TYPE=elasticsearch"
- "ES_SERVER_URLS=http://es:9200"
# 根据 https://github.com/jaegertracing/jaeger/issues/2083
# jaeger query 默认会把自身的 span 抛给 agent ,所以也要配置 agent 变量
- "JAEGER_AGENT_HOST=jaeger-collector"
- "JAEGER_AGENT_PORT=6381"
restart: on-failure
depends_on:
- jaeger-agent
- jaeger-collector
- es
值得注意的是,我们上面还安装了 kibana 用于 elasticsearch 的前端数据查询和查看。
安装完之后,就可以看到:1
2
3
4
5
6
7[kbz@VM-16-47-centos ~]$ sudo docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
1d2154007e2a jaegertracing/jaeger-query "/go/bin/query-linux" 2 days ago Up 2 days 0.0.0.0:16686->16686/tcp, 0.0.0.0:49183->16687/tcp jaeger_jaeger-query_1
fa2fb6738009 jaegertracing/jaeger-agent "/go/bin/agent-linux…" 2 days ago Up 2 days 0.0.0.0:5775->5775/udp, 0.0.0.0:6831-6832->6831-6832/udp, 0.0.0.0:5778->5778/tcp jaeger_jaeger-agent_1
bf82d83818e1 jaegertracing/jaeger-collector "/go/bin/collector-l…" 2 days ago Up 2 days 0.0.0.0:9411->9411/tcp, 0.0.0.0:14268->14268/tcp, 0.0.0.0:49185->14250/tcp, 0.0.0.0:49184->14269/tcp jaeger_jaeger-collector_1
b5e0fc2f077a elasticsearch:7.10.1 "/tini -- /usr/local…" 2 days ago Up 6 hours 0.0.0.0:9200->9200/tcp, 0.0.0.0:9300->9300/tcp jaeger_es_1
f91189f5990b kibana:7.10.1 "/usr/local/bin/dumb…" 2 days ago Up 2 days 0.0.0.0:5601->5601/tcp jaeger_kibana_1
这样子就安装完了。 这边有个需要注意的是,jaeger-agent 这个服务我现在是跟 collector 和 storage 装在一起。 所以服务是在抛送数据到 agent 的时候,还是抛送到这一台服务器来的。 但是正常的生产环境,为了让服务更快的抛送,应该将 agent 装在对应服务所在的服务器上(每个服务器都安装一个,然后服务来初始化 agent 连接的时候,统一用 127.0.0.1:6831 来连接)。这样子抛送的速度会更快。 每一个服务器都要安装一个 agent 服务,他会定时跟 collector 服务进行通信和抛送数据。
其他都一样。 所以接下来我们来试验一下, jaeger 的数据是以什么样的方式存储在 elasticsearch 中。 并且要怎么用 elasticsearch 来做聚合计算。
安装 elasticsearch-head
一般情况下,我们都会通过一个可视化的工具来查看ES的运行状态和数据。这个工具我们一般选择head 。但 ElasticSearch-head 依赖于node.js。 所以我们要先安装一个 nodejs, 下载地址, 安装完之后,还要全局安装 grunt (依赖 grunt 执行):1
npm install -g grunt-cli
都安装好之后,直接到 head 的 github 地址 执行以下步骤:1
2
3
4
5git clone git://github.com/mobz/elasticsearch-head.git
cd elasticsearch-head
npm install
npm run start
open http://localhost:9100/
当然,他也有提供 docker file 可以用 docker 来安装。 当服务跑起来之后, 如果是访问不同域的 es 服务,那么还要在 es 的 yaml 配置文件,加上跨域允许, 就是在 elasticsearch.yml 最下面补上这两句:1
2http.cors.enabled: true
http.cors.allow-origin: "*"
http.cors.enabled 开启跨域访问支持,默认为false
http.cors.allow-origin 跨域访问允许的域名地址,支持用正则,我这里就偷偷懒,直接全部
最后重启 es 服务,这样子就打开本地的 http://localhost:9100/, 并且在连接的输入框输入 es 实例的 ip 和 端口,就可以看到了:
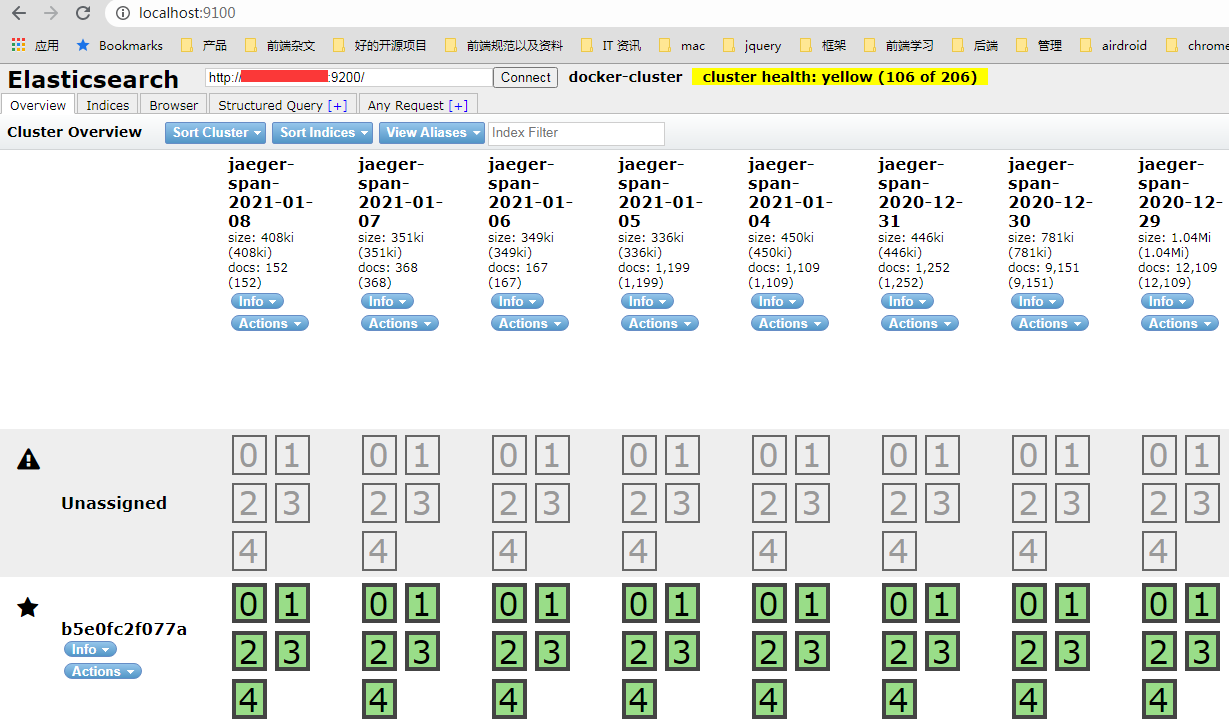
他还支持在上面执行查询指令。相当于一个数据库的查询客户端。
结合 es 的数据做聚合计算
用 jaeger 通过 tag 去检索想要的内部调用链过程很方便。 但是做聚合查询就不好做,尤其是统计成功率就更难做了。
举个例子,简单的来说,我有一个服务是在前端的页面,点击某一个设备,然后等一会儿出现这个设备的界面截图, 看似很简单,但是实际上涉及到内部微服务不少,具体如下:
- 前端点击刷新接口请求服务器
- 服务器发送 push 到设备端
- 设备端将当前屏幕截图,并且上传到云存储,最后将截图的 url 传给服务端
- 服务端再发送 push,将截图的 url传给前端
- 前端收到 push,获取 push 信息的 url,然后显示设备截图,同时请求一个回执接口,告诉服务端已经收到
在这个过程中, 第一步的时候, 服务端就会去初始化 traceID, 然后发送 push 的时候,就会将这个 traceID 带过去给设备端, 然后设备端在上传截图成功,将截图返回给服务端的时候,也会将这个 traceID 带回服务端。 前端收到服务端 push 的时候,也会获取 push 信息里面的 traceID, 并且调用回执接口,将 traceID 传回来
这样子这些流程中都会有一个 traceID 可以串起来, 因为我们很容易的可以通过这个 traceID 查看整个 内部调用链的 流程。
但是这种方式是很难做聚合统计的,比如我想统计几个数据:
- 每天进行这个流程的最终的成功率是多少?
- 所有用户(通过 tag 标记)近一个月的成功率是多少?
- 所有设备(通过 tag 标记)近一个月的成功率是多少? 如果是失败的话,那么卡在各个环境的比例大概是多少?
从上面的那三个聚合统计来看,我们是没办法在 jaeger 的前端 ui 页面得到这些数据。 虽然 es 我们有接入 kibana, 但是 kibana 只能基于 es 的 index 的一些 field 字段做一些简单的聚合统计和过滤统计,太复杂的聚合,包括多个子查询的嵌套,这个是没办法实现的。 尤其是涉及到 tag 的聚合统计。
举个例子
接下来我们就结合 es 的数据,看看如果要做聚合统计,那得有多麻烦? 假设我要在 es 中,找到设备 id 为 80b6b23496b0ba538b3e2a02b09823d4 在 2021-01-04 这一天的所有记录
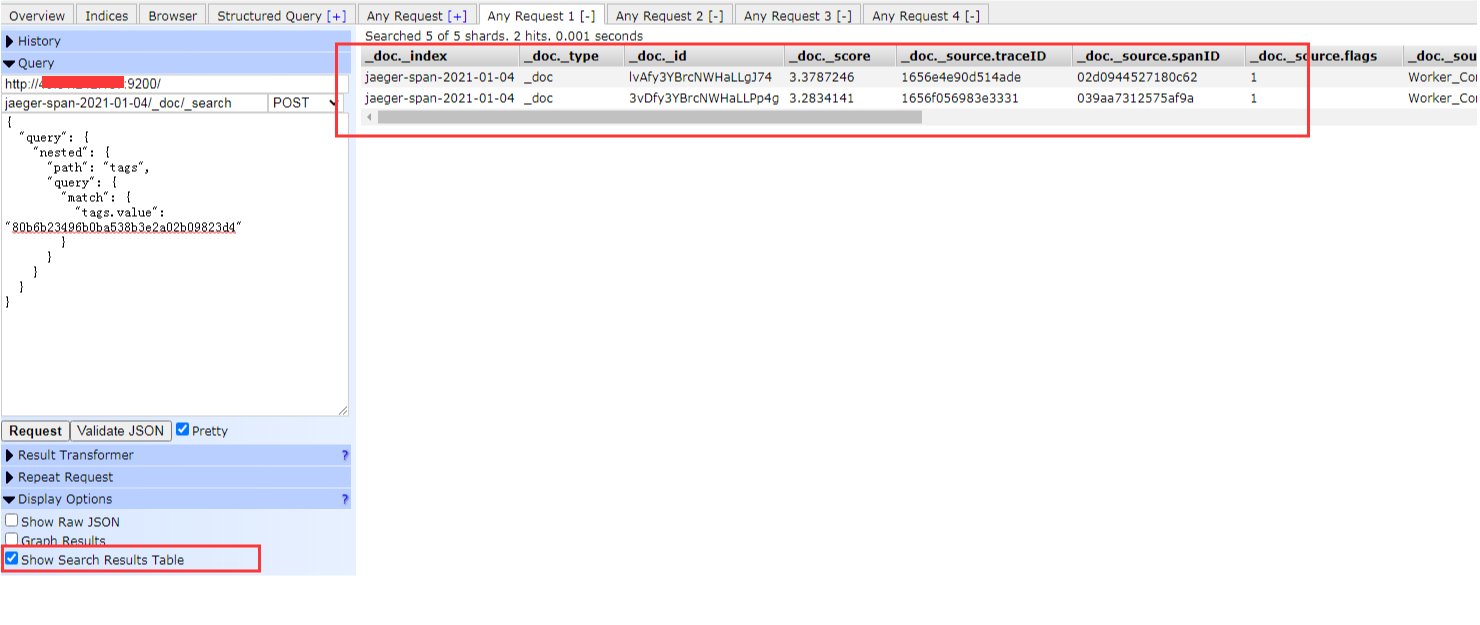
可以看到这一天有 2 条记录,分别属于两个 traceID, 接下来我们就可以将这个 traceID 去查询,就可以得到这一次追踪的最后花费的时间, 以这个 1656e4e90d514ade 为例
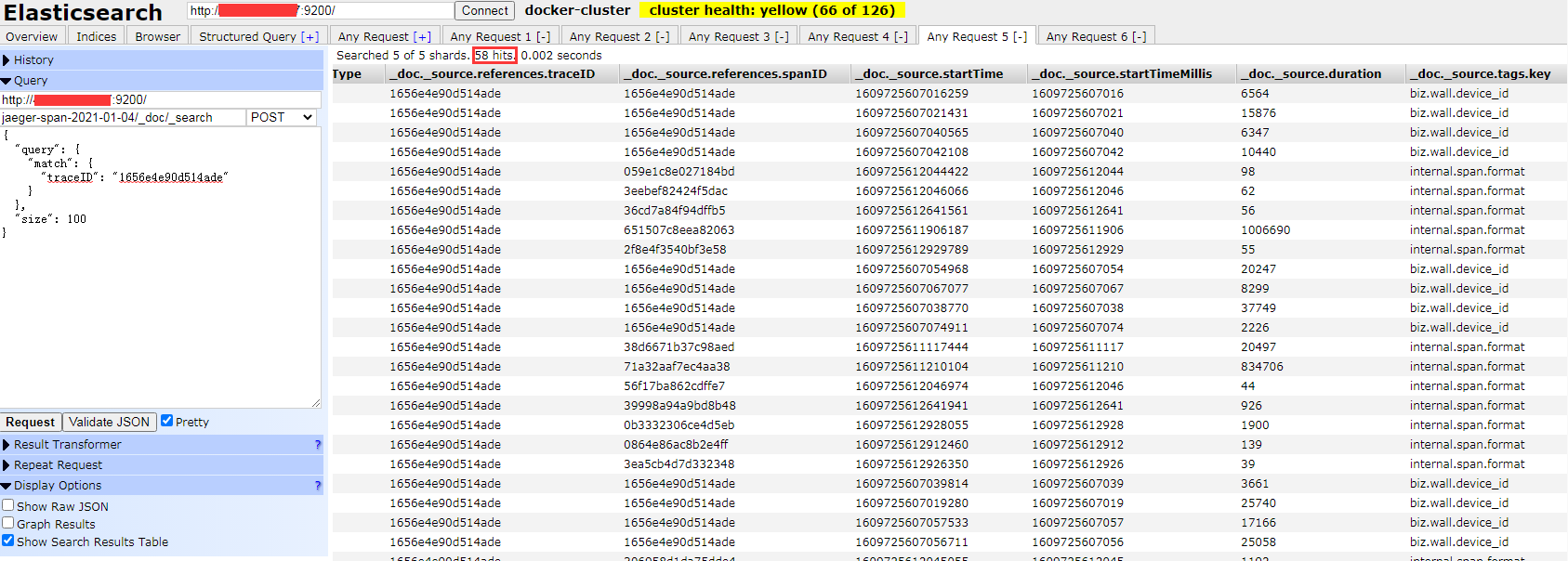
可以看到这个 traceID, 有 58 个 hit, 接下来我们结合 jaeger 后台查看是否结果一致
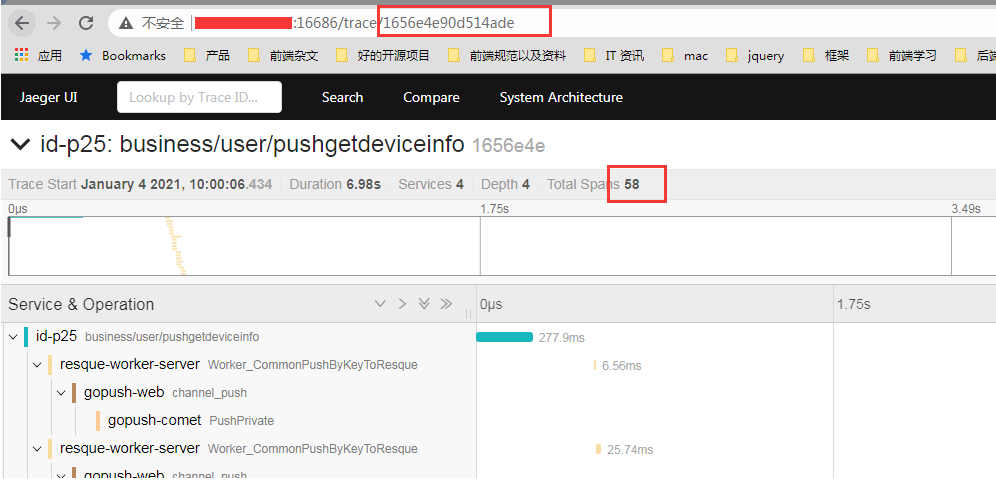
可以看到都是 58 个 hit 结果。说明是一致的。而且一个 traceID 会包含多个设备 id,这个是因为一次刷新操作,可能会进行批量的推送不同设备,所以在某些流程,程序打 tag 的时候,就会打多个 tag, 因此我在查询的时候, 还要再加上设备 id 的查询条件
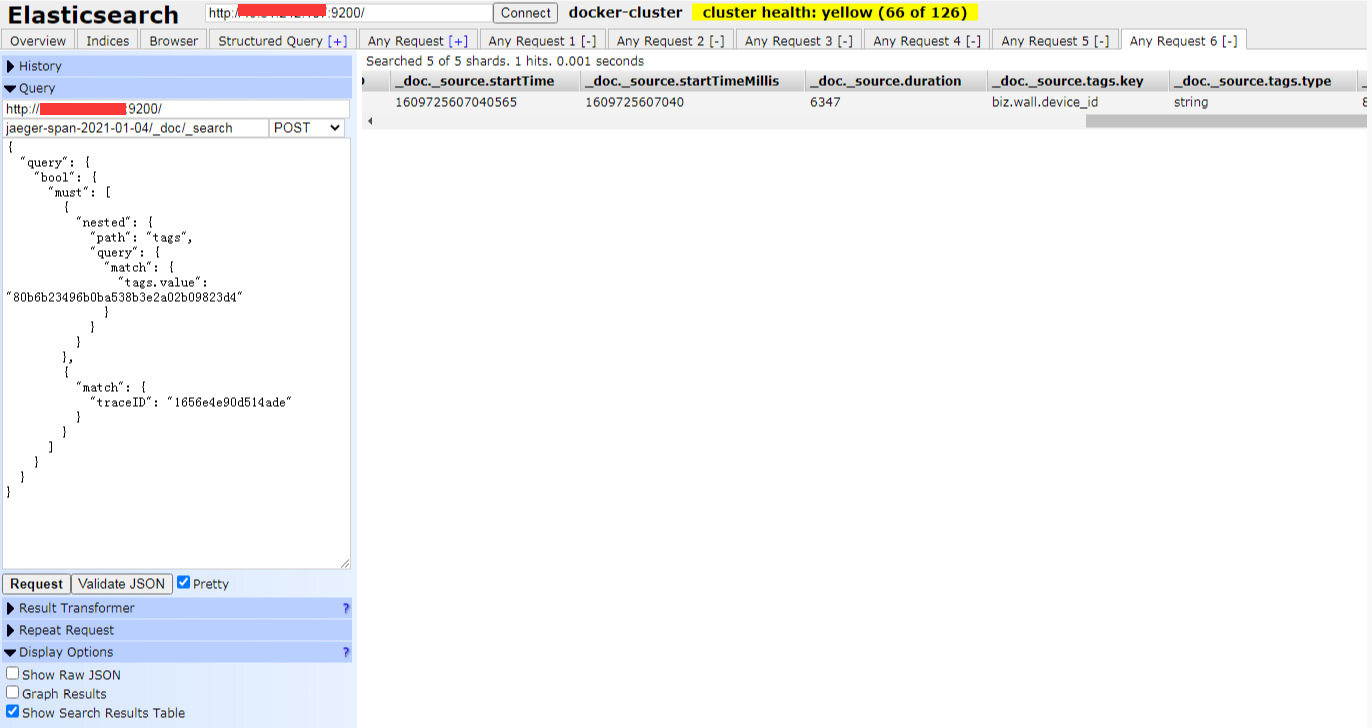
这样子就过滤掉只剩下这一条了。也就是这个 traceID 只属于这个设备 id 的 span。 而且查看了一下 duration 的值是 6347 微秒,也就是 6.347 ms,这个也是可以在 jaeger 后台查看到这一条 span 的数据:
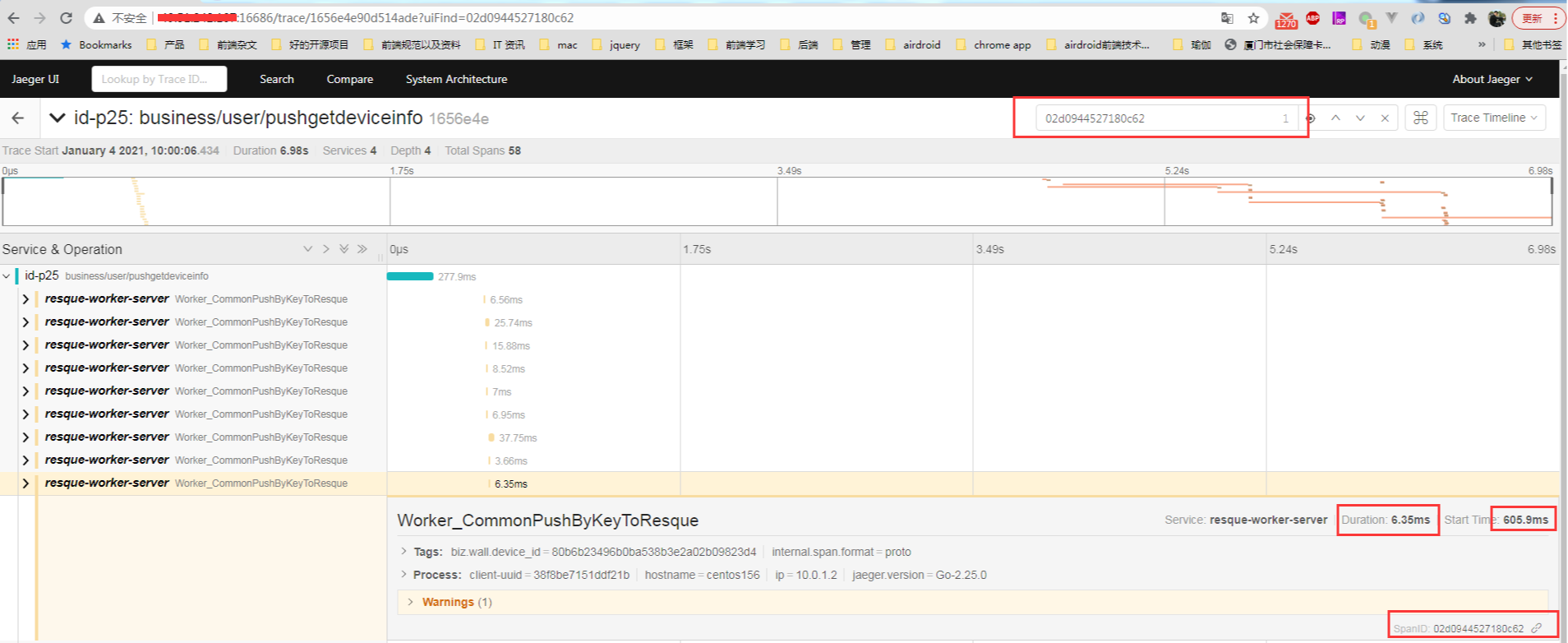
到了这个环节,那么接下来要得到这个设备 id 在这次的 tracing 的时间总消耗,就得根据这个 span 的 parent span 一层一层去找。然后再将第一层的 root span 的开始时间得到, 然后再得到最后一层的 span 的开始时间和持续时间相加作为结束时间(因为中间会有一些没有统计的空白流程,比如设备端的上传时间,所以不能直接将 所有 span 的 duration 相加), 然后两个相减就可以得到这一台设备的这个流程的总耗时。
可以看到我只是想要知道某一台设备在某次操作的总时长, 涉及到的查询就有好几个步骤,如果更复杂一点,要统计某一段时间的成功率的话,那么简直是噩梦, 估计只能用脚本来写了。
所以可以看到如果用 es 的话, 想要得到复杂的聚合查询, 尤其是子查询多层嵌套的话, 确实会比较不友好。
总结
如果只是单纯的想用 jaeger 在做内部调用链的针对具体点的查询追踪的话, 用 es 是没有问题的。 但是如果涉及到整个环节的聚合查询的话, es 的语法还是不够友好。 是不是有其他更好的替代品,有的,就是 ClickHouse, 他的 sql 语法跟 mysql 非常像, 因此做聚合查询的时候, 也会比较友好。 不过 jaeger 还不支持直接用 ClickHouse 直接做后端存储 (ClickHouse as a storage backend)。 所以还得加上其他处理才行。