前言
之前讲过的两种方式:
其实已经可以很好的覆盖了生产环境中产生的临时故障情况,并有助于分析流量和错误情况。 但是仅仅这样子还不够。要做到更全面的预警可观测。除了要第一时间处理生产环境中当前产生的错误信息之外。
还需要对业务数据的表现情况也要造成可观测,比如常见的:
- 登录情况,10 分钟成功率预警, 一小时成功率预警,每天成功率预警
- 支付情况,10 分钟支付成功率和数量,每天支付总数
- 核心功能的使用情况监控,比如用于短信验证码的成功率,Google验证码的成功率,两步验证的成功率,远程连接的成功率,用户核心模块的使用成功率等等
这些业务数据,一般服务端都会将使用记录写入数据库,后面再用相关平台来进行预警,比如 cacti,zabbix 等运维平台就是通过写 python 脚本去定时查下数据库对应的数据然后来建立预警值。比如之前常用的在 zabbix 写的预警脚本就是1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33#!/usr/bin/env python
#-*-coding:utf-8-*-
import time,sys
import datetime
from dateutil.relativedelta import relativedelta
sys.path.append('/data/server/wwwroot/cacti-0.8.8h/scripts/')
from db_help import get_conT
from config import db8_host,db8_host_master,db8
cur_mon = time.strftime("%Y%m",time.localtime())
last_mon = (datetime.datetime.now() + relativedelta(months=-1)).strftime("%Y%m")
sql1="""select count(status) num
from (
select status
from cast_sts.%s
where create_time>=DATE_SUB(now(),INTERVAL 30 MINUTE) and create_time < now()
order by id desc
limit 1000
) as a
group by status having status = 0"""
def itimequery(tb):
sdb = get_conT(db8,db8_host,db8_host_master)
dd1=sdb.get(sql1 % (tb))
sdb.close()
print "%s" % (dd1['num'])
if __name__ == "__main__":
itimequery('cast_login_logs')
这样子虽然可以做到对业务数据的预警,但是很不方便,而且效率很低,如果我一下子要添加几十个的预警的话,而且不同时段还不一样,设置的预警级别也不一样。
比如同样是登录成功率,我可能就要 10 分钟,1小时,6小时,每天的成功率的报表和预警,这时候脚本就要写的很复杂,而且很不通用。
而且现在既然都要将数据的监控和预警都放在 Prometheus 上了,那么肯定就尽可能都用 Prometheus + grafana 这个平台来实现了。
处理方式
因为业务数据都是在数据库中,所以要查询的话,要写程序查询,然后抛送到 pushgateway,然后 Prometheus 再到 pushgateway 采集。 所有应该是有 3 个步骤:
- 写一个程序跑计划任务去查库,采集数据,然后抛送到 pushgateway 程序
- Prometheus 采集 pushgateway 数据
- grafana 创建 dashboard 和 预警
关于 pushgateway 的安装和使用,直接看我之前写的: 基于 prometheus 打造监控报警后台 (9) - 借助 pushgateway 主动 push 数据, 这边不再赘述。
主要是第一点的计划任务程序,要满足几个要求:
- 容易添加和修改,想加几个业务指标,那么可以直接在配置文件里面写 sql 以及计划任务时间,写完直接生效,不需要重启程序
- 支持分库分表,尤其是有一些月表,每个月的表名的后缀都不一样,我不需要每个月都要改我的 sql
实操方式
这边程序我用的是 golang 来写,也不贴代码,主要讲思路,最多贴一些核心代码
1. 指标配置支持热更新生效
这个程序,有两个配置文件:
conf.toml这个是冷启动文件,修改之后要重启程序才会生效,比如存放 pushgateway 和 相关的数据库配置:1
2
3
4
5
6
7
8
9
10
11# pushgateway 后端端点
Pushgateway = "http://43.xx.xx.96:9091/"
#################################################################################
# 关系数据库配置,连接字符串格式由对应驱动定义。
# mysql的格式为: <user>:<password>@<protocal>(<host>:<port>)/<database>[?<param>]
#################################################################################
[db]
DwTxSts = "kbz:xxx@tcp(xxx:9030)/tx_foo_analysis"
TxSts = "kbz:xxx@tcp(xxx:5022)/foo_sts"
TxMain = "kbz:xxx@tcp(xxx:5017)/foo_main"
这边是可以配置多个数据库的,因为不同的业务查询会用到不同的数据库,比如生产环境的主业务库,统计库,或者数仓等,就是在这边配置
conf_hot.toml这个是热更新文件,修改之后直接生效不需要重启,比如添加,修改,删除某一个指标配置1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23##############################################
##### 以下每一个双中括号都代表一组指标配置 ##########
##############################################
## 业务邮件发送成功数
[[cronTasks]]
interval = "0 */5 * * * *"
source = "TxMail"
sql = "select count(1) as result from queue where created <= now() AND created > DATE_SUB( now(), INTERVAL 5 MINUTE ) and status = 1"
splitTable = ""
prometheusName = "air_mail_send_success_num"
prometheusDes = "业务邮件发送成功数(5分钟内)"
prometheusLabel = "mail"
## 业务邮件堆积情况
[[cronTasks]]
interval = "0 */5 * * * *"
source = "TxMail"
sql = "select count(1) as result from queue where created <= now() AND created > DATE_SUB( now(), INTERVAL 5 MINUTE) and status = 0"
splitTable = ""
prometheusName = "air_mail_wait_num"
prometheusDes = "业务邮件堆积情况(5分钟内)"
prometheusLabel = "mail-wait-num"
对于热更新的文件,会有代码去监听,每次修改到热更新的配置文件的时候,其实就是添加或者修改 metrics 配置组,就会发送一个 channel 对象,然后重新刷新定时任务1
2
3
4
5
6
7
8
9
10
11
12
13
14LoadSiteHotConf(hotConfPath) // 加载站点热配置
var err error
fileWatcher, err = conf.NewFileWatcher(context.Background(), func(err error) {
panic(fmt.Sprintf("[FileWatcher]conf error, FileWatcher occured an error, %v", err))
})
if err != nil {
panic(err)
}
fileWatcher.AddWatch(hotConfPath, func(string) {
LoadSiteHotConf(hotConfPath)
Logs.Root.Infof("[FileWatcher]%s changed, reload SiteHotConf successfully", hotConfPath)
EventChannel <- "refresh"
})
2.一个指标就是一组配置
1 | // 单个计划任务的配置 |
接下来说明一下配置项:
Source: 很容易理解,就是在conf.toml配置的数据源Sql: 查询的 sql, 查询的 sql 有要求的,就是查询的值只能有一个,并且要统一赋值为 result,比如以下:1
2
3
4# 当前堆积未发送的邮件
select count(1) as result from queue where created <= now() AND created > DATE_SUB( now(), INTERVAL 5 MINUTE) and status = 0
# 登录成功率
select success / total * 100 AS result FROM (SELECT sum(IF( `id` > 0, 1, 0 )) AS total,sum(IF( `status` = 1, 1, 0 )) AS success FROM login_logs WHERE create_date > DATE_SUB( now(), INTERVAL 5 MINUTE ) AND type = 1) a也就是不管 sql 多么复杂,他最后一定是输出一个值,并且都叫做 result,这个是因为在程序中,这个 result 的值,就是 metrics 指标的值。
Interval: 执行计划任务执行频率,最好跟 Prometheus 的采集频率一样,最好不要太频繁的查询,因此一般都是设置为 5 分钟SplitTable: 如果有涉及到月份分表的话,那么这个值就是原始表的值,如果没有分表,那么就是为空PrometheusName: 生成的指标 metrics 的名称PrometheusDes: metric 对应的 help 注释PrometheusLabel: 附加到 metric 的 label
3. 代码执行步骤
1. 首先初始化的时候,初始化配置文件,并且初始化热更新文件,将其配置的一个个指标拿出来:
1 | // 热配置文件 |
2. 初始化定时器
初始化定时器,并且监听热更新更新的 channel 信号,每次更新的时候,刷新定时器任务1
2
3
4
5
6
7
8 // 开启定时任务。
startJobs()
for event := range resx.EventChannel {
resx.Logs.Root.Info("Received event: " + event)
// 执行相应的操作
startJobs()
}
}
1 | // startJobs 用于启动站点内的 Job。 |
3. 定时器执行任务触发 sql 查询
定时器触发就会执行这个方法,使用 x.getDB() 获取对应的数据源,使用 x.getSql() 获取 sql,同时将 sql 里面的原始表替换为有月份的月表,比如将 client_login_log 变成 client_login_log202401, 并且将查询的结果都赋给 resp.Result 这个值1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23// 如果分表的话,要替换 sql 里面的原表
func (x *PrometheusTask) getSql() string {
if x.Setting.SplitTable != "" {
newTable := x.Setting.SplitTable + ux.TimeUtil.GetPreMonth(0)
// 然后替换
return strings.Replace(x.Setting.Sql, x.Setting.SplitTable, newTable, -1)
}
return x.Setting.Sql
}
func (x *PrometheusTask) Run() error {
dbClicent := x.getDB()
resp := &struct {
Result float64
}{}
ok := dbClicent.MustGetStruct(resp, x.getSql())
if ok {
resx.Logs.Job.Debug(fmt.Sprintf("%s:%v", x.Setting.PrometheusDes, resp.Result))
// 抛送统计
x.pushToPrometheus(resp.Result)
}
return nil
}
1 | // 返回当前月往前几个月的数据格式 {yyyyMM} |
4. 将查询的 result 抛送到 pushgateway 中
1 | // 抛送到 Prometheus |
这边就只抛送一个指标,而且是瞬时类型的 Gauge。
这时候就可以在 pushgateway 上看到了,
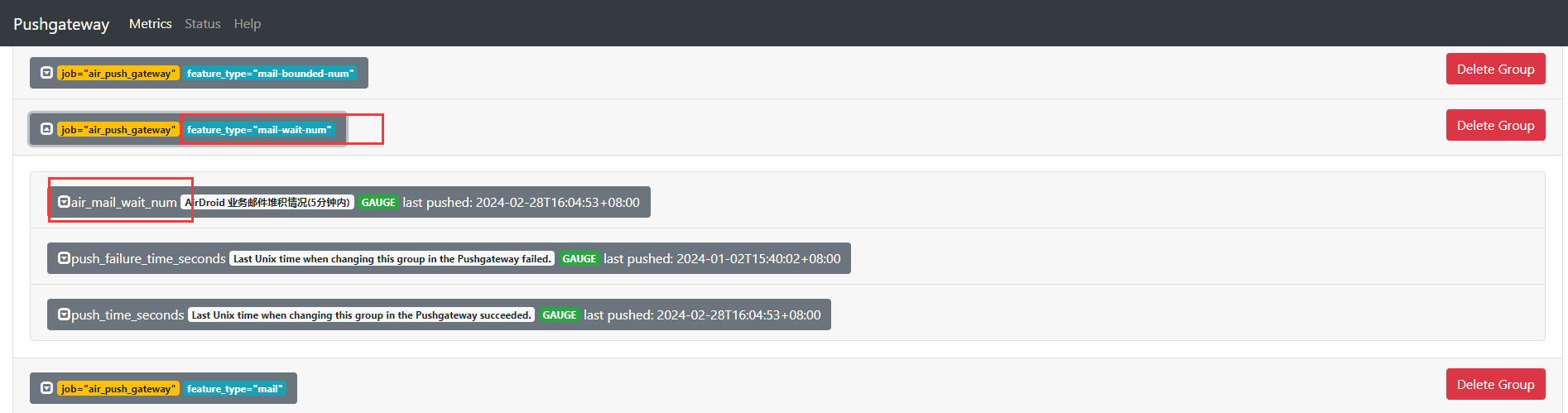
然后在 Prometheus 上配置抓取,就可以送到 Prometheus 上了:1
2
3
4
5- job_name: "pushgateway"
honor_labels: true
scrape_interval: 5m
static_configs:
- targets: ["localhost:9091"]
这样子就完成了整个业务指标自动采集自动抛送的流程了
几个注意事项
1. 计划任务执行周期和采集周期要基本上保持一致,要在一个时间周期之内
首先这个程序计划任务的执行,要跟 Prometheus 的采集周期保持在一个采集周期之内,不一定要一模一样,但是要保证在一分钟的误差之内。
这个是因为 pushgateway 上面的指标的值如果没有被新的值覆盖刷新,那么 Prometheus 下次采集到的值就会跟前一个值一样,而不是为 0。
举个列子,比如我计划任务执行了一次,上抛上去的指标的值是 100,然后程序退出了,后面就不再上抛了,这时候 Prometheus 过来采集的时候,就会一直取到这个 100 的值。
而且周期为啥要保持一致,就是因为要让 Prometheus 过来采集的值,刚好是 计划任务 新跑出来的值。,比如我设置了 3 个计划任务指标,分别的执行周期是:1
2
3interval = "0 */5 * * * *"
interval = "10 */5 * * * *"
interval = "20 */5 * * * *"
一个是每 5 分钟开始就执行,一个是每 5 分钟的 10 秒才执行, 一个是每 5 分钟的 20 秒才执行。但是这 3 个对于采集周期为 5 分钟的 Prometheus 程序来说,都是一样,都是可以采集到继上一轮之后新查询的值。
但是如果我改成每 2 分钟执行一次:1
2
3interval = "0 */2 * * * *"
interval = "10 */2 * * * *"
interval = "20 */2 * * * *"
这样子的话,对于采集周期为 5 分钟的 Prometheus 来说,它只采集最后一次的新值,也就是 4 分跑出来的那个值,而 2 分跑出来的值被 4 分的覆盖,而又没有被 Prometheus 采集到,就浪费了。
所以如果自定义的指标很多的话,为了防止查询并发,我们一般都会在这个计划任务周期保持分钟级别不变的话,将查询分摊到秒级别中,比如有些是每 5 分钟 10 秒才查询,有些是每 5 分钟的 15 秒才查询,这样子不仅可以保证查询可以被 Prometheus 采集到,还可以分摊查询压力
查询的时候,选择的数据源尽可能是以从库的方式去连接,因为只会用到 select 操作
反之如果计划任务周期比采集周期太长,也是有问题的,比如计划任务是 30 分钟采集一次,然后采集周期是 5 分钟采集一次,那么 Prometheus 就会在 30 分钟之内采集了 6 次,而且 6 次结果都是一样的。 在进行一些计算的时候,就会有问题,比如统计 1 个小时的数据1
sum_over_time(air_payment_success_num[1h])
这时候其实加的点不是原计划的 2 个点,而是 12 个点,除非你再除以 6,比如:1
sum_over_time(air_payment_success_num[1h]) / 6
这样子虽然也可以得到对的值,但是会很麻烦,而且因为采集周期的延后问题,再某些情况下会有边界的问题,导致不准确。
2. Prometheus 采集的数据会比计划任务的数据慢一个周期
举个例子,比如我有一个指标是 interval = "0 */5 * * * *" 5 分钟查询一次,查询的数据是数据库上 5 分钟的数据,也就是 7:00 - 7:05 这个时间段的数据。
假设查询查了 2s, 这时候当我抛送到 pushgateway 的时候,这时候 pushgateway 这个指标的最后采集时间就会变成 7:05:02, 这时候同样是 5 分钟采集周期的 Prometheus 其实已经采集完 7:05 这个时间节点的数据了,要等到 7:10 的时候, Prometheus 才会采集到刚才 7:05:02 的数据。
所以在 grafana 上面就可以看到 7:10 的实际数据的原始表的发生时间就是 7:00 - 7:05, 会延后一个采集周期。
但是这个不要紧,因为这个对于我们的时间周期来算的话,影响很少,比如要看某一天的支付数据,比如在 grafana 查看每天的支付成功次数的话,那么 promql 就是:1
sum_over_time(air_payment_success_num[1d])
并且因为在 grafana 的图表的时间间隔设置为 1 天,所以其实当天对应的采集周期其实是 前一天的 23:55 到 当天的 23:55。 并不是完整从数据库查的当天的 00:00-24:00, 但是这一个 5 分钟的采集误差其实对我们的观测结果没有影响,预警也不会有影响
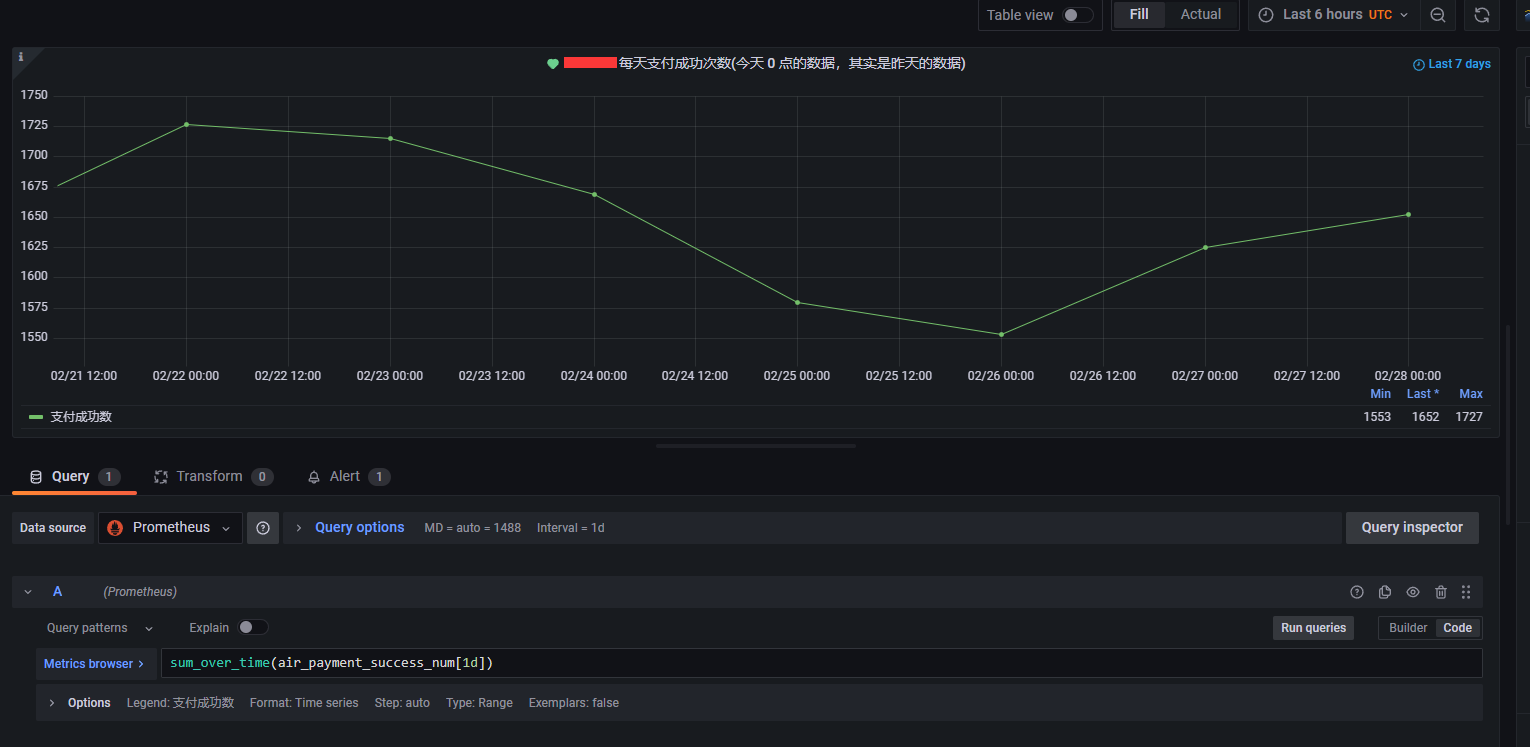
3. 采集周期不宜太长,也不宜太短,5 分钟刚刚好
这个理由上面说了, 采集周期太短, 会对查询性能有影响。 采集周期如果太长,一些比较及时的预警没办法做,比如 5 分钟的登录成功率,5 分钟的邮件发送等预警。
所以 5 分钟是一个比较合理的计划任务周期和采集周期,然后如果采集指标比较多的话,可以在 crontab 的方式将其摊到秒里面,比如 5分钟2秒执行,5分钟8秒执行等等
4. pushgateway 指标删除
一旦抛送指标到 pushgateway 中,这个指标就会一直存在,哪怕这个实例后面不再抛送指标给 Pushgateway,但是 prometheus 依然会保留这个实例的指标。
因此如果你这个指标确定不再使用了,应该直接到 pushgateway 后台进行删除,或者调用 pushgateway api 删除也行
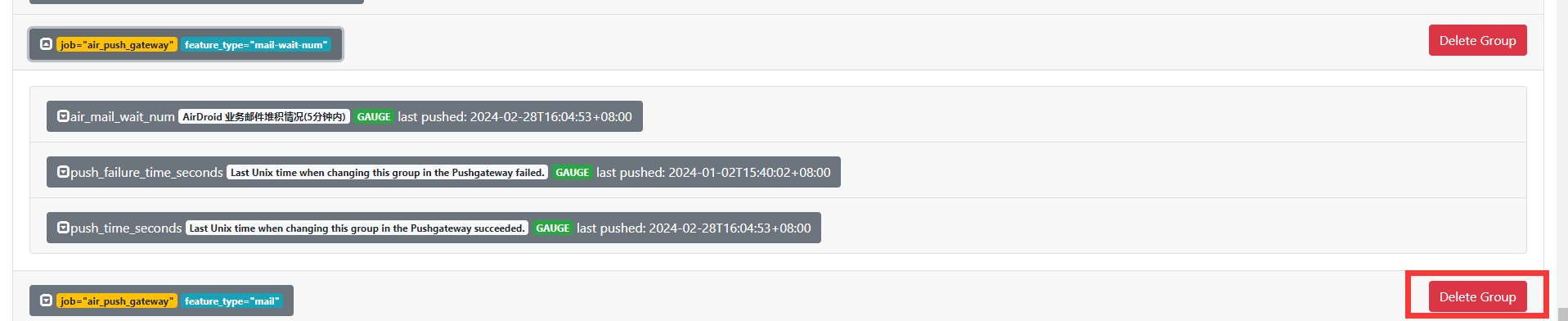
点击右边的 Delete Group 按钮即可
最佳实践
1. 可以用配置中心来对这个热更新文件进行频繁的修改
因为每次添加新的指标,都要在热更新配置文件来新增一栏配置,如果比较频繁的修改的话,可以用配置中心,比如我们自建的配置中心就可以这样子做
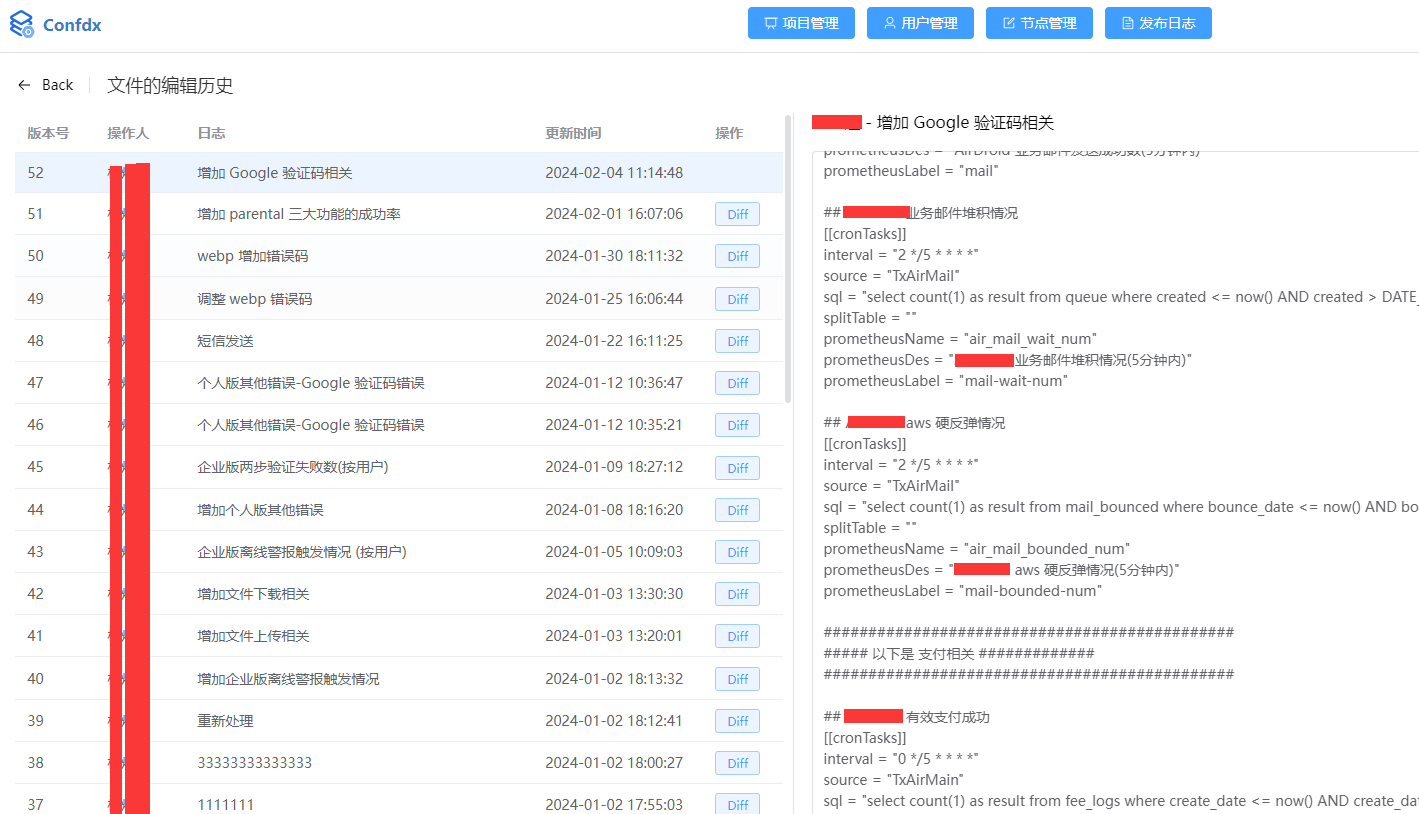
2. 如果涉及到成功率的,一律采集总数和成功数,然后再用 promql 算,不要直接用 sql 查询得到
正常情况下,我可以将某一个成功率直接查询当作指标得到,比如我要得到 pc 端的 5 分钟的登录成功率,可以这样子写1
2
3
4
5
6
7
8
9## PC 端的登录成功率(按次数)
[[cronTasks]]
interval = "0 */5 * * * *"
source = "TxAirSts"
sql = "SELECT success / total * 100 AS result FROM (SELECT sum(IF( `id` > 0, 1, 0 )) AS total,sum(IF( `status` = 1, 1, 0 )) AS success FROM pc_login_logs WHERE create_date > DATE_SUB( now(), INTERVAL 5 MINUTE ) ) a"
splitTable = "pc_login_logs"
prometheusName = "pc_login_success_rate"
prometheusDes = "PC 端的登录成功率(按次数)(5分钟内)"
prometheusLabel = "login"
但是这样子的结果就是我只能知道近 5 分钟的成功率,不知道 30 分钟的成功率,不知道 1 小时的成功率,甚至 1 天的成功率。因为正常来说,同一个业务是需要设置不同的预警条件的,比如同样是登录成功率,我可以设置 3 个预警:
- 5 分钟的成功率低于 60% -> warning 预警级别 (因为用户波峰波谷波动大,可以设置低一点,免得经常报警,一般就是观察,不处理,因为很容易恢复)
- 2 小时的成功率低于 70% -> warning 预警级别 (波动不大,有问题可以相对及时的跟进并观察)
- 24 小时的成功率低于 80% -> critical 预警级别 (波动小,有问题一般就是程序或者哪里环境有问题,要及时跟进)
但是上述的只抛送 5 分钟成功率的做法就没办法实现了,因为成功率是不能加起来,也不能平均的,误差太大。所以要算成功率的话,一般就是分两个指标,一个是总数,一个是成功数,比如我们的短信验证码发送就是这样子的:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19## 短信发送(服务端自统计) -- 发送总数
[[cronTasks]]
interval = "6 */5 * * * *"
source = "TxAirSts"
sql = "select count(1) as result from phone_auth_code where create_date <= now() AND create_date > DATE_SUB( now(), INTERVAL 5 MINUTE )"
splitTable = ""
prometheusName = "air_sms_send_all"
prometheusDes = "短信发送总数(5分钟内)"
prometheusLabel = "sms-send-all"
## 短信发送(服务端自统计) -- 发送成功
[[cronTasks]]
interval = "6 */5 * * * *"
source = "TxAirSts"
sql = "select count(1) as result from phone_auth_code where create_date <= now() AND create_date > DATE_SUB( now(), INTERVAL 5 MINUTE ) and state_code = 1"
splitTable = ""
prometheusName = "air_sms_send_success"
prometheusDes = "短信发送成功(5分钟内)"
prometheusLabel = "sms-send-success"
然后就可以在 grafana 创建各个维度的报表,比如:1
2
3
4
5
6# 5 分钟的成功率
sum(air_sms_send_success) / sum(air_sms_send_all)
# 一小时的成功率
sum(sum_over_time(air_sms_send_success[60m])) / sum(sum_over_time(air_sms_send_all[60m]))
# 一天的成功率
sum(sum_over_time(air_sms_send_success[1d])) / sum(sum_over_time(air_sms_send_all[1d]))
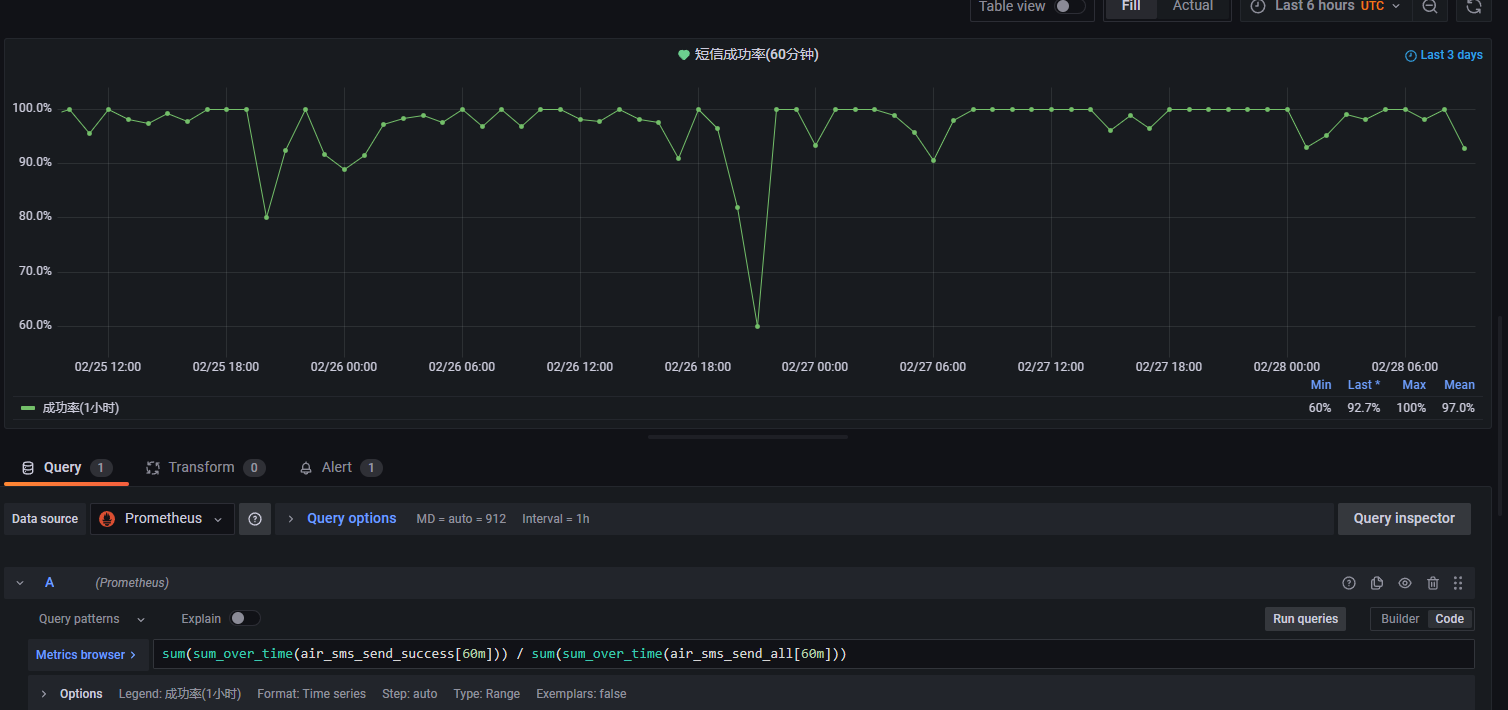
3. 设置报警的时候,可以多个指标一起设置
比如我们有个场景是监控企业版用户两步验证的失败个数和失败用户达到一定频率,要报警,为啥还要加失败用户呢,因为单纯只有失败次数的话,有些用户自己忘记了密码,会频繁重试,导致以一人之力造成了报警。
因此要两个指标结合起来报警,才会比较准,比如在设置预警的时候,可以这样子
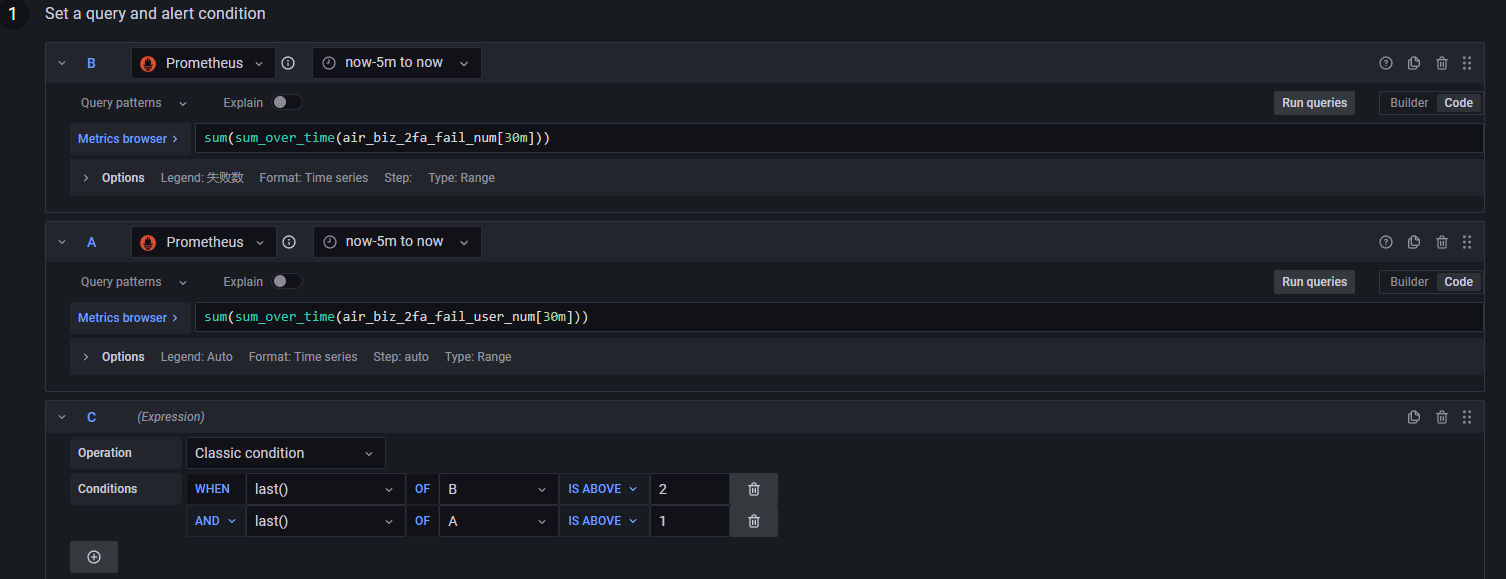
这时候要预警的话,要两个指标都要满足才行,比如预警的钉钉是这样子的:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15[监控报警]: [FIRING:1] 企业版两步验证失败次数过多 业务批处理 (critical)
--------Firing---------
【value】: [ var='C0' metric='失败数' labels={} value=4 ], [ var='C1' metric='sum(sum_over_time(air_biz_2fa_fail_user_num[30m]))' labels={} value=2 ]
【标签组】:
alertname = 企业版两步验证失败次数过多
grafana_folder = 业务批处理
operator = critical
【备注】:
description = 企业版两步验证失败次数过多, 30 分钟内有超过 2 次失败,并且超过一个用户出现问题,请开发及时查看
所属面板: https://g.foo.cn/d/8W1cGKdSz?orgId=1&viewPanel=14
发生时间: 2024-02-23 23:35:00 +0800 CST
总结
通过这个计划任务批处理来定时上抛业务数据到 pushgateway 服务,并通过在 grafana 设置对应的 dashboard 和 预警,我们可以实现在业务数据上面的数据可观测性。 然后在结合之前的 nginx 请求可观测行, mtail 的运行日志可观测性,基本上就可以覆盖大部分的业务场景的预警可观测了, 不会再出现那种业务出异常了,服务端还不知道,只能等客户反馈的囧境了。