前言
上一节我们已经可以通过采集 nginx 的 access log 来得到程序的流量情况,以及针对异常状态码来设置预警
已经可以解决突发性的故障问题了,但是要达到更好的日志可观测性,还是不够,至少有以下两种场景没办法满足:
程序框架的异常状态码和 nginx 的状态码解耦。 有些程序框架为了保证返回值的友好和错误码的统一,是会在框架底层将抛出来的错误 catch 掉的,而不是直接扔到 nginx 上层返回。 举个例子,比如我们的 golang 框架就是这样子的,我们有自己定制了一整套的错误码标准,包含 数组越界,空指针异常 等异常都会在程序底层 catch,并在返回的 json 串填充错误码 code,并返回 200 状态码。 因此在 nginx 层,基本上只能看到 200 的正常码, 是看不到异常的 500 错误码的(nginx 本身的 499, 502, 504 还是有的)。要看程序错误,只能去查程序的输出 log。
大部分的对外提供的 API 接口,也是会将程序的错误码和 http 的异常码解耦掉
针对某些外接第三方的 webhook 的错误处理也没办法返回异常状态码。 比如以支付项目为例,我们会接 Google 和 Apple 的 webhook 通知来处理订单状态,这时候有些处理逻辑是本身程序有 bug,你是不能直接针对 webhook 的返回响应返回异常状态码的,比如 500 错误码,不然这些第三方的 webhook 可能就会再重发。因此哪怕是程序异常,也最好是返回 200 正常码。那么对于这种情况,如果要检测的话,也是只能通过采集程序日志来进行发现和预警。
综上所述,我们还是需要一种可以采集程序日志来生成 Prometheus 指标的服务。
mtail
我这边采用的是 Google 出品的 mtail
mtail 是一个用于从应用程序日志中提取指标的工具,这些指标可以被导出到时间序列数据库或时间序列计算器中,用于警报和仪表板。它填补了一个监控领域的空白,作为不导出自身内部状态的应用程序(除了通过日志)和现有监控系统之间的粘合剂,这样系统操作员就不需要为这些应用程序打补丁以进行检测,或为每一个这样的应用程序编写自定义的提取代码。
简单的来说,mtail 就是流式读取日志,通过正则表达式匹配的方式从日志中提取 metrics 指标,这种方式可以利用目标机器的算力,另外一个好处是无侵入性,不需要业务埋点,如果业务程序是第三方供应商提供的,我们改不了其代码,mtail 此时就非常合适了。
1. 安装
安装的话也很简单,mtail 提供了好几种安装方式: Building mtail, 有 golang 安装,docker 安装, 二进制包安装。
我们直接采用二进制包的方式来安装: 二进制下载地址
一样使用 centos 来进行测试:1
2
3
4
5
6
7
8
9
10
11
12[root@VM-16-122-centos ~]# wget https://github.com/google/mtail/releases/download/v3.0.0-rc53/mtail_3.0.0-rc53_linux_amd64.tar.gz
[root@VM-16-122-centos ~]# mkdir mtail
[root@VM-16-122-centos ~]# cd mtail/
[root@VM-16-122-centos mtail]# tar -zxvf ../mtail_3.0.0-rc53_linux_amd64.tar.gz
LICENSE
README.md
mtail
[root@VM-16-122-centos mtail]# ll
total 15564
-rw-r--r-- 1 1001 127 11358 Jan 7 13:58 LICENSE
-rwxr-xr-x 1 1001 127 15913197 Jan 7 13:59 mtail
-rw-r--r-- 1 1001 127 4781 Jan 7 13:58 README.md
这样子就安装好了,可以看到其实就一个 mtail 的二进制文件。
2. 启动
可以直接启动:1
./mtail --progs /disk/tools/mtail/conf --logs '/disk/tools/mtail/logs/*.log' --logs /var/log/messages --log_dir /disk/tools/mtail/logdir
有几个参数会比较常用:
--progs: 指定一个目录,这个目录里放置一堆的*.mtail文件,每个 mtail 文件就是描述的正则提取规则--logs: 监控的日志文件列表,可以使用,分隔多个文件,也可以多次使用--logs参数,也可以指定一个文件目录,支持通配符,使用通配符的时候,在指定文件目录时需要对目录使用单引号。如:--logs a.log,b.log,c.log --logs a.log --logs b.log --logs c.log --logs '/export/logs/*.log'--log_dir: mtail 组件自身日志存放目录--port: mtail 组件 http 监听端口,默认 3903--poll_log_interval: 对匹配的日志进行轮询的间隔,默认是 250ms
更多参数和应用具体可以看官方文档: Deploying
3. demo 实践
接下来具体操作一下,首先将其变成 service 服务:
在这之前,要先新建一个 mtail 的规则文件,在 /root/mtail/conf 这个目录下1
2
3
4
5
6
7[root@VM-16-122-centos conf]# cat linecount.mtail
# The most basic of mtail programmes -- count the number of lines read.
counter my_lines_total
/$/ {
my_lines_total++
}
逻辑很简单,就是统计行数。具体规则文件怎么写,可以看官网的教程文档: mtail Programming Guide
然后接下来就可以走 service 的方式启动了:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25# cat /usr/lib/systemd/system/mtail.service
[Unit]
Description=mtail metrics exporter for Prometheus
After=network-online.target
[Service]
ExecStart=/root/mtail/mtail --progs /root/mtail/conf --logs '/var/log/test_log/a.log' --log_dir /root/mtail/logs
Restart=always
ProtectSystem=full
CapabilityBoundingSet=
[Install]
WantedBy=multi-user.target
# systemctl daemon-reload
# systemctl enable mtail.service
# systemctl start mtail.service
# systemctl status mtail.service
● mtail.service - mtail metrics exporter for Prometheus
Loaded: loaded (/usr/lib/systemd/system/mtail.service; enabled; vendor preset: disabled)
Active: active (running) since Thu 2024-02-01 17:50:37 CST; 10s ago
Main PID: 19993 (mtail)
CGroup: /system.slice/mtail.service
└─19993 /root/mtail/mtail --progs /root/mtail/conf --logs /var/log/test_log/a.log --log_dir /root/mtail/logs
Feb 01 17:50:37 VM-16-122-centos systemd[1]: Started mtail metrics exporter for Prometheus.
启动指令就是这个:
/root/mtail/mtail –progs /root/mtail/conf –logs ‘/var/log/test_log/a.log’ –log_dir /root/mtail/logs
上面对应的目录(/root/mtail/logs) 如果原先没有的话,要先新建
这时候就有 log 产生了:1
2
3
4
5
6
7
8
9
10
11
12
13
14[root@VM-16-122-centos log]# tail -f /root/mtail/logs/mtail.INFO
Log file created at: 2024/02/01 17:50:37
Running on machine: VM-16-122-centos
Binary: Built with gc go1.20.12 for linux/amd64
Previous log: <none>
Log line format: [IWEF]mmdd hh:mm:ss.uuuuuu threadid file:line] msg
I0201 17:50:37.896166 19993 main.go:119] mtail version 3.0.0-rc53 git revision 018c81d637bde5c218ce5a9778b4590d2bfd4782 go version go1.20.12 go arch amd64 go os linux
I0201 17:50:37.896305 19993 main.go:120] Commandline: ["/root/mtail/mtail" "--progs" "/root/mtail/conf" "--logs" "/var/log/test_log/a.log" "--log_dir" "/root/mtail/logs"]
I0201 17:50:37.896601 19993 store.go:189] Starting metric store expiry loop every 1h0m0s
I0201 17:50:37.897144 19993 runtime.go:187] Loaded program linecount.mtail
I0201 17:50:37.897171 19993 runtime.go:83] unmarking linecount.mtail
I0201 17:50:37.897205 19993 logstream.go:61] Parsed url as /var/log/test_log/a.log
I0201 17:50:37.897287 19993 tail.go:287] Tailing /var/log/test_log/a.log
I0201 17:50:37.897335 19993 mtail.go:137] Listening on [::]:3903
这时候塞入几条 log 试试:1
2
3
4[root@VM-16-122-centos test_log]# echo "hello mtail 21" >> a.log
[root@VM-16-122-centos test_log]# echo "hello mtail 22" >> a.log
[root@VM-16-122-centos test_log]# echo "hello mtail 23" >> a.log
[root@VM-16-122-centos test_log]# echo "hello mtail 24" >> a.log
这时候请求 metrics 接口: curl http://127.0.0.1:3903/metrics | grep my_lines_total 就可以看到我们的指令了 (还有一些是默认的 golang 采集指标)1
my_lines_total{prog="linecount.mtail"} 4
处理多项目的问题
正常我们的服务器很多时候会同时部署多个程序,这时候如果要通过 mtail 来采集这些程序的 log 的话,有一个情况要注意
mtail 的设计不允许将特定的规则文件应用于特定的日志文件。在 mtail 中,所有的规则文件都会被应用于所有的日志文件。这是因为 mtail 的主要目标是从多个日志文件中提取和导出指标,而不是对每个日志文件进行单独处理。
举个例子,比如我有两个程序,一个是 id, 一个是 pay,他们的规则分别是 id.mtail 和 pay.mtail。 同时他们的规则文件都有针对内存超出的信息和错误信息做采集,比如:1
2
3
4
5
6
7
8
9
10# cat id.mtail
counter project_error_total by project
counter mem_not_allow_total by project
/Error:/ {
project_error_total["id"]++
}
/Allowed memory size of/ {
mem_not_allow_total["id"]++
}
1 | # cat pay.mtail |
其实就是两个 metrics,
- 一个是记录 Error 信息的指标
project_error_total, 这个指标有个 project 标签,如果是抓取 id 项目的,那么 project 标签就是 id,如果是抓取 pay 项目的 log 文件的,那么 project 标签就是 pay,抓取规则就是日志中含有字符串Error:就符合 - 一个是记录是否内存溢出的指标
mem_not_allow_total,标签规则同project_error_total一样,抓取规则就是 日志中含有字符串Allowed memory size of就符合
mtail 中的 counter、gauge、histogram 三种类型与prometheus类型中描述的作用一致, 本例用的是 counter 这个类型
他们各自的 log 日志文件地方也不一样:
- id 项目的 log 目录是:
/var/log/test_log/id/app.log - pay 项目的 log 目录是:
/var/log/test_log/pay/2024-01-01.log, 他是每天都滚一个 log,也就是在 pay 这个目录下,每天都会新增 log
这时候我们开始启动:1
/root/mtail/mtail --progs /root/mtail/conf --logs '/var/log/test_log/id/*.log' --logs '/var/log/test_log/pay/*.log' --log_dir /root/mtail/logs
从启动 log 日志可以看到,这些 log 都有被监控了:1
2I0202 15:48:28.898287 9998 tail.go:287] Tailing /var/log/test_log/id/app.log
I0202 15:48:28.898360 9998 tail.go:287] Tailing /var/log/test_log/pay/2024-01-01.log
接下来开始插入新 log, 往 id/app.log 插入一条 Error 日志1
2
3
4[root@VM-16-122-centos pay]# echo "[2024-02-02 03:29:07] Error: webHook id: evt_1OfDR9AP4l9" >> /var/log/test_log/id/app.log
[root@VM-16-122-centos pay]# cat /var/log/test_log/id/app.log
start---
[2024-02-02 03:29:07] Error: webHook id: evt_1OfDR9AP4l9
然后直接请求 metrics 接口:1
2
3
4
5[root@VM-16-122-centos pay]# curl http://127.0.0.1:3903/metrics | grep project_error_total
# HELP project_error_total defined at id.mtail:1:9-27
# TYPE project_error_total counter
project_error_total{prog="id.mtail",project="id"} 1
project_error_total{prog="pay.mtail",project="pay"} 1
发现这个指标两个都是 1, 也就是两个规则都采集了。 这不是我们想要的。我们只想要 id.mtail 规则采集, pay.mtail 规则不采集。
这也证明了上面的说法,就是 mtail 采集 log 日志的时候,会应用到所有的 mtail 规则文件。
如果想要不同的项目分开采集的话,比如 pay 的 log 只应用于 pay.mtail 规则文件, id 的 log 只应用于 id.mtail 的规则文件,那么有两种方法:
- 分开两个 mtail 进程来采集, 各采各的,互不干扰
- 还是同一个 mtail 进程采集,但是规则文件要对采集的 log 来源进行过滤判断
1. 分成多个 mtail 各自采集
这个就很好理解,无非就是再开一个 mtail 进程,注意监听的端口要分开, 比如1
2mtail -logs /server/id/logs/app.log -progs /path/to/id.mtail -port 3903 &
mtail -logs /server/pay/logs/*.log -progs /path/to/pay.mtail -port 3904 &
如果采集程序真的很多,要启动很多的 mtail 进程的话,那么建议直接用 docker 来进行部署会更方便,首先安装 docker
因为 mtail 并没有原生的官方 docker 镜像,所以需要自己创建一个 docker 镜像来运行 mtail:1
2
3
4
5
6
7
8
9
10
11
12
13
14[root@VM-16-122-centos mtail_docker]# cat Dockerfile
FROM golang:1.16 as builder
WORKDIR /go/src/mtail
RUN git clone https://github.com/google/mtail.git /go/src/mtail && \
cd /go/src/mtail && \
git checkout v3.0.0-rc45 && \
make install_deps && \
make
FROM debian:buster-slim
COPY --from=builder /go/src/mtail/mtail /usr/local/bin/mtail
ENTRYPOINT ["mtail", "--logs", "/logs/*.log", "--progs", "/progs", "--log_dir", "/logDir"]
指令是一样,我们后面起 docker 的时候,只需要挂载到 宿主机的目录即可,然后做下端口映射即可。
接下来编译成镜像:1
2
3
4[root@VM-16-122-centos mtail_docker]# docker build -t mtail .
[+] Building 0.6s (10/10) FINISHED docker:default
。。。
=> => naming to docker.io/library/mtail
然后接下来就可以初始化容器了, 先起 id 的:1
2
3
4
5[root@VM-16-122-centos mtail_docker]# docker run -d -p 3904:3903 -v /var/log/test_log/id:/logs -v /root/mtail/conf/id:/progs -v /root/mtail/logs/id:/logDir --name mtail_id mtail
b218cd76f41d8568b056cc74cb8f35675246b2b27e57b8d7f4b14a4fbd17ae08
[root@VM-16-122-centos mtail_docker]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
b218cd76f41d mtail "mtail --logs /logs/…" 2 seconds ago Up 1 second 0.0.0.0:3904->3903/tcp, :::3904->3903/tcp mtail_id
这时候,容器就启动了,直接查看 log1
2
3
4
5
6
7
8
9
10
11[root@VM-16-122-centos id]# tail -f /root/mtail/logs/id/mtail.INFO
Log file created at: 2024/02/03 08:44:28
Running on machine: b218cd76f41d
Binary: Built with gc go1.16.15 for linux/amd64
Log line format: [IWEF]mmdd hh:mm:ss.uuuuuu threadid file:line] msg
I0203 08:44:28.930725 1 main.go:113] mtail version v3.0.0-rc45-dirty git revision 5e2fe145030128f030793a6ea65204808ffc834d go version go1.16.15 go arch amd64 go os linux
I0203 08:44:28.930869 1 main.go:114] Commandline: ["mtail" "--logs" "/logs/*.log" "--progs" "/progs" "--log_dir" "/logDir"]
I0203 08:44:28.931091 1 store.go:178] Starting metric store expiry loop every 1h0m0s
I0203 08:44:28.931660 1 loader.go:246] Loaded program id.mtail
I0203 08:44:28.931830 1 tail.go:259] Tailing /logs/app.log
I0203 08:44:28.931875 1 mtail.go:193] Listening on [::]:3903
这边指令显示的是容器中的目录,其实已经全部挂载到宿主机了,跟原先用 service 是一样的目录 (有个细节,原先是 conf/id.mtail, 后面抽了一层目录出来,变成 conf/id/id.mtail )
这时候一样,写入原先的 id 的 app.log, 这时候写入 log,就可以看到了:1
2
3
4
5
6
7
8
9
10[root@VM-16-122-centos pay]# echo "[2024-02-03 03:29:12] Error: webHook id: evt_1OfDR9AP4l9233" >> /var/log/test_log/id/app.log
[root@VM-16-122-centos pay]# curl http://127.0.0.1:3904/metrics | grep project_error_total
# HELP project_error_total defined at id.mtail:1:9-27
# TYPE project_error_total counter
project_error_total{prog="id.mtail",project="id"} 1
[root@VM-16-122-centos pay]# echo "[2024-02-03 03:29:13] Error: webHook id: evt_1OfDR9AP4l9233" >> /var/log/test_log/id/app.log
[root@VM-16-122-centos pay]# curl http://127.0.0.1:3904/metrics | grep project_error_total
# HELP project_error_total defined at id.mtail:1:9-27
# TYPE project_error_total counter
project_error_total{prog="id.mtail",project="id"} 2
同时,如果要做 pay 的话,直接再起一个容器即可,然后端口映射成 3905 即可。 挂载对应的目录即可,不需要 build 镜像了。1
2
3
4
5
6[root@VM-16-122-centos mtail_docker]# docker run -d -p 3905:3903 -v /var/log/test_log/pay:/logs -v /root/mtail/conf/pay:/progs -v /root/mtail/logs/pay:/logDir --name mtail_pay mtail
e17db412f959350aebca874c8ff3345714c7935d4fd4d7a7305a217c8ff351d1
[root@VM-16-122-centos mtail_docker]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
e17db412f959 mtail "mtail --logs /logs/…" 2 seconds ago Up 1 second 0.0.0.0:3905->3903/tcp, :::3905->3903/tcp mtail_pay
b218cd76f41d mtail "mtail --logs /logs/…" 5 minutes ago Up 5 minutes 0.0.0.0:3904->3903/tcp, :::3904->3903/tcp mtail_id
这时候看 log 就有了1
2
3
4
5
6
7
8
9
10
11[root@VM-16-122-centos id]# tail -f /root/mtail/logs/pay/mtail.INFO
Running on machine: e17db412f959
Binary: Built with gc go1.16.15 for linux/amd64
Log line format: [IWEF]mmdd hh:mm:ss.uuuuuu threadid file:line] msg
I0203 08:49:51.234788 1 main.go:113] mtail version v3.0.0-rc45-dirty git revision 5e2fe145030128f030793a6ea65204808ffc834d go version go1.16.15 go arch amd64 go os linux
I0203 08:49:51.234940 1 main.go:114] Commandline: ["mtail" "--logs" "/logs/*.log" "--progs" "/progs" "--log_dir" "/logDir"]
I0203 08:49:51.235168 1 store.go:178] Starting metric store expiry loop every 1h0m0s
I0203 08:49:51.235673 1 loader.go:246] Loaded program pay.mtail
I0203 08:49:51.235803 1 tail.go:259] Tailing /logs/2024-01-01.log
I0203 08:49:51.235844 1 tail.go:259] Tailing /logs/2024-01-02.log
I0203 08:49:51.235885 1 mtail.go:193] Listening on [::]:3903
然后加一下 log:1
2
3
4
5[root@VM-16-122-centos pay]# echo "[2024-02-03 03:29:13] Error: webHook id: evt_1OfDR9AP4l9233" >> /var/log/test_log/pay/2024-01-02.log
[root@VM-16-122-centos pay]# curl http://127.0.0.1:3905/metrics | grep project_error_total
# HELP project_error_total defined at pay.mtail:1:9-27
# TYPE project_error_total counter
project_error_total{prog="pay.mtail",project="pay"} 1
这样子就可以通过 docker 来进行多个 mtail 的管理了,本质上跟 service 的方式差不多,但是不管是管理还是扩展都会更方便。
2. 同一个 mtail, 规则文件要对采集的 log 来源进行过滤判断
除了上面的多个 mtail 分别采集之外,还有一种方式可以做到同一个 mtail 采集多个程序的情况,那就是在对应服务的 mtail 规则文件中,过滤判断当前采集的 log 文件。
比如我将上述的 id.mtail 和 pay.mtail 改成:1
2
3
4
5
6
7
8
9
10
11
12
13
14# cat id.mtail
counter project_error_total by project
counter mem_not_allow_total by project
getfilename() !~ /id\/app.log/ {
stop
}
/Error:/ {
project_error_total["id"]++
}
/Allowed memory size of/ {
mem_not_allow_total["id"]++
}
1 | # cat pay.mtail |
其他都没有变,就多了一个判断,如果当前采集的 log 文件名不在规则文件的允许范围内的话,就直接跳过。通过这种方式的话,就可以做到某一个规则文件只采集它想要采集的 log 日志
启动起来:1
/root/mtail/mtail --progs /root/mtail/conf --logs '/var/log/test_log/id/*.log' --logs '/var/log/test_log/pay/*.log' --log_dir /root/mtail/logs
然后接下来试一下:1
2
3
4
5[root@VM-16-122-centos pay]# echo "[2024-02-04 03:29:13] Error: webHook id: evt_1OfDR9AP4l9233" >> /var/log/test_log/pay/2024-01-02.log
[root@VM-16-122-centos pay]# curl http://127.0.0.1:3903/metrics | grep project_error_total
# HELP project_error_total defined at pay.mtail:1:9-27
# TYPE project_error_total counter
project_error_total{prog="pay.mtail",project="pay"} 1
往 pay 加了一行,可以检测到,而且 id 没有,说明过滤是生效的。
综上所述,通过在 mtail 对当前采集的 log 文件进行判断,是可以实现单个 mtail 采集多个服务程序的效果的。不过一定要注意,就是采集的程序不能太多,因为每一次 mtail 还是要 tailing 和分析所有的 log 的,如果采集的文件很多,并且包含很多程序,假设有 10 个程序被集采, 这个就意味着每当某一个程序生成 log 的时候, mtail 要执行 10 个程序的 mtail 文件进行匹配解析,然后一一过滤,最后只有一个可以得到正常采集。
这个效率就会很低了,比较影响性能,所以要注意。如果某一台服务器要采集很多个程序的话,最好还是分多个 mtail 程序去采集,用 docker 处理也很方便。但是如果只有两三个程序的话,是可以用这种方式的。
生产环境使用
后面如果要在生产环境中使用的话,肯定要规范生成的 metrics 规则。 一般来说,只需要两个 metrics 指标就够了1
2counter logs_stat_info_total by project, level
counter logs_stat_info_detail by project, level, module, des
其中 logs_stat_info_total 有两个标签,一个是 project 表示项目,一个是 level 表示日志级别,比如 info,debugger,error 等级别
logs_stat_info_detail 有四个标签,多了两个,一个是错误的模块,一个是错误的详情,比如 mem_oom, 内存溢出,那么 module 就是 os,表示系统,如果是 http timeout,那么 module 就是 http 等等
然后线上可以这样子写,以 id.mtail 为例:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60# id 的规则匹配文件
######################################
###########定义一堆的常量
######################################
const ANY /.*/
# yii2 的通用日志错误
const YII_ERROR /\[error\]/
######################################
###########定义指标
######################################
counter logs_stat_info_total by project, level
counter logs_stat_info_detail by project, level, module, des
######################################
###########判断文件过滤
######################################
getfilename() !~ /id\/api\/runtime\/logs\/app.log/ {
stop
}
######################################
########### 规则文件
######################################
YII_ERROR {
logs_stat_info_total["id"]["error"]++
}
// + YII_ERROR + ANY + /yii\\base\\ErrorException/ {
logs_stat_info_detail["id"]["error"]["yii"]["base_exception"]++
}
// + YII_ERROR + ANY + /yii\\base\\InvalidRouteException/ {
logs_stat_info_detail["id"]["error"]["yii"]["route_invalid"]++
}
// + YII_ERROR + ANY + /Undefined offset:/ {
logs_stat_info_detail["id"]["error"]["yii"]["undefined_offset"]++
}
// + YII_ERROR + ANY + /\[PDOException\]/ {
logs_stat_info_detail["id"]["error"]["mysql"]["pdo_exception"]++
}
// + YII_ERROR + ANY + /SQLSTATE\[/ {
logs_stat_info_detail["id"]["error"]["mysql"]["sql_state_fail"]++
}
// + YII_ERROR + ANY + /\[api\\utils\\BizException\]/ {
logs_stat_info_detail["id"]["error"]["biz"]["biz_exception"]++
}
// + YII_ERROR + ANY + /Allowed memory size of/ {
logs_stat_info_detail["id"]["error"]["os"]["mem_exhausted"]++
}
上面的规则文件可以根据自己的需求来写,mtail 的规则很灵活也很强大,官方有提供了很多的规则文件的示例: mtail example, 我们可以在使用过程中去参考。如果后面用的很深的话,可以再开一个篇幅来讲一下 mtail 的规则文件应该怎么写。
Prometheus 那边就可以配采集了 (这边采用的是 sd 的外挂方式,后面添加新的 mtail 采集 target 的时候,直接添加对应的 yml 文件即可,不需要再重启 Prometheus 服务)1
2
3
4
5# mtail 日志采集服务
- job_name: "server-mtail"
file_sd_configs:
- files:
- file_sd/server-mtail/*.yml
然后在对应的目录下,配上各个服务所在的 mtail 采集1
2
3
4
5
6
7
8
9- targets:
- 172.19.16.9:3904
labels:
env: prod
product_line: personal
region: hk
cloud_platform: tx
server_type: mtail-log
wan: 43.xx.xxx.123
这边要注意一个细节,最好每次修改 mtail 规则文件之后,要去请求一下对应的端口服务,可以检测规则文件是否有问题
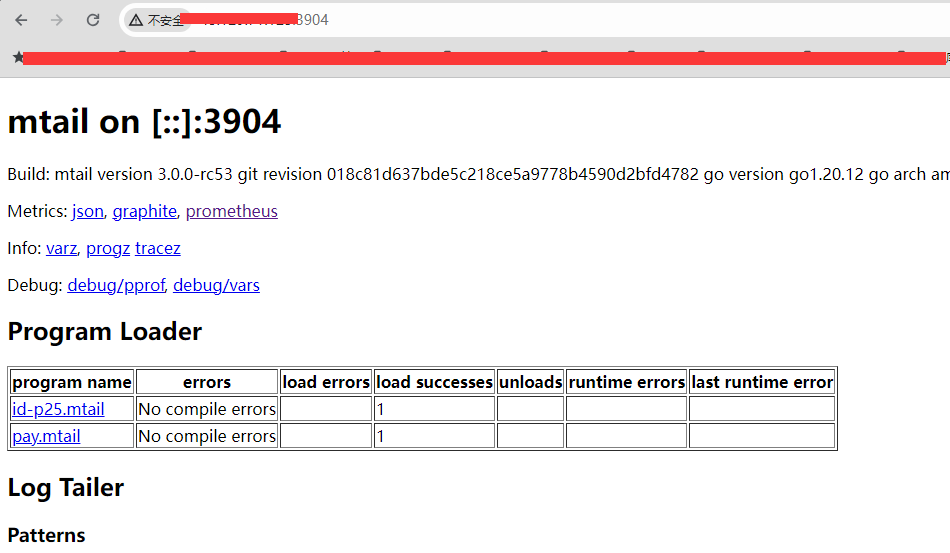
如果规则有问题的话,errors 那一栏就会显示编译错误,比如我将1
2
3// + YII_ERROR + ANY + /Allowed memory size of/ {
logs_stat_info_detail["id"]["error"]["os"]["mem_exhausted"]++
}
改成:1
2
3YII_ERROR + ANY + /Allowed memory size of/ {
logs_stat_info_detail["id"]["error"]["os"]["mem_exhausted"]++
}
这时候就会报错了

然后接下来就可以在 grafana 那边创建对应的 dashboard 了,并设置预警了
抓取 php-fpm show log
除了可以抓取特定项目的 log 之外,mtail 还可以抓取一些程序的 log,比如这个 php-fpm 程序的 show log。
而且因为一台服务器有可能会部署多个 php 程序,他们都用 php-fpm 来进行托管,所以在抓取的时候,也要可以识别是哪个 php 程序产生的慢查询,所以 php-fpm.mtail 文件可以这样写:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36# php-fpm 的规则匹配文件
######################################
###########定义一堆的常量
######################################
const SLOW_LOG_TIMESTAMP /\[\d{2}-\w{3}-\d{4} \d{2}:\d{2}:\d{2}\]/
const SLOW_LOG_SCRIPT_FILENAME /script_filename = .*wwwroot\/(?P<project_full>[^\/]+)\/\S+/
######################################
###########定义指标
######################################
counter logs_stat_info_total by project, level
hidden text project_name
######################################
###########判断文件过滤
######################################
getfilename() !~ /php-fpm\.slow\.log/ {
stop
}
######################################
########### 规则文件 (每一个 php-fpm 的慢查询的设定时长都不太一样,要看 php-fpm.conf 的具体配置)
######################################
SLOW_LOG_TIMESTAMP {
logs_stat_info_total["php-fpm"]["error"]++
}
# 匹配脚本文件名
SLOW_LOG_SCRIPT_FILENAME {
# 提取 wwwroot 目录后的第一个子目录,并且只取点的第一部分
project_name = "fpm-" + subst(/\..*/, "", $project_full)
logs_stat_info_total[project_name]["error"]++
}
正常一个 php-fpm 的慢查询 log 的格式是:1
2
3
4
5[17-Jun-2024 22:10:23] [pool www] pid 24047
script_filename = /data/server/wwwroot/id4.example.com/api/web/index.php
[0x00007fef978e8638] execute() /data/server/wwwroot/id4.example.com/id/vendor/yiisoft/yii2/db/Command.php:771
[0x00007fef978e8468] execute() /data/server/wwwroot/id4.example.com/id/api/models/business/master/BusinessBaseModel.php:383
....
我们只取前面两条就够了。其中第一条时间有记录时间的,就当作这一台服务器通用的 php-fpm 的慢查询 log。第二条的 filename 因为是有项目路径。所以就可以直接通过正则将项目名称取出来,然后取前缀即可。
最后就可以得到类似的1
2
3logs_stat_info_total{level="error",prog="php-fpm.mtail",project="fpm-id-rs"} 2
logs_stat_info_total{level="error",prog="php-fpm.mtail",project="fpm-id4"} 230
logs_stat_info_total{level="error",prog="php-fpm.mtail",project="php-fpm"} 232
然后图表选项目的时候,就可以看到这几个 project 可以选了

总结
通过 mtail 的采集,我们可以很灵活的采集我们服务程序中的错误,尤其是当我们的服务的 log 非常规范的时候,不仅 level 很规范,错误抛出的 error msg 和 error code 也很规范的时候, 其实 mtail 的规则文件,就会大同小异了。 基本上写一份,后面基本上就是拷贝了。
mtail 很大的弥补了 nginx 采集没法解决的问题,事实上 mtail 的规则很强大,nginx 的 aceess log 也是日志,也是可以通过 mtail 写规则文件来采集的。就是规则文件会稍微复杂,不像 prometheus-nginxlog-exporter 来得便利
参考资料: