前言
之前有出现过一种情况,就是我们的静态站点是有国内和国外加速的(这个是在 aws 的 router 53 服务配置的),比如:
- 如果是国内访问的,那么就引导到腾讯云的 COS 存储服务 + CDN 服务
- 如果是国外访问的,那么就引导到 aws 的 S3 存储服务 + Cloudfront CDN 服务
正常的文件当然没问题,但是有时候会出现如果 url 后面不输入 index.html,直接子目录斜杠结尾,比如 https://m.foo.com/cast/ ,这时候腾讯云表现是正常的,因为他会索引到 https://m.foo.com/cast/index.html, 但是 aws 的 cloudfront 就不行,会直接报错, 显示获取 S3 对象失败:1
2
3[kbz@VM_16_9_centos ~]$ curl https://m.foo.com/cast/
<?xml version="1.0" encoding="UTF-8"?>
<Error><Code>AccessDenied</Code><Message>Access Denied</Message><RequestId>QABCT7FCM4M3T4AR</RequestId><HostId>VnPLeZeR2KQkIMDrFhukmVLUGp+RBWbZO/V8qHeS0dGKLa1N8KOTbWvwNW/J2NKbQWqQXyP5wdw=</HostId></Error>
更有甚者,如果我连子目录的斜杠都没有写全,直接子目录的话,比如 https://m.foo.com/cast, 这时候腾讯云的表现也是对的,他如果找不到 cast 这个文件的话,就会将其当做一个子目录,再去检索这个子目录下的 index.html 文件。所以你用 curl 请求的话,会返回一个 302 跳转,然后 location 头部就会带上 https://m.foo.com/cast/, 这时候就会跳转到正确的页面:
1 | [kbz@centos156 ~]$ curl -I https://m.foo.com/cast |
如果是换成 aws 的 cloudfront 的话,那肯定就是又找不到文件了:1
2
3[kbz@VM_16_9_centos ~]$ curl https://m.foo.com/cast
<?xml version="1.0" encoding="UTF-8"?>
<Error><Code>AccessDenied</Code><Message>Access Denied</Message><RequestId>52F9V25GCXQYVZ0V</RequestId><HostId>bk0YnUOx7fQz3mwqGCA84hXZXuLUj8Tb2YjH6DNhd+SLu75csLPDfstR5qRksNKZldPvqh2Hst4=</HostId></Error>
解决方式
那么要怎么解决呢,让其 Cloudfront 的跳转规则跟 腾讯云 的跳转规则一致??
首先我们要知道,其实对于根目录的默认索引文件, Cloudfront 是允许设置的。
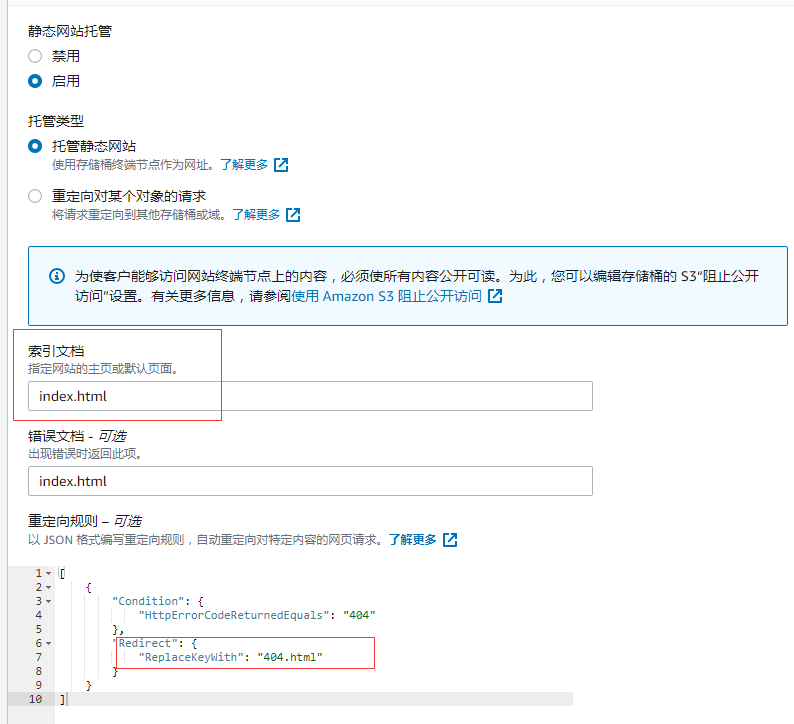
也就是说,我如果输入 https://m.foo.com, 那么是会索引到 https://m.foo.com/index.html 这个是没问题的。
但是他不适合 子目录 的方式,这个是他文档的描述:
CloudFront does allow you to specify a default root object (index.html), but it only works on the root of the website (such as http://www.example.com > http://www.example.com/index.html). It does not work on any subdirectory (such as http://www.example.com/about/). If you were to attempt to request this URL through CloudFront, CloudFront would do a S3 GetObject API call against a key that does not exist.
也就是说,我如果请求
http://www.example.com/about/, 那么 cloudfront 只会老老实实的去 S3 bucket 去取这个对象,而不会去找这个子目录默认的索引文件 index.html
不过他有给了我们一个解决方法,就是用 Lambda 的边缘计算能力,针对 cloudfront 的请求进行重写, 从而让 cloudfront 在 S3 bucket 找到对应的文件。
具体操作文档: 使用Lambda @ Edge在Amazon S3支持的Amazon CloudFront起源中实施默认目录索引
具体实操
对于 Lambda 以及跟 S3 和 Cloudfront 的联动使用,在我以往的文章说了很多次了,具体可以看:
- web 安全之 - cloudfront 添加 x-frame-options 防止 Clickjacking
- 针对国内和国外的图片资源和缩略图做CDN优化
- 项目使用 aws 的 lambda服务来生成s3的缩略图
这边直接进入实操流程:
1. 创建函数
首先 在 lambda 后台创建一个 lambda 函数: m-addsubfolderaccess
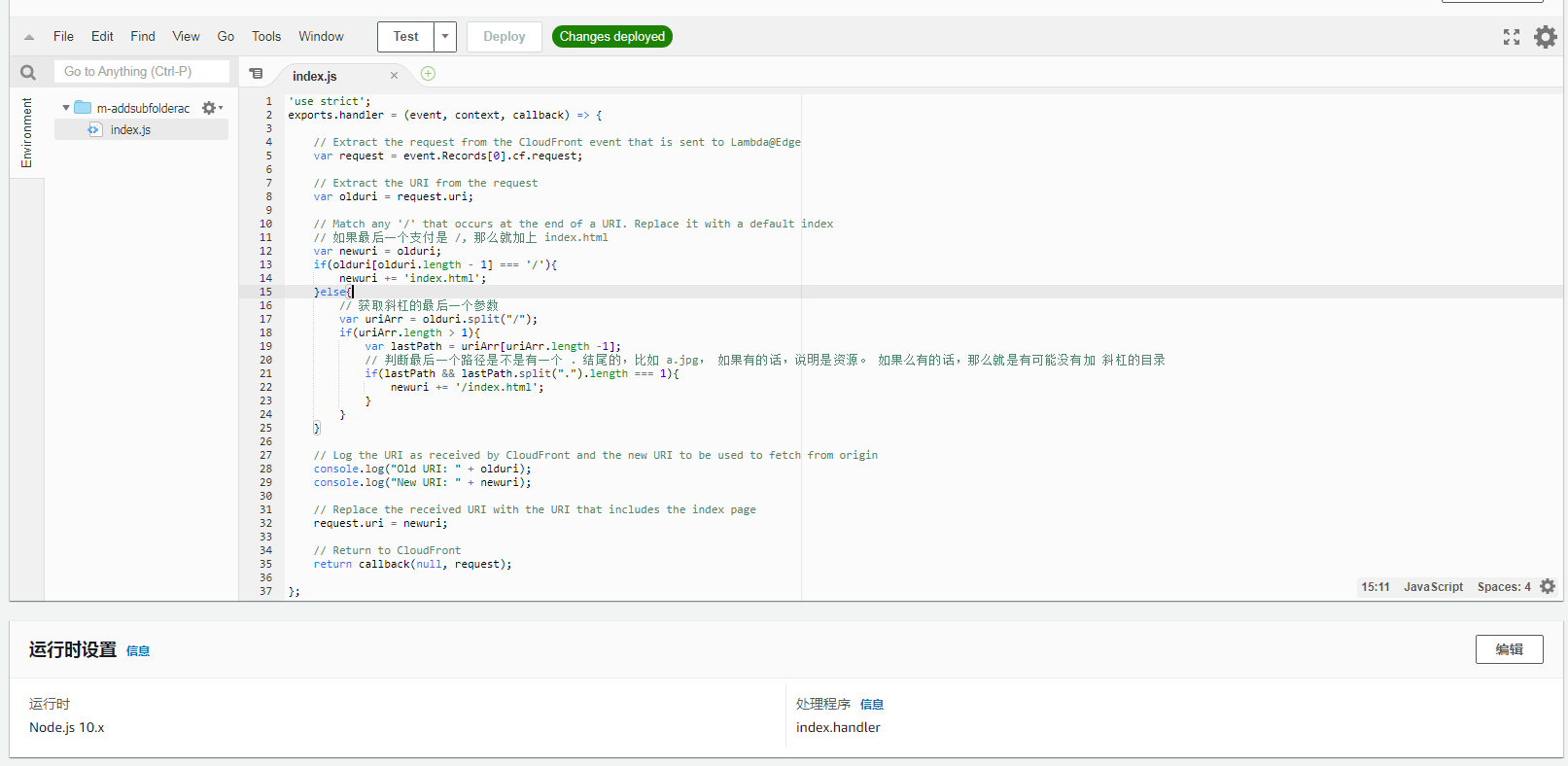
2. 写代码,并保存
然后选择 nodejs 版本,我这边选择的是 10.x, 接下来就开始写代码了1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33'use strict';
exports.handler = (event, context, callback) => {
// Extract the request from the CloudFront event that is sent to Lambda@Edge
var request = event.Records[0].cf.request;
// Extract the URI from the request
var olduri = request.uri;
// Match any '/' that occurs at the end of a URI. Replace it with a default index
// 如果最后一个字符是 /, 那么就加上 index.html
var newuri = olduri;
if(olduri[olduri.length - 1] === '/'){
newuri += 'index.html';
}else{
// 获取斜杠的最后一个参数
var uriArr = olduri.split("/");
if(uriArr.length > 1){
var lastPath = uriArr[uriArr.length -1];
// 判断最后一个路径是不是有一个 . 结尾的,比如 a.jpg, 如果有的话,说明是资源。 如果么有的话,那么就是有可能没有加 斜杠的目录
if(lastPath && lastPath.split(".").length === 1){
newuri += '/index.html';
}
}
}
// Log the URI as received by CloudFront and the new URI to be used to fetch from origin
console.log("Old URI: " + olduri);
console.log("New URI: " + newuri);
// Replace the received URI with the URI that includes the index page
request.uri = newuri;
// Return to CloudFront
return callback(null, request);
};
代码很简单,就是针对当前请求的 uri,根据不同的判断进行重写,主要是判断两种情况:
- 如果最后一个字符是
/, 那么就加上 index.html ,这样子就可以解决子目录没有取默认 index.html 的问题 - 获取最后一个
/后面的字符,如果不存在 “.” 的字符 (说明不是资源,比如1.jpg和a.html, 这边是认为这个站点的合理资源都是以[name].[ext]的方式存在的,如果没有点,说明是一个子目录), 那么我们就认为最后的 path 其实是一个子目录,然后只需要添加/index.html就可以了。
代码写好了,接下来点击上面的 Deploy 按钮,表示保存成功
3. 测试一下代码是否正确
代码写好了,接下来我们跑一下测试是否正确, 首先我们测试第一个逻辑,选择一个 http 的跳转事件,然后将 uri 改成 /cast/,
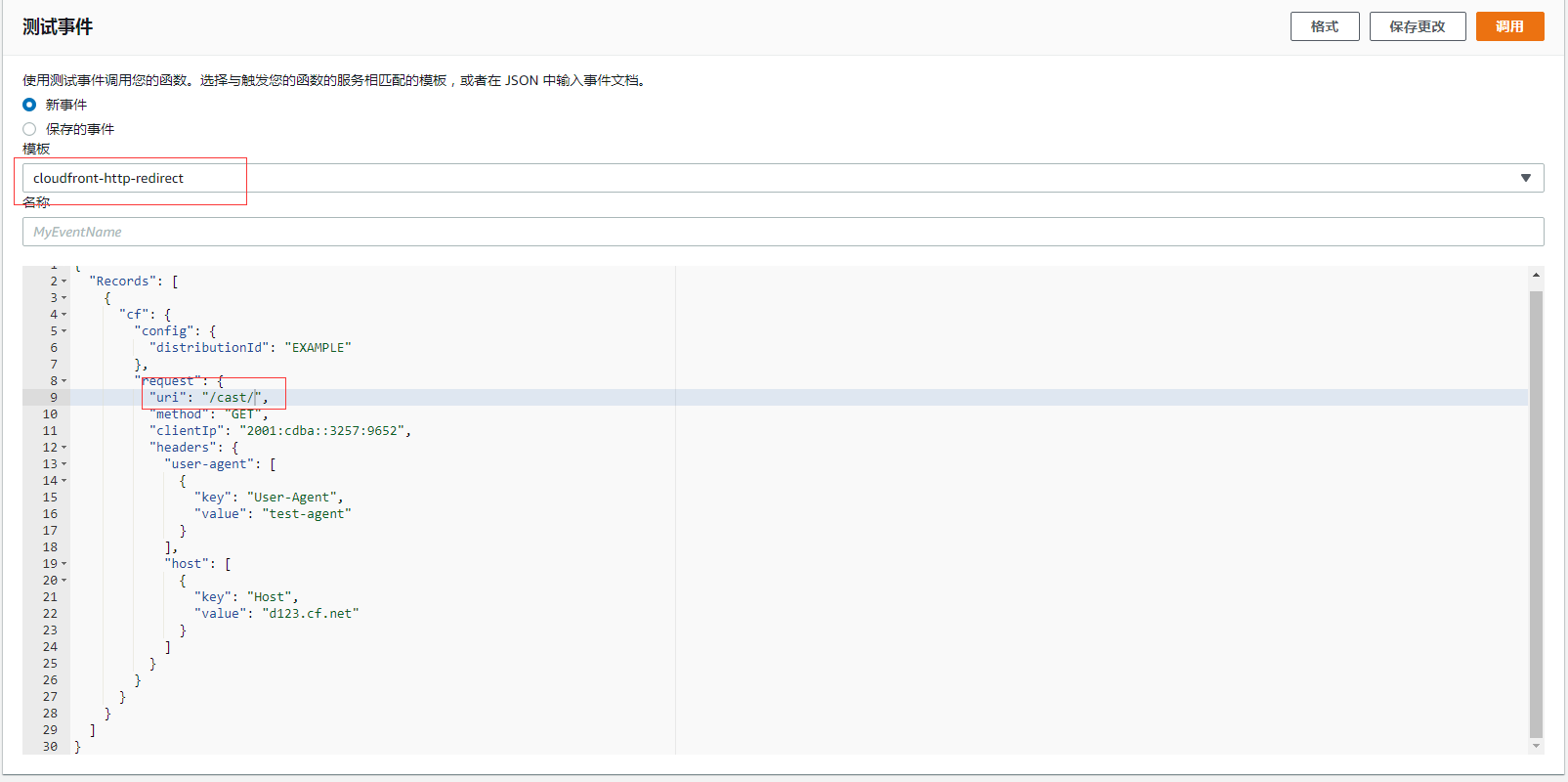
然后点击调用:
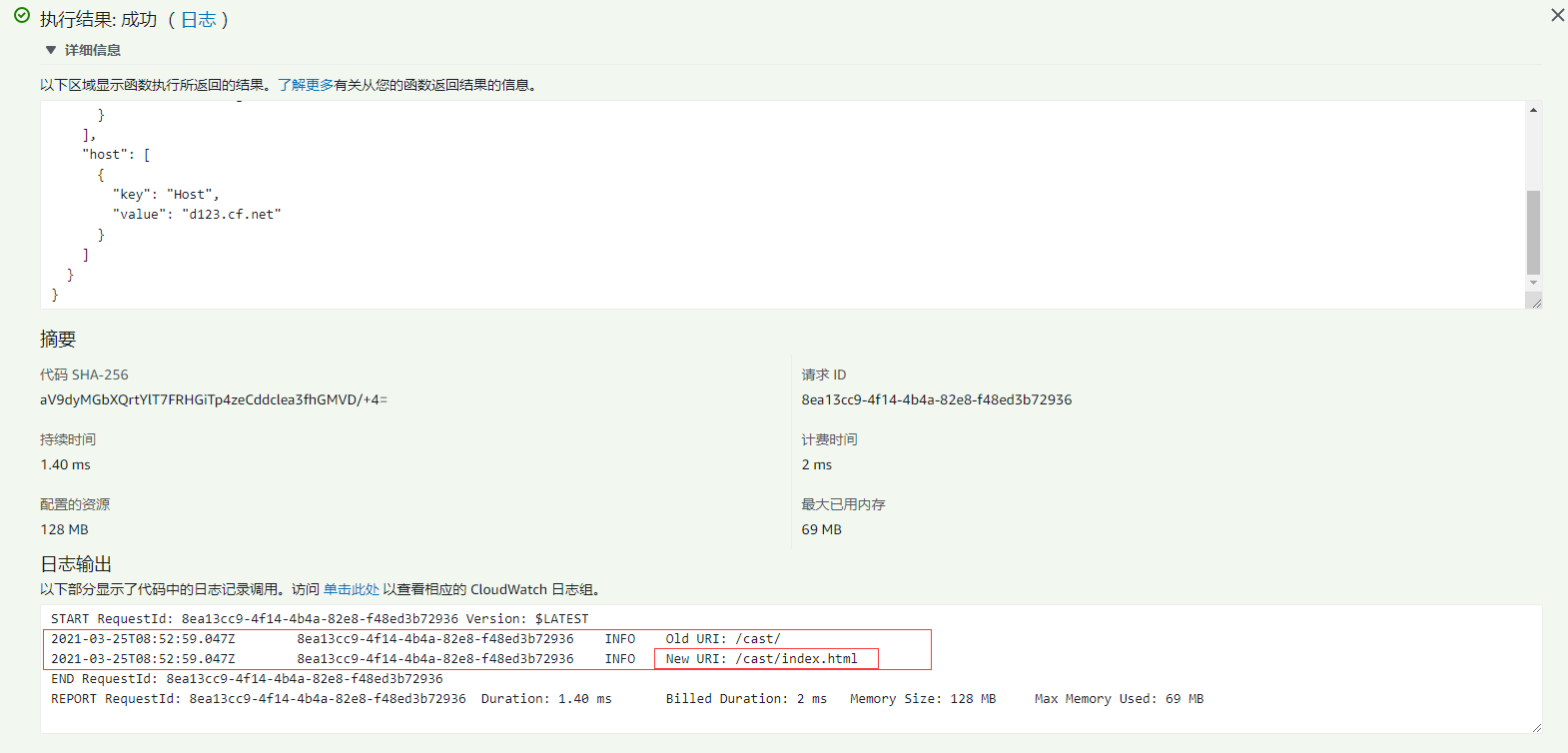
查看执行结果,打印出来的日志 new uri 符合期望是 /cast/index.html, 说明没错。
接下来测试第二种情况,将 uri 改成 /cast :
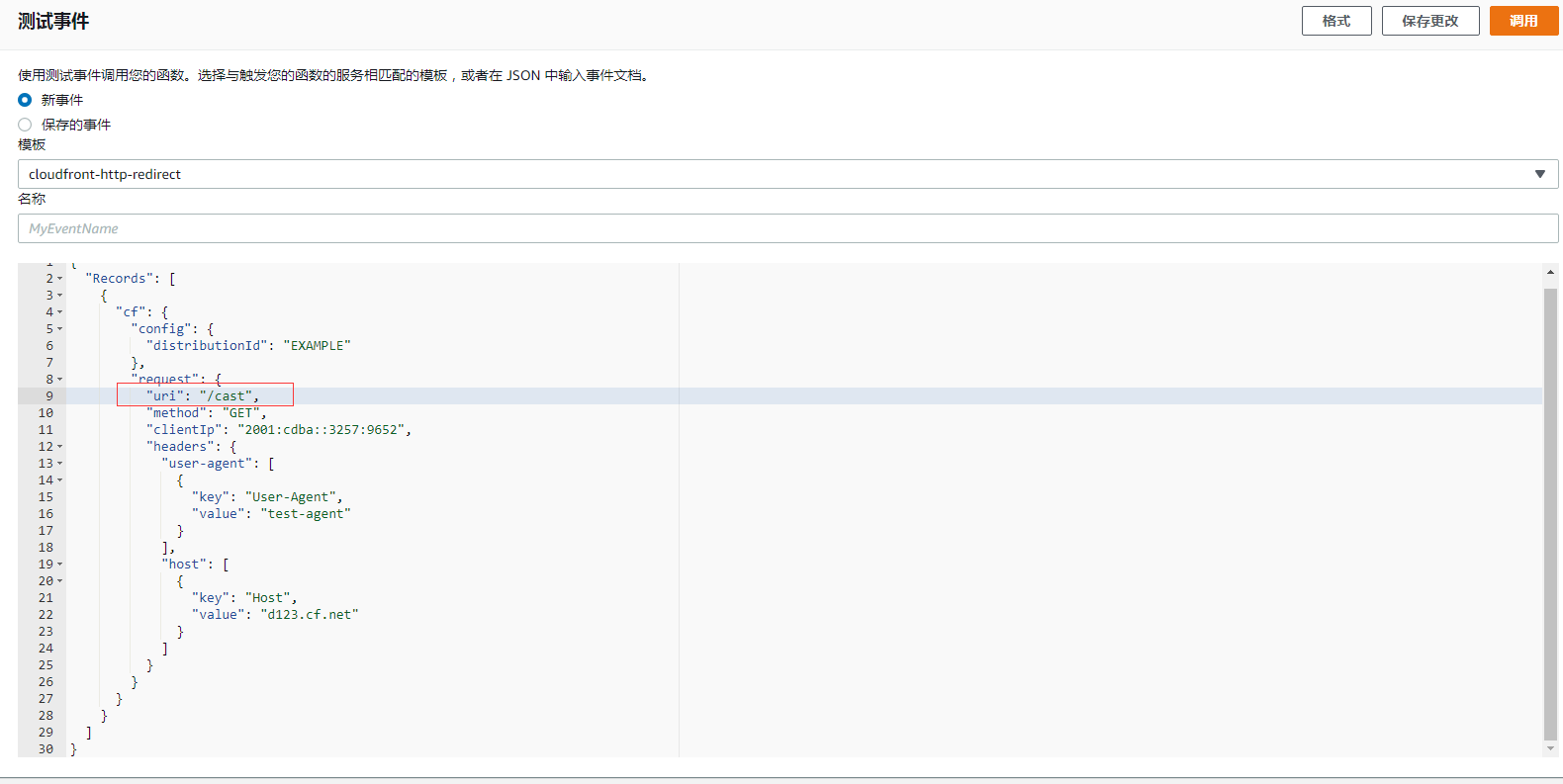
然后点击调用:
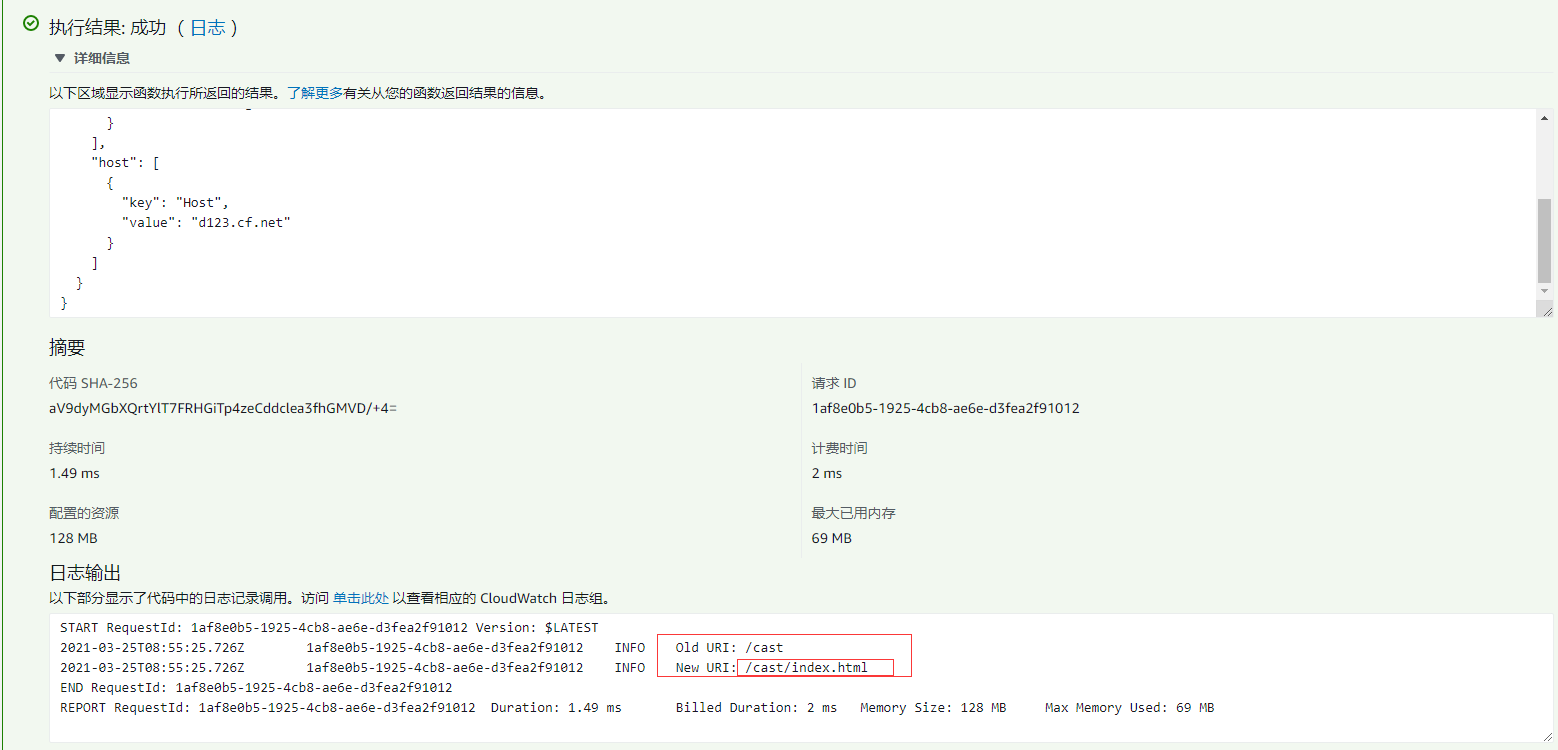
查看执行结果,打印出来的日志 new uri 符合期望是 /cast/index.html, 说明没错。
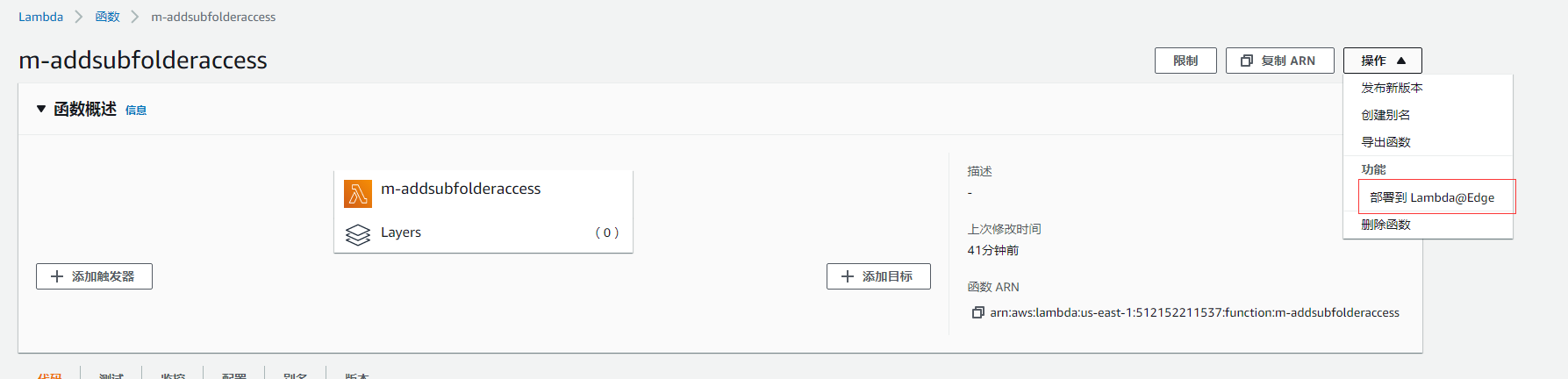
4. 应用到 cloudfront
测试结果正常。接下来我们就要应用到 cloudfront 了, 选择 右上角的 [操作] - [部署到 Lambda@Edge]
选择你想要的这个 cloudfront (一定要选对,不要应用错了), 然后选择 源请求 事件, 因为我们要对请求的 uri 进行重写, 然后点击部署。
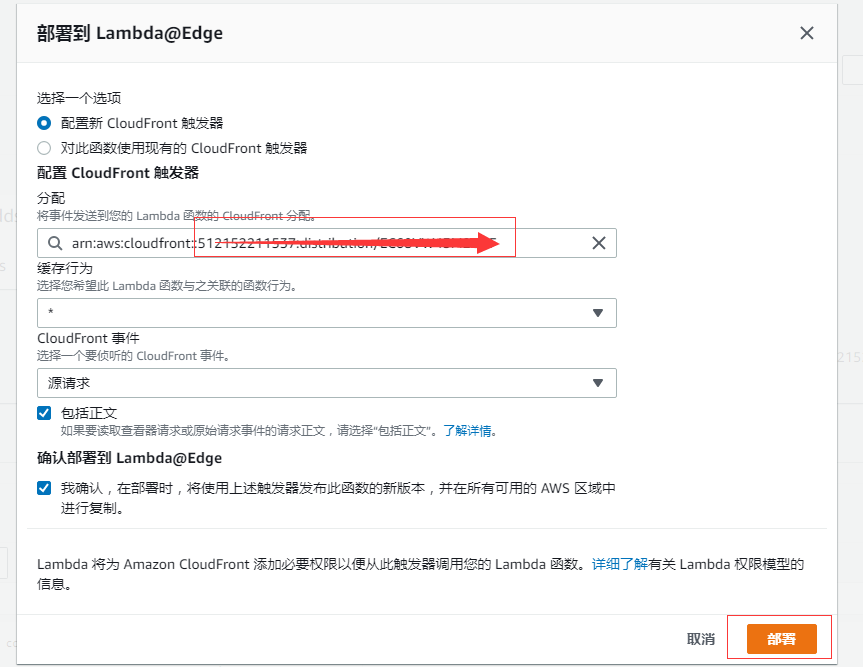
这时候这个 cloudfront 就会重新部署。 大概 5 分钟就可以看效果了。
而且部署的同时,lambda 也会帮我们将这个函数,生成一个新的版本
5. 测试有没有部署生效
等部署完之后,我们就可以重新请求了, 这时候用 curl 请求一下1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16[kbz@VM_16_9_centos ~]$ curl -I https://m.foo.com/cast/
HTTP/1.1 200 OK
Content-Type: text/html
Content-Length: 10754
Connection: keep-alive
Date: Thu, 25 Mar 2021 08:05:34 GMT
Last-Modified: Thu, 28 Jan 2021 06:18:46 GMT
ETag: "93ff430a043037a9452fe191f6b0320b"
Accept-Ranges: bytes
Server: AmazonS3
Strict-Transport-Security: max-age=7776000
X-Cache: Hit from cloudfront
Via: 1.1 cfa15842f57761e1aba6ea8338d380d5.cloudfront.net (CloudFront)
X-Amz-Cf-Pop: SFO20-C1
X-Amz-Cf-Id: 5oaotoHwXoQT197vrn5ORM1dICkGrgAH-5ILwrDcv0ru9bA1VdczRg==
Age: 2521
这时候就是 200 成功,并且有 hit cloudfront 了。 去掉 最后的 / 再试试:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16[kbz@VM_16_9_centos ~]$ curl -I https://m.foo.com/cast
HTTP/1.1 200 OK
Content-Type: text/html
Content-Length: 10754
Connection: keep-alive
Date: Thu, 25 Mar 2021 08:05:38 GMT
Last-Modified: Thu, 28 Jan 2021 06:18:46 GMT
ETag: "93ff430a043037a9452fe191f6b0320b"
Accept-Ranges: bytes
Server: AmazonS3
Strict-Transport-Security: max-age=7776000
X-Cache: Hit from cloudfront
Via: 1.1 88734c1b1a8053ae83daf0f85731c788.cloudfront.net (CloudFront)
X-Amz-Cf-Pop: SFO20-C1
X-Amz-Cf-Id: U6de8MCZwtoS6zyb4lLgDjZCsUkeJa4n_xW9PXLUb8rBL1K-vGvolg==
Age: 2451
说明成功生效了。
6. 代码迭代重新部署要注意
因为有时候我们会需要更新代码,这时候就会有代码版本迭代,并且重新应用部署的情况。
这时候要注意一个细节,就是要把旧版本代码所关联的触发器先删掉, 然后再为新版本的代码,创建一个新的触发器(跟旧的触发器一样的配置即可)并进行关联,最后再部署。
否则就会出现还是会应用之前有绑定触发器的那个版本的代码,也就是并没有应用到新版本代码,导致一直都有缓存。
直接配置 cloudfront 的源域属性
除了上面的 lambda 方式之后, 后面还发现了一种更简单的方式可以获取子目录的根文件
之前之所以不行是因为我们在配置 cloudfront 的源域的时候,选择是 s3 作为存储桶的源域名,比如
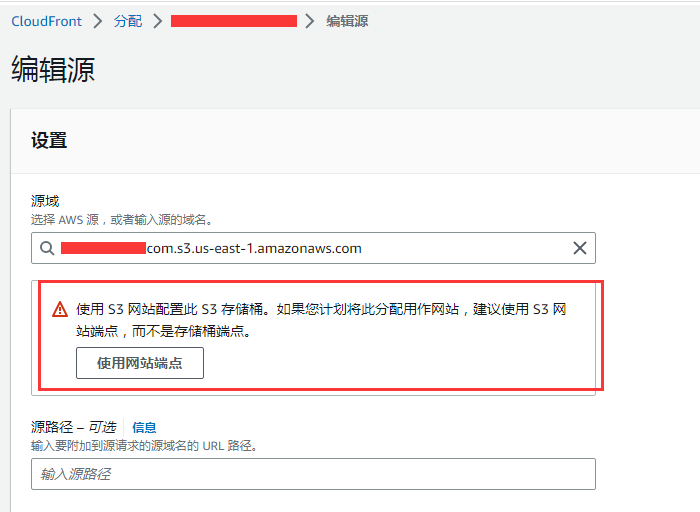
这时候 cloudfront 会提示你是否要将这个源域设置成 S3 存储桶, 还是要设置为 S3 网站端点, 这两种的域名是不一样的,而且效果也不一样。
如果只是当做云端的存储桶,供用户下载文件, 那么就设置为 S3 存储桶,这时候 cloudfront 只有准确匹配到路径,才会获取文件。
如果是当做站点来访问的话,那么就要设置为 S3 网站端点, 这时候 cloudfront 在遇到子目录检索的时候,对于缺省的文件路径,是会默认获取根目录文件的,比如 index.html 这种。
因此对于本例来说,肯定是要设置为 S3 网站端点 才行,也就是点击下面的 使用网站端点
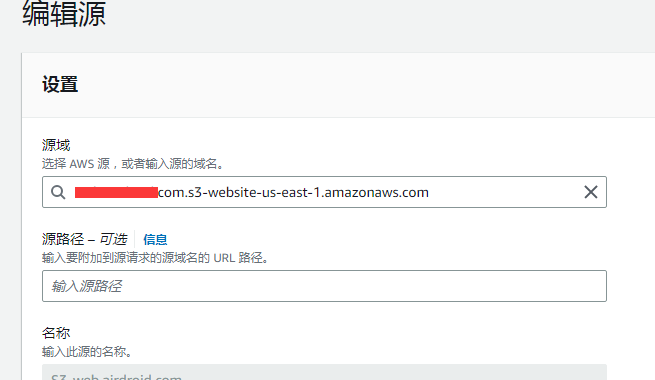
这样子就可以了,就可以访问子目录的根文件了。
参考资料