前言
前段时间有个业务速度变得比较慢,而且有时候会超时,但是开发人员很难跟踪,原因是因为这个业务涉及的到客户端和微服务都比较多,很难去排查到底是哪个环节,因为如果从每一个环节每一个环节看的话,好像有没啥问题,但是确实有时候就是会出现速度慢的情况,而且排查非常的麻烦,因为不同的客户端可能开发人员和开发语言都不太一样,所以就会造成一种情况,就是大家好不容易凑在一起,然后各自看各自端的 log,一直到找到那个时间点的有问题的 log 出来, 偶尔这样子还好,要是经常这样子干,大家都不用干活了,而且很多时候客户端的日志都在用户那边,有时候根本就没法给到。
基于以上这种情况,我们服务端就需要有一种服务来跟踪多个微服务之间的分布式全链路传输情况。
APM 简介
关于什么是 APM, 有一篇文章我觉得讲的挺好的: APM 原理与框架选型,文章讲了很多关于 APM 的基础知识, 以下是部分摘录:
随着微服务架构的流行,一次请求往往需要涉及到多个服务,因此服务性能监控和排查就变得更复杂:
- 不同的服务可能由不同的团队开发、甚至可能使用不同的编程语言来实现
- 服务有可能布在了几千台服务器,横跨多个不同的数据中心
因此,就需要一些可以帮助理解系统行为、用于分析性能问题的工具,以便发生故障的时候,能够快速定位和解决问题,
这就是APM系统,全称是(Application Performance Monitor,当然也有叫 Application Performance Management tools)AMP最早是谷歌公开的论文提到的 Google Dapper。Dapper是Google生产环境下的分布式跟踪系统,
自从Dapper发展成为一流的监控系统之后,给google的开发者和运维团队帮了大忙,所以谷歌公开论文分享了Dapper。
没办法讲的更好了,而且本文也不是科普文,而是注重操作的实践文。
这东西其实也不稀奇,通俗的来说,APM 就是跟踪一个 traceId 在多个微服务中的传递并记录。在进入第一个服务的时候,就生成一个 traceId,接下来这个 traceId 将跟随整个微服务调用链,一直到整个调用链结束, 后面我们只需要分析这个 traceId 记录的服务和时间, 就可以知道在哪些服务停留了多少时间, 总的用了多少时间。
tracer 和 span
虽然不是科普文, 但是这两个概念也绕不过去, 所以就简单介绍一下, 更详细的请看文后的参考文档,那个就很详细。
tracer
在广义上,一个trace代表了一个事务或者流程在(分布式)系统中的执行过程。trace 是多个 span组成的一个有向无环图(DAG),每一个span代表trace中被命名并计时的连续性的执行片段。
span
一个span代表系统中具有开始时间和执行时长的逻辑运行单元。span之间通过嵌套或者顺序排列建立逻辑因果关系。
关系
分布式追踪中的每个组件都包含自己的一个或者多个span。例如,在一个常规的RPC调用过程中,在RPC的客户端和服务端,至少各有一个span,用于记录RPC调用的客户端和服务端信息。
一个父级的span会显示的并行或者串行启动多个子span。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15一个 tracer 过程中,各span的关系
[Span A] ←←←(the root span)
|
+------+------+
| |
[Span B] [Span C] ←←←(Span C 是 Span A 的孩子节点, ChildOf)
| |
[Span D] +---+-------+
| |
[Span E] [Span F] >>> [Span G] >>> [Span H]
↑
↑
↑
(Span G 在 Span F 后被调用, FollowsFrom)
1 | tracer 与 span 的时间轴关系 |
traceId
假设服务调用关系为 a->b->c->d,请求从 a 开始发起。 那么 a 负责生成 traceId,并在调用 b 的时候把 traceId 传递给 b,以此类推,traceId 会从 a 层层传递到 d。
这个 traceId 长这样: {root span id}:{this span id}:{parent span id}:{flag} 。假设 a 是请求发起者,flag 固定为1,那么 a,b,c,d 的 traceId 分别是:
a_span_id:a_span_id:0:1a_span_id:b_span_id:a_span_id:1a_span_id:c_span_id:b_span_id:1a_span_id:d_span_id:c_span_id:1
jaeger
市面上的 AMP 工具很多,最早就是 google 的 Dapper,Dapper是Google生产环境下的分布式跟踪系统,自从Dapper发展成为一流的监控系统之后,给google的开发者和运维团队帮了大忙,所以谷歌公开论文分享了Dapper。
市面上关于 AMP 的产品很多,除了 Uber 的 jaeger 和 Twitter 的 zipkin, 国内也有类似的产品, 比如阿里的鹰眼或者是京东的 hydra。 可以对比一下:
| 能力项 | 鹰眼(EagleEye) | zipkin | jaeger |
|---|---|---|---|
| 开发团队 | 阿里巴巴 | 由Twitter公司开源目前由spring社区维护 | Uber工程团队 |
| 是否开源 | 否 | 是 | 是 |
| OpenTracing | 是 | 是 | 是 |
| 语言支持 | java | Go,Java,Ruby,C++,Python(progress) | Python,go,Node,java,C++,C#,PHP,Ruby |
| 存储 | HDFSHbase | 内存,Cassandra,Elasticsearch | 内存,Cassandra,Elasticsearch |
| Span 传输 | HTTP,UDP | HTTP,kafka | utp,http |
| 易用性 | 简单易接入,主要是java语言 | 少数语言支持差,如:Python | 接入简单,各种语言sdk丰富 |
而我们团队之所以选择 jaeger,一方面是因为它有 CNCF 支持,又是 golang 语言开发的, 而 golang 语言又是我们的主要开发语言。 上手也比较快。
主要流程图:
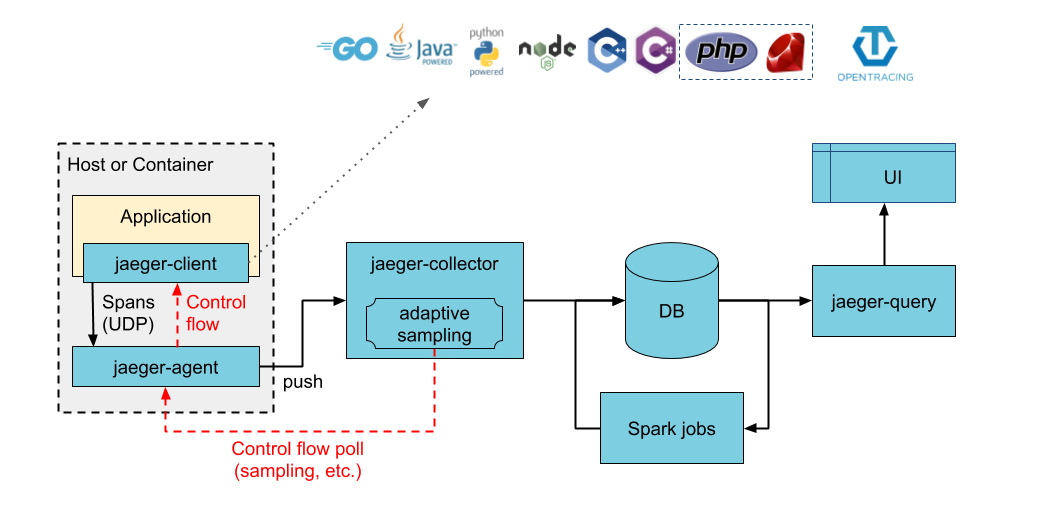
jaeger 其实由多个组件组成,有些是必须的,有些不是。
| component | / |
|---|---|
| jaeger-client | 代码接入的 jaegerClient。 比如 go 服务接入 github.com/uber/jaeger-client-go ,php 服务接入 github.com/jukylin/jaeger-php |
| jaeger-agent | jaeger-client 会把 span 上报给 jaeger-agent,这个 aegent 最好和 jaeger-client 部署在同一台服务器,离得近上报也快,否则可能会因为上报数据反而拖累业务 |
| jaeger-collector | 负责从 jaeger-agent 那里拿数据的服务, 有 push /pull 两种方式。 |
| storage | jaeger-collector 拿到的数据存储的地方,可以选 es 或者 cassandra。 |
| jaeger-query | 负责从 storage 查询数据 |
docker 安装 all-in-one
虽然 jaeger 由那么多个组件组成, 但是他还是有提供一个全家桶可以用来进行测试用 jaeger-all-in-one, 当然生产环境肯定不能这样子做,不过我们主要是用来学习用,为了简单,直接用 docker 安装即可1
docker run -d -p 6831:6831/udp -p 16686:16686 jaegertracing/all-in-one:latest
1 | [root@VM_156_200_centos ~]# docker run -d -p 6831:6831/udp -p 16686:16686 jaegertracing/all-in-one:latest |
这样子就装好了,并且服务已经启动了,其中 agent 的端口是 6831, 这个后面写代码的时候,要连的就是这个服务, 另一个端口 16686 就是前端的 web 查询界面
demo 学习
既然服务跑起来了,那么接下来就是怎么在项目里面应用了。 学习技术最快的途径就是直接跑代码了,我在 opentracing-tutorial 找到几个 go 的 demo, 刚好循循渐进, 非常适合新手学习。
我们将这个项目 git clone 下来。直接跟着学习
demo 1 hello world
首先还是从 hello world 学起, 具体文档看: Lesson 1 - Hello World, 就一个 hello.go 文件:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34package main
import (
"fmt"
"os"
"github.com/opentracing/opentracing-go/log"
"github.com/yurishkuro/opentracing-tutorial/go/lib/tracing"
)
func main() {
if len(os.Args) != 2 {
panic("ERROR: Expecting one argument")
}
tracer, closer := tracing.Init("hello-world")
defer closer.Close()
helloTo := os.Args[1]
span := tracer.StartSpan("say-hello")
span.SetTag("hello-to", helloTo)
helloStr := fmt.Sprintf("Hello, %s!", helloTo)
span.LogFields(
log.String("event", "string-format"),
log.String("value", helloStr),
)
println(helloStr)
span.LogKV("event", "println")
span.Finish()
}
代码其实非常简单,就是输入一个名字,然后标记一个 tag。 我们可以看到代码里面他有调用一个 tracing 的包来初始化,这个包的内容也很简单,就是初始化 jaeger agent 的连接,并且设置追踪的 service 服务名,最后返回 trace 对象, 具体代码 tracing.go:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29package tracing
import (
"fmt"
"io"
opentracing "github.com/opentracing/opentracing-go"
jaeger "github.com/uber/jaeger-client-go"
config "github.com/uber/jaeger-client-go/config"
)
// Init returns an instance of Jaeger Tracer that samples 100% of traces and logs all spans to stdout.
func Init(service string) (opentracing.Tracer, io.Closer) {
cfg := &config.Configuration{
ServiceName: service,
Sampler: &config.SamplerConfig{
Type: "const",
Param: 1,
},
Reporter: &config.ReporterConfig{
LogSpans: true,
},
}
tracer, closer, err := cfg.NewTracer(config.Logger(jaeger.StdLogger))
if err != nil {
panic(fmt.Sprintf("ERROR: cannot init Jaeger: %v\n", err))
}
return tracer, closer
}
将项目跑起来:1
2
3
4
5
6[root@VM_156_200_centos solution]# go run hello.go zachke
2020/12/25 14:44:00 debug logging disabled
2020/12/25 14:44:00 Initializing logging reporter
2020/12/25 14:44:00 debug logging disabled
Hello, zachke!
2020/12/25 14:44:00 Reporting span 66d07e5957d58ad4:66d07e5957d58ad4:0000000000000000:1
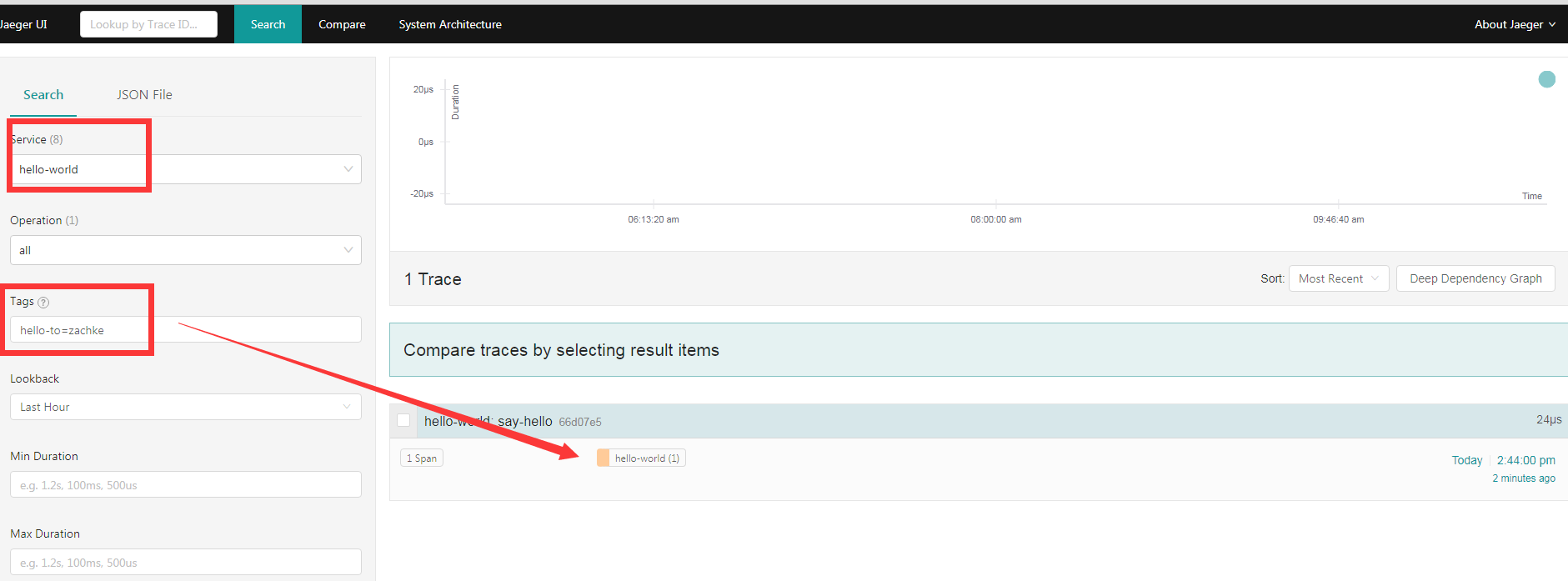
好,这样子就执行完了,接下来我们到 jaeger 后台查看这一个追踪, 找到 service 名称为 hello-world, 并且 tag 是 hello-to=zach, 然后点击查询,就可以看到有数据了
点进去详情,可以查看他记录的 log
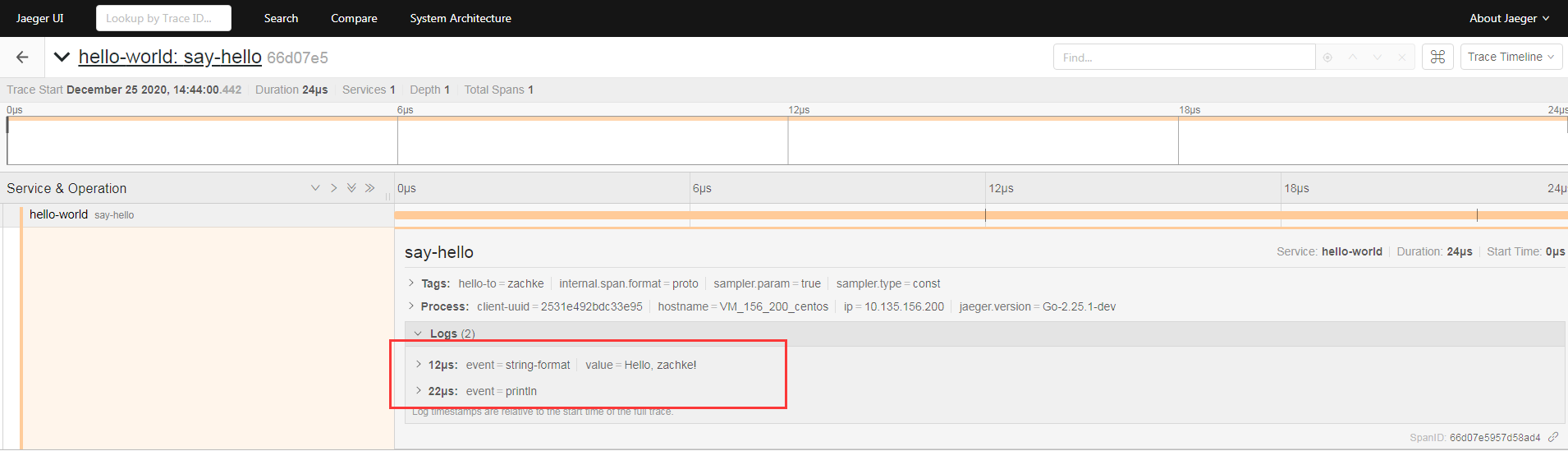
这样子,一条最简单的调用链就完成了。 不过可以看到他只有一个 root span 标签。 那其实没啥意义。 不过凡事都是一步一步来,不着急。
demo 2 multiple span
接下来我们基于上面的那个 demo 再扩展一下, 使用多个 span 标签, 具体文档: Lesson 2 - Context and Tracing Functions, 其实就是在原来的基础上增加了两个方法 formatString 和 formatString, 代码如下 hello.go:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53package main
import (
"context"
"fmt"
"os"
"github.com/opentracing/opentracing-go"
"github.com/opentracing/opentracing-go/log"
"github.com/yurishkuro/opentracing-tutorial/go/lib/tracing"
)
func main() {
if len(os.Args) != 2 {
panic("ERROR: Expecting one argument")
}
tracer, closer := tracing.Init("hello-world")
defer closer.Close()
opentracing.SetGlobalTracer(tracer)
helloTo := os.Args[1]
span := tracer.StartSpan("say-hello")
span.SetTag("hello-to", helloTo)
defer span.Finish()
ctx := opentracing.ContextWithSpan(context.Background(), span)
helloStr := formatString(ctx, helloTo)
printHello(ctx, helloStr)
}
func formatString(ctx context.Context, helloTo string) string {
span, _ := opentracing.StartSpanFromContext(ctx, "formatString")
defer span.Finish()
helloStr := fmt.Sprintf("Hello, %s!", helloTo)
span.LogFields(
log.String("event", "string-format"),
log.String("value", helloStr),
)
return helloStr
}
func printHello(ctx context.Context, helloStr string) {
span, _ := opentracing.StartSpanFromContext(ctx, "printHello")
defer span.Finish()
println(helloStr)
span.LogKV("event", "println")
}
还是一样跑起来:1
2
3
4
5
6
7
8
9
[root@VM_156_200_centos solution]# go run hello.go zachke
2020/12/25 14:54:12 debug logging disabled
2020/12/25 14:54:12 Initializing logging reporter
2020/12/25 14:54:12 debug logging disabled
2020/12/25 14:54:12 Reporting span 0f9edea1d58bb0b3:5a3f738561501a22:0f9edea1d58bb0b3:1
Hello, zachke!
2020/12/25 14:54:12 Reporting span 0f9edea1d58bb0b3:2604e0bf070e6c85:0f9edea1d58bb0b3:1
2020/12/25 14:54:12 Reporting span 0f9edea1d58bb0b3:0f9edea1d58bb0b3:0000000000000000:1
接下来看一下, 对应的调用链:
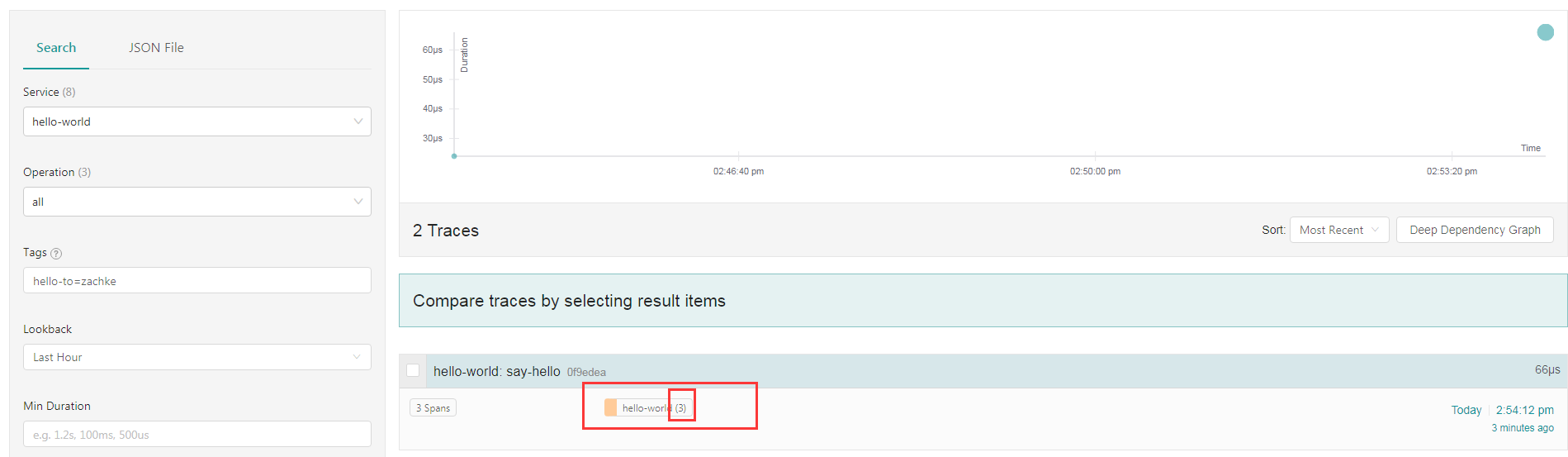
可以看到虽然还是只有个 service 服务,但是这个 service 服务里面有三个 span 标签了, 点进去
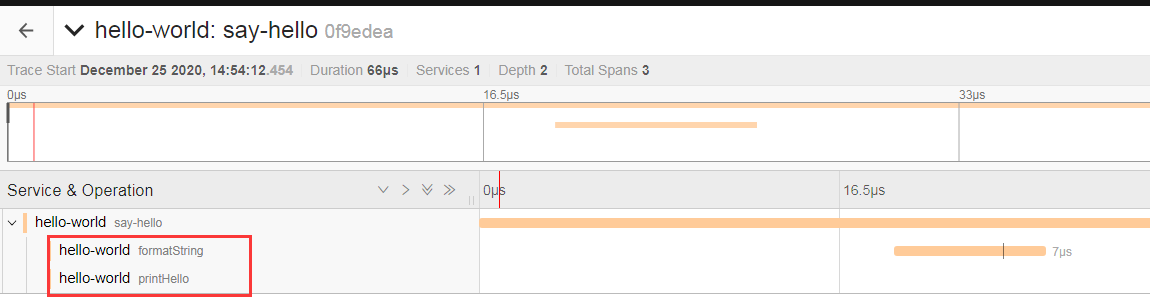
可以看到除了最刚开始的 root span, 还多了两个 child span, 分别表示这个服务的两个重要操作 formatString 和 formatString
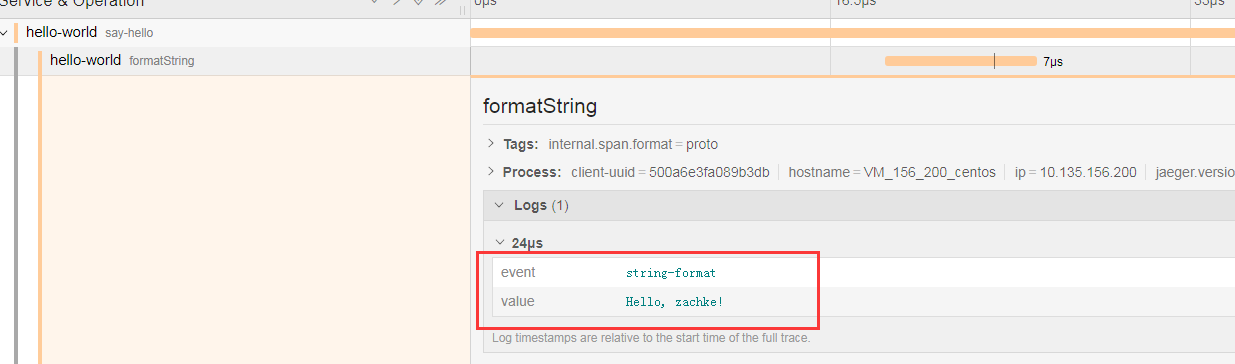
对应的 log 还是一样有的。 所以这些 child span,其实就是对应的这个 service 服务中的一些重要操作, 大部分都是需要耗时的操作,比如 文件 io 读写,数据库读写 类似的操作。
demo 3 multiple service
上面的调用链都是只有一个 service 服务, 正常情况一个业务情况,经常会涉及到多个微服务的请求。 本例就是用来模拟在多个微服务的调用链怎么去跟踪, 具体文档: Lesson 3 - Tracing RPC Requests
大致的逻辑是这样子: 还是基于 demo2 的入口, 只不过这次他的两个操作 formatString 和 printHello 会再去请求另外两个服务 service-formatter 和 service-publisher, 具体代码如下: hello.go:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95package main
import (
"context"
"net/http"
"net/url"
"os"
"github.com/opentracing/opentracing-go"
"github.com/opentracing/opentracing-go/ext"
"github.com/opentracing/opentracing-go/log"
xhttp "github.com/yurishkuro/opentracing-tutorial/go/lib/http"
"github.com/yurishkuro/opentracing-tutorial/go/lib/tracing"
)
func main() {
if len(os.Args) != 2 {
panic("ERROR: Expecting one argument")
}
tracer, closer := tracing.Init("hello-world")
defer closer.Close()
opentracing.SetGlobalTracer(tracer)
helloTo := os.Args[1]
span := tracer.StartSpan("say-hello")
span.SetTag("hello-to", helloTo)
defer span.Finish()
ctx := opentracing.ContextWithSpan(context.Background(), span)
helloStr := formatString(ctx, helloTo)
printHello(ctx, helloStr)
}
func formatString(ctx context.Context, helloTo string) string {
span, _ := opentracing.StartSpanFromContext(ctx, "formatString")
defer span.Finish()
v := url.Values{}
v.Set("helloTo", helloTo)
url := "http://localhost:8081/format?" + v.Encode()
req, err := http.NewRequest("GET", url, nil)
if err != nil {
panic(err.Error())
}
ext.SpanKindRPCClient.Set(span)
ext.HTTPUrl.Set(span, url)
ext.HTTPMethod.Set(span, "GET")
span.Tracer().Inject(
span.Context(),
opentracing.HTTPHeaders,
opentracing.HTTPHeadersCarrier(req.Header),
)
resp, err := xhttp.Do(req)
if err != nil {
ext.LogError(span, err)
panic(err.Error())
}
helloStr := string(resp)
span.LogFields(
log.String("event", "string-format"),
log.String("value", helloStr),
)
return helloStr
}
func printHello(ctx context.Context, helloStr string) {
span, _ := opentracing.StartSpanFromContext(ctx, "printHello")
defer span.Finish()
v := url.Values{}
v.Set("helloStr", helloStr)
url := "http://localhost:8082/publish?" + v.Encode()
req, err := http.NewRequest("GET", url, nil)
if err != nil {
panic(err.Error())
}
ext.SpanKindRPCClient.Set(span)
ext.HTTPUrl.Set(span, url)
ext.HTTPMethod.Set(span, "GET")
span.Tracer().Inject(span.Context(), opentracing.HTTPHeaders, opentracing.HTTPHeadersCarrier(req.Header))
if _, err := xhttp.Do(req); err != nil {
ext.LogError(span, err)
panic(err.Error())
}
}
formatter.go:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33package main
import (
"fmt"
"log"
"net/http"
opentracing "github.com/opentracing/opentracing-go"
"github.com/opentracing/opentracing-go/ext"
otlog "github.com/opentracing/opentracing-go/log"
"github.com/yurishkuro/opentracing-tutorial/go/lib/tracing"
)
func main() {
tracer, closer := tracing.Init("formatter")
defer closer.Close()
http.HandleFunc("/format", func(w http.ResponseWriter, r *http.Request) {
spanCtx, _ := tracer.Extract(opentracing.HTTPHeaders, opentracing.HTTPHeadersCarrier(r.Header))
span := tracer.StartSpan("format", ext.RPCServerOption(spanCtx))
defer span.Finish()
helloTo := r.FormValue("helloTo")
helloStr := fmt.Sprintf("Hello, %s!", helloTo)
span.LogFields(
otlog.String("event", "string-format"),
otlog.String("value", helloStr),
)
w.Write([]byte(helloStr))
})
log.Fatal(http.ListenAndServe(":8081", nil))
}
publisher.go:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26package main
import (
"log"
"net/http"
opentracing "github.com/opentracing/opentracing-go"
"github.com/opentracing/opentracing-go/ext"
"github.com/yurishkuro/opentracing-tutorial/go/lib/tracing"
)
func main() {
tracer, closer := tracing.Init("publisher")
defer closer.Close()
http.HandleFunc("/publish", func(w http.ResponseWriter, r *http.Request) {
spanCtx, _ := tracer.Extract(opentracing.HTTPHeaders, opentracing.HTTPHeadersCarrier(r.Header))
span := tracer.StartSpan("publish", ext.RPCServerOption(spanCtx))
defer span.Finish()
helloStr := r.FormValue("helloStr")
println(helloStr)
})
log.Fatal(http.ListenAndServe(":8082", nil))
}
接下来分别将另外两个服务 formatter 和 publisher 启动起来:1
2
3
4[root@VM_156_200_centos formatter]# go run formatter.go
2020/12/25 15:11:20 debug logging disabled
2020/12/25 15:11:20 Initializing logging reporter
2020/12/25 15:11:20 debug logging disabled
1 | [root@VM_156_200_centos publisher]# go run publisher.go |
接下来执行 hello.go:1
2
3
4
5
6
7[root@VM_156_200_centos client]# go run hello.go zachke
2020/12/25 15:12:43 debug logging disabled
2020/12/25 15:12:43 Initializing logging reporter
2020/12/25 15:12:43 debug logging disabled
2020/12/25 15:12:43 Reporting span 1ecee6ee8ac2bc88:6a35eae8af0db1d1:1ecee6ee8ac2bc88:1
2020/12/25 15:12:43 Reporting span 1ecee6ee8ac2bc88:73eac4d8a4be8086:1ecee6ee8ac2bc88:1
2020/12/25 15:12:43 Reporting span 1ecee6ee8ac2bc88:1ecee6ee8ac2bc88:0000000000000000:1
执行完之后, publisher 服务就会多这个输出:1
2
3
4
5
6[root@VM_156_200_centos publisher]# go run publisher.go
2020/12/25 15:11:47 debug logging disabled
2020/12/25 15:11:47 Initializing logging reporter
2020/12/25 15:11:47 debug logging disabled
Hello, zachke!
2020/12/25 15:12:43 Reporting span 1ecee6ee8ac2bc88:538a03f15661c08a:73eac4d8a4be8086:1
接下来看一下后台的调用链, 可以看到它在调用其他服务的时候,是将 trace 相关的信息都放到 header 中, 通过 inject 函数注入1
span.Tracer().Inject(span.Context(), opentracing.HTTPHeaders, opentracing.HTTPHeadersCarrier(req.Header))
然后对接的服务就会在 header 中将 trace 信息取出来, 通过 extract 导出1
spanCtx, _ := tracer.Extract(opentracing.HTTPHeaders, opentracing.HTTPHeadersCarrier(r.Header))
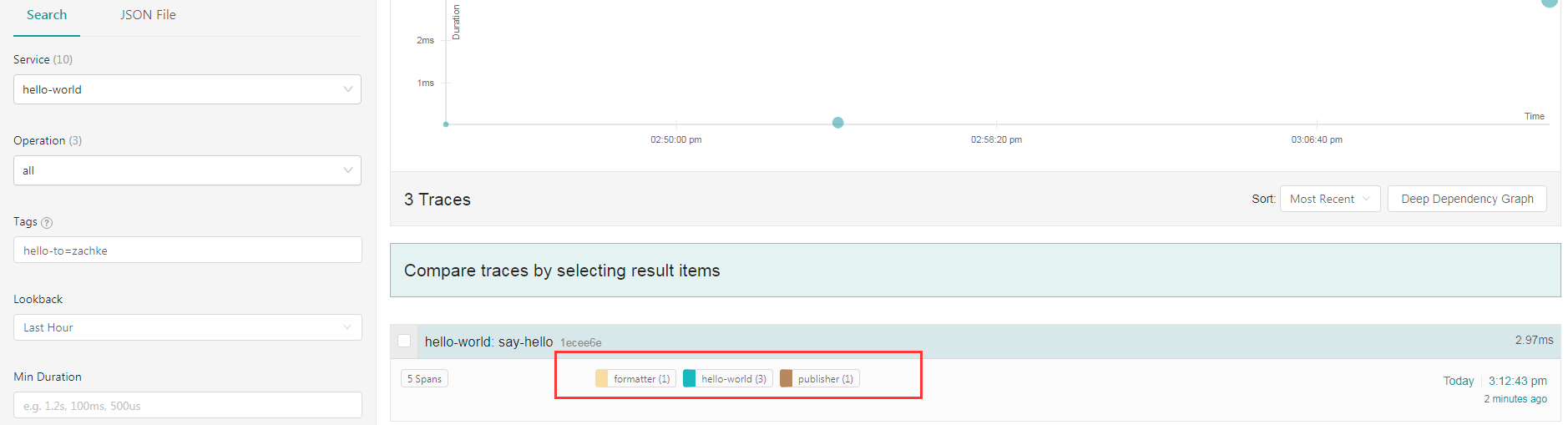
这时候可以看到有三个 service 服务的 span 标签了, 点进去详情
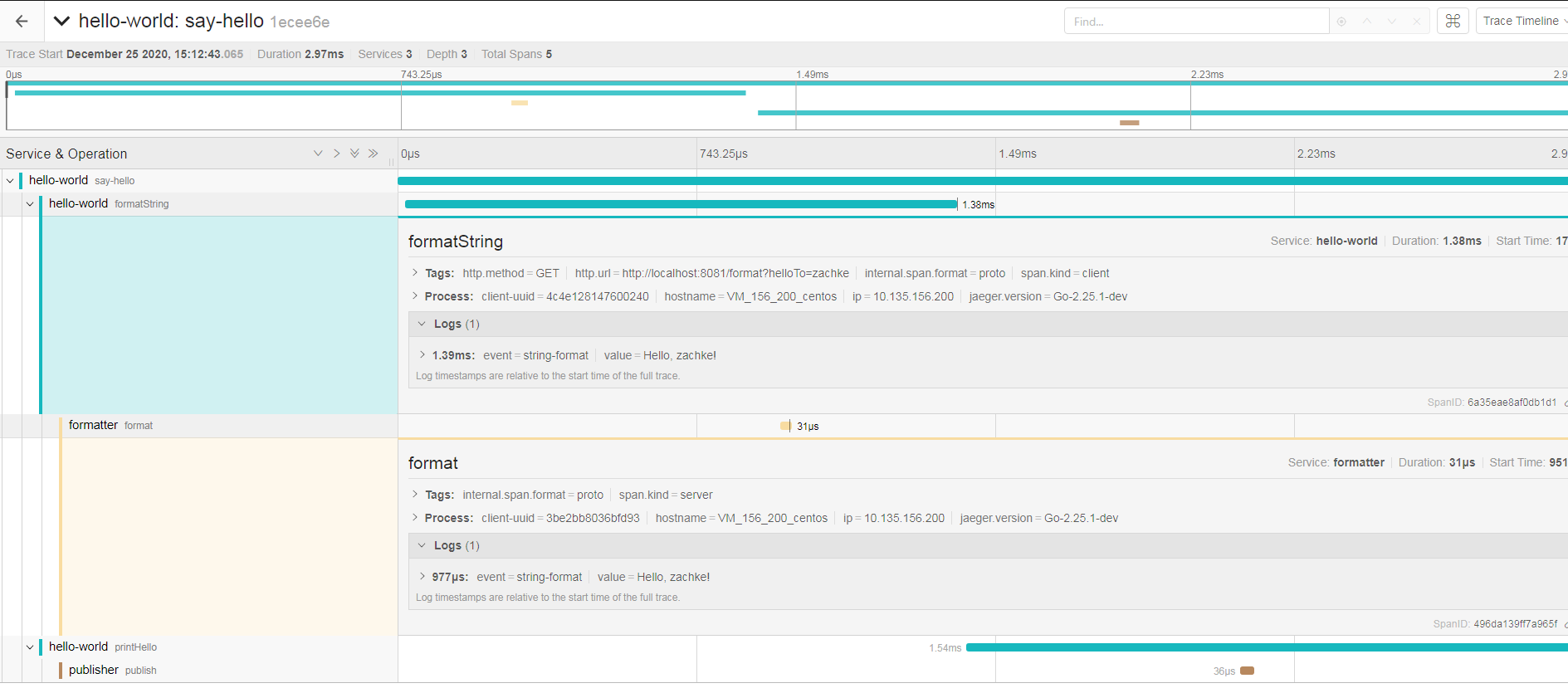
demo 4 Baggage
接下来的这个练习是关于 baggage 参数, baggage 顾名思义 就是 行李。 他会随着调用链一起往下一个调用链运行,就像坐飞机一样,如果要转机的话,那么携带的行李也要跟着一起转。 具体文档: Lesson 4 - Baggage
基于 demo3 的例子,我们做个调整, 增加 baggage 参数的设置1
span.SetBaggageItem("greeting", greeting)
具体看代码: hello.go:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97package main
import (
"context"
"net/http"
"net/url"
"os"
"github.com/opentracing/opentracing-go"
"github.com/opentracing/opentracing-go/ext"
"github.com/opentracing/opentracing-go/log"
xhttp "github.com/yurishkuro/opentracing-tutorial/go/lib/http"
"github.com/yurishkuro/opentracing-tutorial/go/lib/tracing"
)
func main() {
if len(os.Args) != 3 {
panic("ERROR: Expecting two arguments")
}
tracer, closer := tracing.Init("hello-world")
defer closer.Close()
opentracing.SetGlobalTracer(tracer)
helloTo := os.Args[1]
greeting := os.Args[2]
span := tracer.StartSpan("say-hello")
span.SetTag("hello-to", helloTo)
span.SetBaggageItem("greeting", greeting)
defer span.Finish()
ctx := opentracing.ContextWithSpan(context.Background(), span)
helloStr := formatString(ctx, helloTo)
printHello(ctx, helloStr)
}
func formatString(ctx context.Context, helloTo string) string {
span, _ := opentracing.StartSpanFromContext(ctx, "formatString")
defer span.Finish()
v := url.Values{}
v.Set("helloTo", helloTo)
url := "http://localhost:8081/format?" + v.Encode()
req, err := http.NewRequest("GET", url, nil)
if err != nil {
panic(err.Error())
}
ext.SpanKindRPCClient.Set(span)
ext.HTTPUrl.Set(span, url)
ext.HTTPMethod.Set(span, "GET")
span.Tracer().Inject(
span.Context(),
opentracing.HTTPHeaders,
opentracing.HTTPHeadersCarrier(req.Header),
)
resp, err := xhttp.Do(req)
if err != nil {
ext.LogError(span, err)
panic(err.Error())
}
helloStr := string(resp)
span.LogFields(
log.String("event", "string-format"),
log.String("value", helloStr),
)
return helloStr
}
func printHello(ctx context.Context, helloStr string) {
span, _ := opentracing.StartSpanFromContext(ctx, "printHello")
defer span.Finish()
v := url.Values{}
v.Set("helloStr", helloStr)
url := "http://localhost:8082/publish?" + v.Encode()
req, err := http.NewRequest("GET", url, nil)
if err != nil {
panic(err.Error())
}
ext.SpanKindRPCClient.Set(span)
ext.HTTPUrl.Set(span, url)
ext.HTTPMethod.Set(span, "GET")
span.Tracer().Inject(span.Context(), opentracing.HTTPHeaders, opentracing.HTTPHeadersCarrier(req.Header))
if _, err := xhttp.Do(req); err != nil {
ext.LogError(span, err)
panic(err.Error())
}
}
formatter.go:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38package main
import (
"fmt"
"log"
"net/http"
opentracing "github.com/opentracing/opentracing-go"
"github.com/opentracing/opentracing-go/ext"
otlog "github.com/opentracing/opentracing-go/log"
"github.com/yurishkuro/opentracing-tutorial/go/lib/tracing"
)
func main() {
tracer, closer := tracing.Init("formatter")
defer closer.Close()
http.HandleFunc("/format", func(w http.ResponseWriter, r *http.Request) {
spanCtx, _ := tracer.Extract(opentracing.HTTPHeaders, opentracing.HTTPHeadersCarrier(r.Header))
span := tracer.StartSpan("format", ext.RPCServerOption(spanCtx))
defer span.Finish()
greeting := span.BaggageItem("greeting")
if greeting == "" {
greeting = "Hello"
}
helloTo := r.FormValue("helloTo")
helloStr := fmt.Sprintf("%s, %s!", greeting, helloTo)
span.LogFields(
otlog.String("event", "string-format"),
otlog.String("value", helloStr),
)
w.Write([]byte(helloStr))
})
log.Fatal(http.ListenAndServe(":8081", nil))
}
通过 greeting := span.BaggageItem("greeting") 将 baggage 参数取出来。 publisher.go 的代码跟 demo3 的代码一致,这边不再重复贴代码。
一样将 formatter 和 publisher 的服务先启动, 然后执行 hello.go:1
2
3
4
5
6
7[root@VM_156_200_centos client]# go run hello.go zachke cool
2020/12/25 15:31:11 debug logging disabled
2020/12/25 15:31:11 Initializing logging reporter
2020/12/25 15:31:11 debug logging disabled
2020/12/25 15:31:11 Reporting span 270c936b7e4c67d8:7ce7232eb3ac7a9a:270c936b7e4c67d8:1
2020/12/25 15:31:11 Reporting span 270c936b7e4c67d8:0e675665eb1f9f80:270c936b7e4c67d8:1
2020/12/25 15:31:11 Reporting span 270c936b7e4c67d8:270c936b7e4c67d8:0000000000000000:1
注意,这边多了一个参数 cool, 就是我们要携带的 baggage 参数。 formatter 服务将 baggage 参数取出来,并当做参数传递到 publisher 服务,所以我们可以看 publisher 服务的输出,有输出 baggage 参数:1
2
3
4
5
6[root@VM_156_200_centos publisher]# go run publisher.go
2020/12/25 15:29:55 debug logging disabled
2020/12/25 15:29:55 Initializing logging reporter
2020/12/25 15:29:55 debug logging disabled
cool, zachke!
2020/12/25 15:31:11 Reporting span 270c936b7e4c67d8:1da1be329ec5ce18:0e675665eb1f9f80:1
接下来看一下, 后台调用链, 可以看到 , root span 的 logs 中,会有一个 baggage 的 event,上面就会记录所传递的 baggage
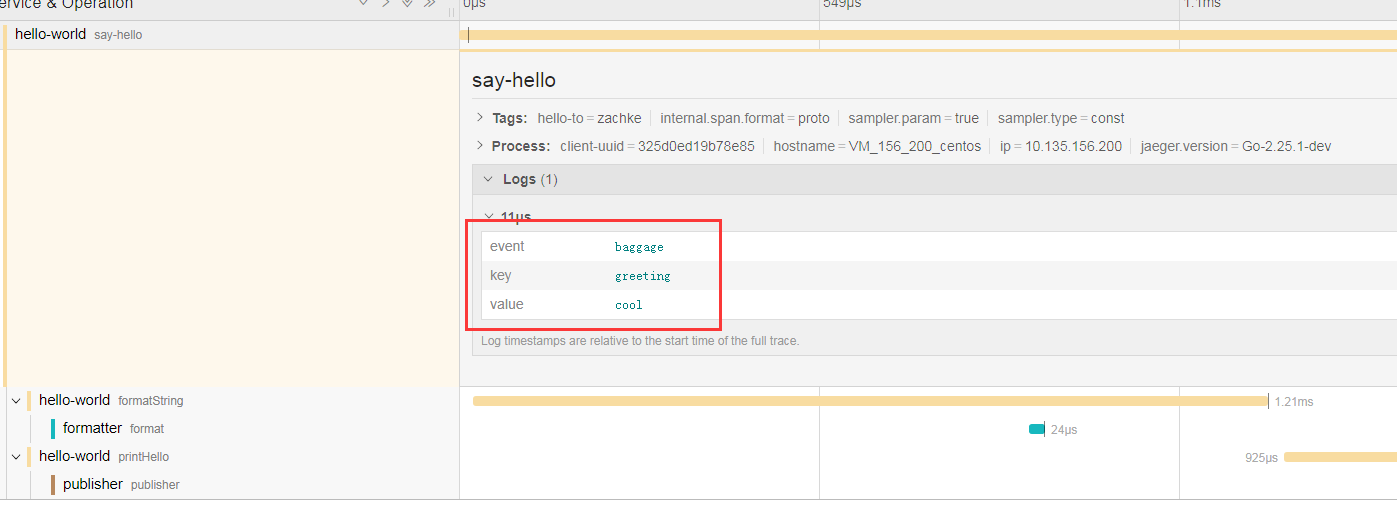
baggage 的注意事项
这边要注意一个细节,那就是 baggage 的携带其实还是跟 traceId 一样,是封装起来,放到 header 中的。 本质上跟 get, post 的参数传递没啥两样。
但是为啥要单独有这个机制是因为,假设你的调用链非常深,有10个微服务,如果用 get,post 参数的方式传递一个 baggage 的话,那意味着 10 个服务代码都得改,不管中间的服务是否需要用到这个参数,反正都得获取并且传递下去,因为万一后面的服务要用到呢? 这个代码入侵性是非常大的。
而通过 baggage 的机制的话,就会做到跟 traceId 的获取一样,直接从 封装好的 header 中使用 extract 导出来,然后再取出来就行了。 如果中间的微服务不需要用到,那么就不需要去取, 只要往下传递的时候,将同样的 内容用 inject 方法注入到下一个微服务就行了,非常的方便。
当然因为 baggage 要一直携带,这个就意味着这个参数不能太大,不然就会影响到数据包的体积, 导致请求会变慢。 具体文档可以看: Now, a Warning… NOW a Warning?
所以我们针对 baggage 的使用一定要特别注意。
综合实践
经过上面的 4 个 demo 的练习,基本上对 jaeger 有个一个比较清晰的印象和使用。 接下来我们就模拟平时我们在使用微服务的时候,是怎么使用 jaeger 进行链路追踪的。
抽象成方法包
首先我们还是跟 demo 的一样,要将 jaeger 的一些配置细节和方法调用,封装成通用的 opentracing 的 api 方式。这样子,就算我们后面不想要用 jaeger ,改换其他的,比如 zipkin 之类的,直接改这个包就行了,对应的业务代码不用改。 具体 tracing.go:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93package tracing
import (
"github.com/opentracing/opentracing-go"
jaegerConfig "github.com/uber/jaeger-client-go/config"
"io"
"fmt"
"errors"
)
var (
Tracer opentracing.Tracer
Closer io.Closer
)
func InitTracer(serviceName, agentHostPort string) error {
if Tracer != nil && Closer != nil {
return nil
}
cfg := jaegerConfig.Configuration{
Sampler: &jaegerConfig.SamplerConfig{
Type: "const",
Param: 1,
},
Reporter: &jaegerConfig.ReporterConfig{
LogSpans: false,
LocalAgentHostPort: agentHostPort,
},
ServiceName: serviceName,
}
_tracer, _closer, err := cfg.NewTracer()
if err != nil {
fmt.Println("Init GlobalJaegerTracer failed, err : %v", err)
return err
}
Tracer = _tracer
Closer = _closer
return nil
}
func getParentSpan(operationName, traceId string, startIfNoParent bool) (span opentracing.Span, err error) {
if Tracer == nil {
err = errors.New("jaeger tracing error : Tracer is nil")
fmt.Println(err)
return
}
parentSpanCtx, err := Tracer.Extract(opentracing.TextMap, opentracing.TextMapCarrier{"UBER-TRACE-ID":traceId})
if err != nil {
if startIfNoParent {
span = Tracer.StartSpan(operationName)
}
} else {
span = Tracer.StartSpan(operationName, opentracing.ChildOf(parentSpanCtx))
}
err = nil
return
}
func StartSpan(operationName, parentSpanTraceId string, startIfNoParent bool) (span opentracing.Span, spanTraceId string, err error) {
plainParentSpan, err := getParentSpan(operationName, parentSpanTraceId, startIfNoParent)
if err != nil || plainParentSpan == nil {
fmt.Println("No span return")
return
}
m := map[string]string{}
carrier := opentracing.TextMapCarrier(m)
err = Tracer.Inject(plainParentSpan.Context(), opentracing.TextMap, carrier)
if err != nil {
fmt.Println("jaeger tracing inject error : ", err)
return
}
spanTraceId = carrier["uber-trace-id"]
span = plainParentSpan
return
}
func FinishSpan(span opentracing.Span) {
if span != nil {
span.Finish()
}
}
func SpanSetTag(span opentracing.Span, tagname string, tagvalue interface{}) {
if span != nil {
span.SetTag(tagname, tagvalue)
}
}
业务代码
我们假意有一个入口 api 是 A, 然后当用户请求 A 接口的是时候, A 会去调用 B 服务的接口, 然后 B 再去调用 C 服务的接口, 同时 A 服务的方法里面模拟出 mysql 查询和 mongo 查询的使用。 具体代码如下:
server A
1 | package main |
启动服务:1
2[root@VM_156_200_centos serviceA]# go run *.go
===service A start===
service B
1 | package main |
启动服务:1
2[root@VM_156_200_centos serviceB]# go run *.go
===service B start===
service C
1 | package main |
启动服务:1
2[root@VM_156_200_centos serviceC]# go run *.go
===service C start===
测试
可以看到每个程序都要初始化服务名,并且要连上本地的 jaeger-agent 服务。
入口就是 service-A 的那个 api, 然后它在请求 service-B 的时候,将 traceId 通过 header 带过去。 然后 service-B 接收到请求的时候, 从 header 将 traceId 取出来。 接下来再异步请求 service-C 的接口, 这次是将 traceId 放到参数后面。
service-C 接收到请求到之后,将traceId 取出来之后,初始化自己的 span 标签。
接下来请求 service-A 的那个接口1
2[root@VM_156_200_centos ~]# curl http://localhost:9991/serviceA/api/test
serviceA done
接下来我们到 jaeger 后台查看这个调用链:
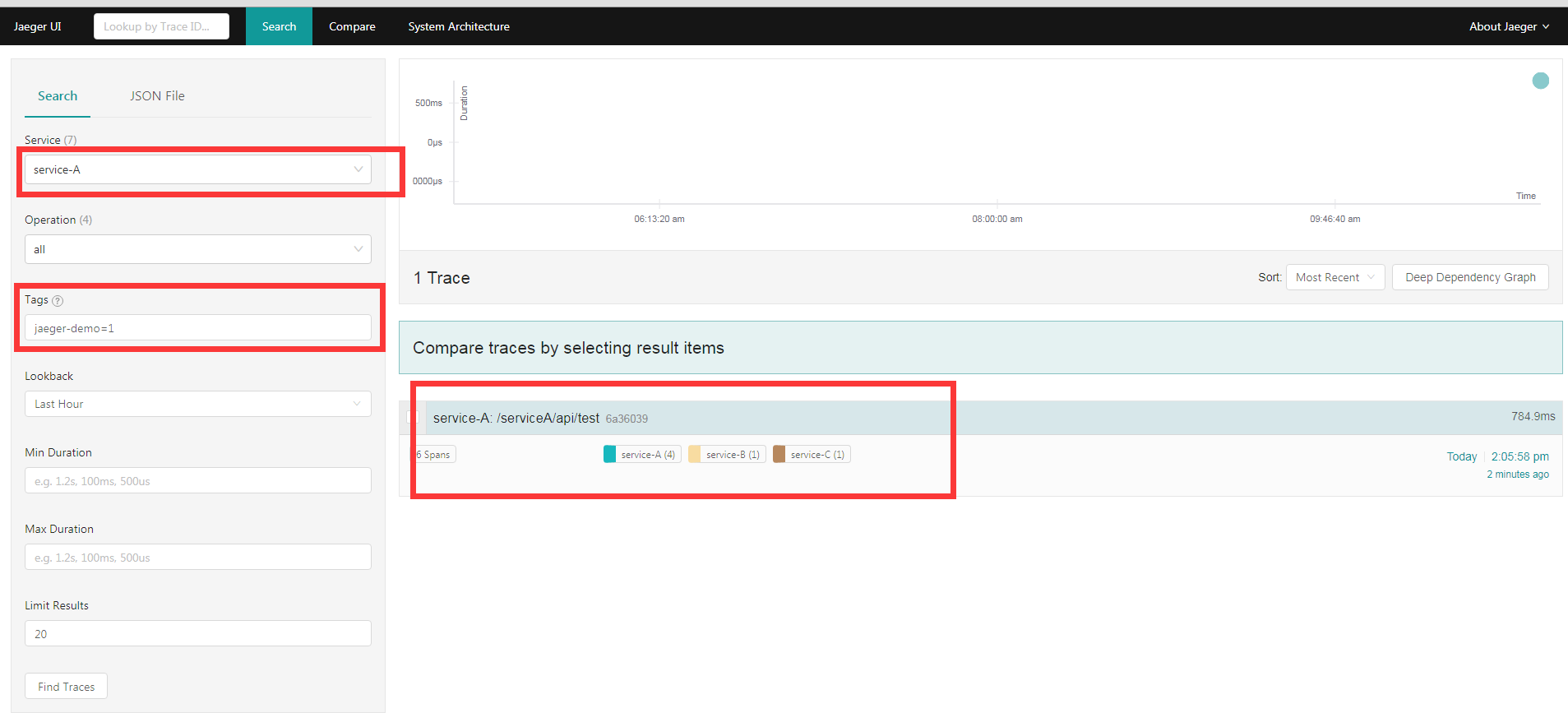
选择服务是 service-A, 然后输入我们在 service-A 设置的 tag 标签。 这时候就可以看到这一条调用链了, 点进去详情
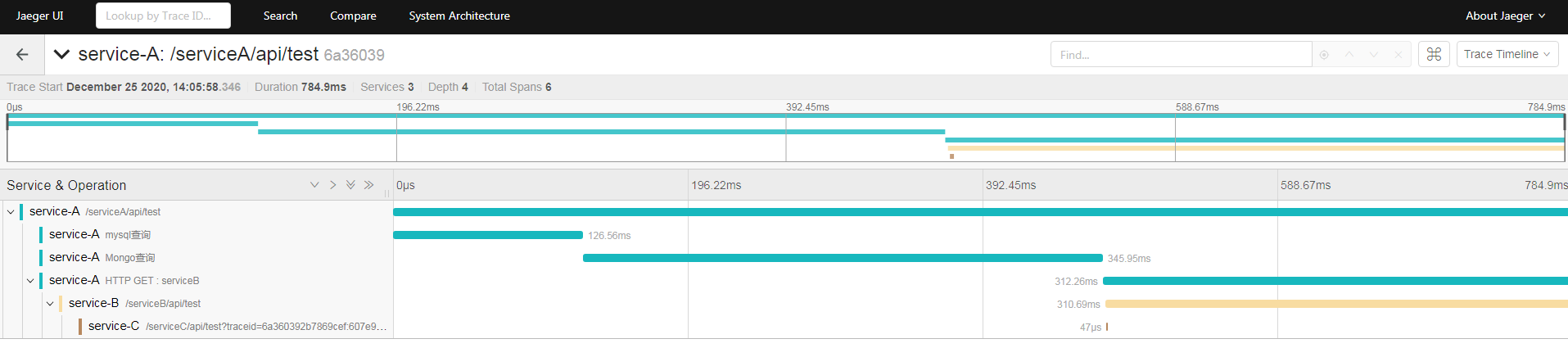
就可以看到在哪些环节都花了哪些时间。
总结
通过 jaeger 的分布式内部链路追踪,我们就可以实现在多个微服务内进行状态和数据监控。 如果有用户在用哪一个服务的时候,有问题了,就可以根据这个用户 id 的 tag 来得到这个用户当次的服务调用详情,我们就可以知道这个用户在哪个微服务环境出问题或者耗时了。 还是非常不错的!!!
参考资料: