前言
前段时间有让 DBA 归档了一些数据库表,有包含统计表,也有包含一些业务表。 当然对于统计表来说,是会有定时归档的计划任务的。 不过这些事情一般都是由 DBA 来做,在请教了一下 DBA 之后,我也整理了一下 mysql 的数据库表的一些归档策略。
通用的归档逻辑
一般是以下面的图为例:
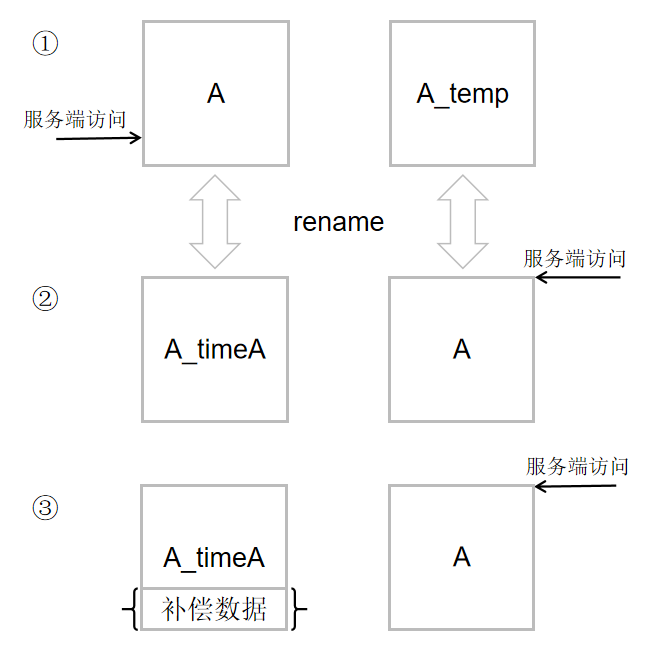
假设归档大表 A, 操作的过程大体分为 3 部分:
- 生成只有原表 A 的表结构的空表 A_temp (ps, 这里有一个 id 自增长的 AUTO_INCREMENT的值的问题, 下文会分类说明), 这时服务端还是访问表 A
- 对原表 A 和 A_temp 进行 rename 操作: A -> A_timeA, A_temp -> A, rename 操作会对相关的表加表级别的锁, 这个操作的时间很快(而且因为会锁表,所以也不用担心在这个过程 A 表会有入数据或者更新数据), 这时服务端访问的是新的表 A (也就是原来的空表 A_temp)
因为归档时间范围问题, 一般我们需要将一些数据补偿回到新的 A 表中, 补偿的方式为分批执行:
1
insert into A ... select ... from A_timeA WHERE ...
归档 A_timeA 表,并且删除掉一些中间表(回补的时候,会涉及到将一些数据先存放到中间表)
日志表归档 (不含 update )
- 日志表的特性: 数据冷热明显, insert操作多和update少甚至没有
- 日志表的归档依照上面的思路, 可以做到不锁表
日志表的特征很明显,几乎全部是 insert 和 select, 不会有 update 操作。 所以不用担心在 rename 的时候, 服务会对原来 A 表的数据行进行 update 操作,导致 rename 后在新表中会找不到对应的数据行。
业务表归档 (含 update )
而业务表不一样,业务表就是会有 update 操作的。 这时候就会造成脏数据 (其实就是漏了 update) 的情况。
举个例子,比如我有一个业务表是发送邮件的表,每次程序会从这个表中捞一笔数据进行邮件发送,然后将发送结果更新到数据行。如果在这个过程中,进行归档,然后新的 A 表(rename 后新的表就是空表)并没有这些正在发送的数据行,这时候 update 操作就会报错(在表中找不到对应的数据行)。这时候就会有脏数据。
那么既然上述的归档操作会导致脏数据,如果是含有 update 操作的业务表要怎么归档呢,其实这边还分为两种情况:
1. update修改的范围具有冷热区分
具有冷热区分的意思就是,这个表会进行 update 操作,但是只对最新的一批数据才会有 update 需求,更旧的数据就不会了。
上述的发送邮件的表,就是具有冷热区分的表,因为发送邮件是相对实时的,每次表里面入了一批数据,程序就会取出来发送,发完之后更新状态,程序不会去取已经发送完的数据行了。 所以这个表 update 的范围永远是最新的那一批数据(比如近一个小时入库的数据), 更旧的数据就不会了。
对于这种情况的表是可以进行归档的,当然我们不能像归档日志表那样去处理。而是要再多加一步,即是在rename操作和首批补偿的sql需要结合在一个事务中, sql的伪代码如下, 这时会对 A 表锁表, 锁的时间长短为首批补偿的数据量决定的 :1
2
3
4
5
6-- 事务开始
Start Transaction;
rename table `A` TO `A_timeA`,`A_temp` to `A`;
insert into `A` select * from `A_timeA` where [update修改的时间范围];
-- 提交事务
Commit Transaction;
还是以上面的 邮件发送表为例, 假设我这边 邮件发送表有 100w 行数据,我打算将 2020-01-01 之前的数据全部归档掉,那么我的步骤应该是:
- 生成只有原表 A 的表结构的空表 A_temp
- 进行 rename 的时候,要跟会有可能会被修改的数据行一起进行操作(比如将最新的一个小时的数据都 insert 到 新表 A 中),这时候事务完成的时候,有 rename 了,同时又有最新的一批数据,这样就不怕会产生脏数据了。 当然这个过程要用事务来保证一致性和原子性
2.1 rename 操作
2.2 将原表中近一个小时的数据,插入到新表中,之后如果有 update 操作的话,范围也是在这一个小时的数据行中,这样就不会有脏数据了 - 最后从旧 A 表中将
2020-01-01到一个小时之前的数据,回补到新表 A 中,然后旧表 A 直接当做归档表存储起来。
2. update修改的范围分布较广
对于这种 update 修改范围很广的表来说,我这边是 不建议归档!!!, 如果真的是数据量太大,因为要加新字段,加新索引,导致会锁表很久,要清理数据的话,也尽量不要用归档的方式,而是采用 delete 物理删除某些已经确定无用的数据,来达到数据行减少的情况, 虽然 delete 操作并不会使得表的体积较少,但是至少因为数据行变少了,这时候如果要加新字段或者是索引的话,也会比之前快。
举个例子: account 表就是属于 update 范围分布很广的表(因为你不确定一个一年前注册的用户,会不会再次活跃,比如修改个密码之类的。),所以这种表是不建议归档的,但是可以通过筛选出一些过期无用的数据(比如有些用户已经三年没有活跃了,其实就可以干掉了),然后 delete 掉。 不过物理删除表数据和归档的差别就在于,归档是新的表,所以表的大小会重新开始算,而 delete 虽然可以使表的条目减少,但是还是原来的表,空间并没有释放,还是那么大。
ps: delete 操作并不会缩小表的空间,因为新的记录会进来覆盖 delete 的数据的位置, 只有 drop table 才能减少空间, mysql 的数据库的空间是按照一定的规模递增的占用空间,只有整个释放(drop)才会空闲。
2.1 如果真的要归档这种类型的表
虽然我极力建议不要对这种表进行归档,而是采用 delete 数据行的方式。如果真的要归档这种表,又要不产生 update 脏数据的话,其实也有方式,就是只能新建一张表出来同步线上的数据, 然后把新的表里不要的数据一点点删(这个过程不影响业务), 删完之后 rename。
但是这种方式只能减少表的数据行,并不会使得表变小,不过因为数据行变少了,加字段锁的时间也少了,加索引的时间也少了。
而之所以还要同步一张新的表出来,然后在同步表里面把不要的数据删掉,最后再 rename, 是因为删的时候,会锁表(有时候如果删的时候走索引,数据量小的时候,会有行级锁,不会有表级锁,但是如果单次删除的数据行多了,还是会触发表级锁),所以 同步表 锁了没关系,不会影响到原表。
因为同步的逻辑是将 binlog 从原表的那边到同步的表上重新做一遍,只要删的内容不是 binlog 有修改的内容,一般是没事的,因为即使 同步表 因为删除锁表了,只要解锁了,同步的 binlog 就会重新接着做。 所以这个同步其实是单向同步 (原表 -> 同步表),我 delete 同步表的数据, 原表其实是不会删除的,这也是为啥最后要 rename 的原因,然后将原表直接归档。
不过这个过程比较复杂,而且需要用到同步工具 otter 来处理。而且如果删除的数据刚好原表被 update 了,那么也会有问题(这时候一般会卡住,可能要人工介入,不过还是不会影响主库),不过既然知道这一条记录会被 update,那么干嘛要删掉呢?
归档时是否要重置 id
归档的时候,这边还需要注意一个细节,就是新表是否要重置 id,还是要在旧表的 id 上继续增长。
这个其实是有差别的,因为 int 的字节为4字节,无符号的int可以存到(0,4 294 967 295),若不是无符号,只有一半。也就是说 id 是有最大值的,所以如果新表有重置 id 的话,这样可以有效的避免 id 的一直增长达到最大值
1. 新表重置 id
步骤如下:
- 在第 1 步之前, 需要确认不需要归档的数据
N, sql的伪代码如下
1 | -- 在第 1 步前, 确定不需要归档的数据量 N |
- 修改第 1 步的空表 A_temp 的 AUTO_INCREMENT 为一个大于不需要归档的数据量
N的值, 防止在操作过程中原表 A 的数据有新增, sql的伪代码如下
1 | CREATE TABLE `A_temp` ( |
- 在第 3 步补偿数据前,生成自增为 1 的 A_record_id 表(可以删除其他索引,保留主键), 对从 原表A (A_timeA) 获取到 不需要归档数据 进行重新生成 id, 保证按照时间条件从 1 开始, 并插入到 A_record_id 表,之后第 3 步的分批补偿数据的表就从 A_record_id 表去获取数据补偿到 A 中, sql的伪代码如下:
1 | CREATE TABLE `A_record_id` ( |
- 归档原表 A (A_timeA), 删掉中间表 A_record_id
这样子新表的 id 就会重置了,而归档日期之后的回补数据,也会从 id 1 开始计算。 而中间表的作用就是让回补的数据有重置后的 id 字段。
2. 新表不重置 id
如果 id 不可以重置, 既归档后的表 A 的数据继续在原表的 id 顺序:
在第1步之前, 需要确认当前的最后一行的 id 值
N, sql的伪代码如下1
2-- 在第 1 步前, 确定最后一行的 id 值
select `id` as N from `A` order by `id` desc limit 1;修改第 1 步的空表 A_temp 的 AUTO_INCREMENT 为一个大于最后一行的 id 的值
N的值, 防止在操作过程中原表 A 的数据有新增, sql的伪代码如下
1 | CREATE TABLE `A_temp` ( |
- 在第 3 步分批补偿数据的表就从 原表 A(A_timeA) 表去获取数据补偿到 A 中, sql的伪代码如下
1 | -- 对从 A_timeA 获取到补偿数据 分批 补偿到 A 中 |
归档的过程中修改表结构
如果在归档的过程中是否需要修改表结构(修改字段,添加字段,删除字段,添加索引,删除索引等),也可以一起处理:
在第 1 步生成的空表 A_temp 上,根据修改表结构的语句, 修改空表表结构
1
2
3
4
5
6
7
8
9-- 修改表结构的语句为
-- alter table A add column ses_type tinyint(4) not null default 0 comment '使用哪个ses服务账号发送,0 personal 1 biz';
CREATE TABLE `big_queue_temp` (
`id` int(11) NOT NULL AUTO_INCREMENT,
... ,
`ses_type` tinyint(4) not null default 0 comment '使用哪个ses服务账号发送,0 personal 1 biz',
PRIMARY KEY (`id`),
...
) ENGINE=InnoDB AUTO_INCREMENT=N+1000 DEFAULT CHARSET=utf8;
在第 3 步分批补偿数据到 A 表的时候, 也需要根据修改表结构的语句, 修改 insert into A 和 select 后面的字段列表, sql的伪代码如下
1
2
3
4-- 修改表结构的语句为
-- alter table A add column ses_type tinyint(4) not null default 0 comment '使用哪个ses服务账号发送,0 personal 1 biz';
insert into big_queue (`id`, ... ,`ses_type`)
select `id`, ... ,0 from `A_timeA` where [不需要归档数据的数据量];
这样子新表 A 就有新的表结构了。而且回补的数据也有新的字段了。
总结
基本上 mysql 的数据库表的归档就分为这两种。 最后感谢 DBA 海玲 和 辉辉 的一些解疑。