问题
之前在做一个连表查询的时候,就是查询某账号的折扣劵的时候,发现了一个问题:1
2
3
4select flp.coupon_code, coupon.*
from fee_logs
left join fee_logs_patch as flp on flp.in_order_id = fee_logs.in_order_id
left join coupon on coupon.code = flp.coupon_code
发现左联的另一半竟然查不到记录:
但是我单独用这个折扣码去查是有东西的:1
select * from coupon where code = 'gcma1fwwdawn3jaD';
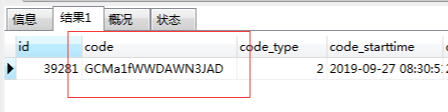
这时候是有数据的,而且可以看到这个字段是不区分大小写的。
这时候用另一个表去查折扣码:1
select * from fee_logs_patch where coupon_code = 'gcma1fwwdawn3jad';
发现也是有数据的,
这不过这时候是完全匹配。 所以我觉得有可能是 fee_logs_patch 这个表的 coupon_code 可能大小写敏感,所以我又换了一个:1
select * from fee_logs_patch where coupon_code = 'gcma1fwwdawn3jaD';
果然发现查询不到数据了。 只支持完全匹配??? 而 coupon 表的 code 字段,无论是大写,还是小写,都是可以被查出来的。
原因
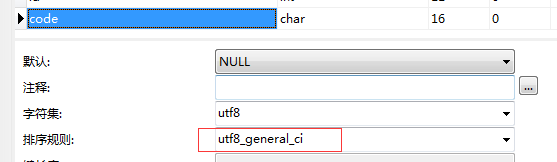
后面查了一下这两个字段的差别,终于发现有一个不同:coupon 表的排序规则是 utf8_general_ci, code 字段的排序规则也是 utf8_general_ci: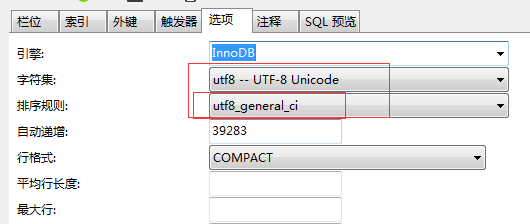
而 fee_logs_patch 表的排序规则是 utf8_bin, coupon_code 字段的排序规则也是 utf8_bin: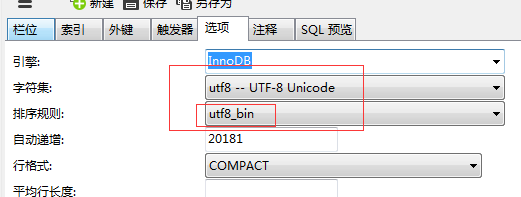
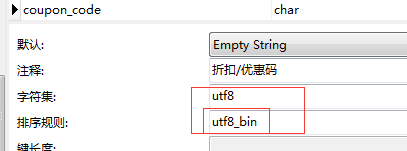
一个是 utf8_bin ,一个是 utf8_general_ci, 有啥差别呢?
编码的排序规则
可以看到这两个表和对应的列的字符集都是 utf8 (事实上 utf8 也是不对的,应该是 utf8mb4, 具体看 如何在mysql数据库中保存 emoji 特殊字符?), 但是排序规则是有差别的,差别在哪里呢?
mysql 有很多种排序规则,如果字符集选的是 utf8 的话,那么经常用的就这几个:
(ps: 如果选的是 utf8mb4, 那么下面的排序规则也是对应的,比如 utf8mb4_bin)
utf8_bin: 将字符串中的每一个字符用二进制数据存储,区分大小写, (在二进制中 ,小写字母和大写字母不相等.即 a !=A)utf8_general_ci: 不区分大小写,ci 为case insensitive的缩写,即大小写不敏感,为utf8默认编码utf8_general_cs: 区分大小写,cs为case sensitive的缩写,即大小写敏感utf8_unicode_ci: 跟utf8_genera_ci差不多,对中、英文来说没有实质的差别,如果你的应用有德语、法语或者俄语,请一定使用utf8_unicode_ci
这边总结一下:
utf8_bin是区分大小写的,因为是二进制存储的,a和A对应的二进制就是不一样,因此它不仅可以存字符,它还可以存二进制的内容- 后缀带
ci就是大小写不敏感, 带cs就是大小写敏感,所以像存邮箱和用户名之类的,一般都是不区分大小写的,都要用这种来存 - 带
general和带unicode其实差不多(除非有小语种),不过从速度上来说,utf8_general_ci校对速度快,但准确度稍差。utf8_unicode_ci准确度高,但校对速度稍慢。
举个例子喽
建三个表(第二个和第三个其实一样的):1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17CREATE TABLE `t_bin` (
`id` int(11) DEFAULT NULL,
`name` varchar(20) DEFAULT NULL,
UNIQUE KEY `uk_name` (`name`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin;
CREATE TABLE `t_ci` (
`id` int(11) DEFAULT NULL,
`name` varchar(20) DEFAULT NULL,
UNIQUE KEY `uk_name` (`name`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_general_ci;
CREATE TABLE `t_default` (
`id` int(11) DEFAULT NULL,
`name` varchar(20) DEFAULT NULL,
UNIQUE KEY `uk_name` (`name`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
然后试着插入数据:1
2
3
4
5
6
7
8
9
10
11
12
13
14//可以插入
insert into t_bin values (1, 'Zach');
//可以插入
insert into t_bin values (2, 'zach');
//可以插入
insert into t_ci values (1, 'Zach');
//[Err] 1062 - Duplicate entry 'zach' for key 'uk_name'
insert into t_ci values (2, 'zach');
//可以插入
insert into t_default values (1, 'Zach');
//[Err] 1062 - Duplicate entry 'zach' for key 'uk_name'
insert into t_default values (2, 'zach');
最终t_bin表中会有两条记录,而t_ci和t_default表中,只有第一条记录。
解决
所以上述问题出现的原因,其实就是排序规则不一样, code 字段是 utf8_general_ci 所以不区分大小写,而coupon_code 字段的排序规则是 utf8_bin, 是区分大小写的。所以就会导致连表的时候,如果存储的字串不完全一样,就会匹配不上。
方法一: 将表和字段的COLLATE属性修改为utf8_general_ci
1 | -- 将整个表中列的char,varchar,text等都修改字符集; |
这样就可以了。(事实上,库也需要改,不过我看了一下,库的字符集和排序规则已经是 utf8 和 utf8_general_ci, 所以就不需要额外调整了)。
不过这样就相当于数据重新写入了,可能会导致锁表,会造成堵塞,所以数据大的表,要谨慎操作!!
从sql上调整
加上 convert 转换成 utf8 就行了1
select * from fee_logs_patch where CONVERT(coupon_code using utf8) = 'gcma1fwwdawn3jaD';
这样子就可以查询出来了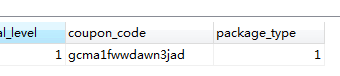
连表也是一样的操作:1
2
3
4
5select flp.coupon_code, coupon.*
from fee_logs
left join fee_logs_patch as flp on flp.in_order_id = fee_logs.in_order_id
left join coupon on coupon.code = CONVERT(flp.coupon_code using utf8)
where fee_logs.account_id = '181544914' and fee_logs.fee_mode_id > 200000;
这样也是可以查到的
改完之后的新问题
事实上,我们是通过第一种的方式来调整的,就是将 表和列 的排序方式改成 utf8_general_ci, 但是后面发现 DBA 有报警了,发现了一个慢查询:1
2
3
4
5
6SELECT A.id
FROM fee_logs_patch AS A
INNER JOIN fee_logs AS C ON C.in_order_id = A.in_order_id and C.status = 1
WHERE A.account_id = '24193341'
AND A.is_use = 0
ORDER BY A.start_time;
就会变成这个 sql 有问题了, 原因就是 fee_logs_patch 表中的 in_order_id 是 utf8_general_ci 存的。 而 fee_logs 表中的 in_order_id 是 utf8_bin 存储的,而表的字符集也是不一样的,fee_logs 表的字符集也是utf8_bin。 因为存储的方式不一样,所以可能会导致连表的时候,查询的复杂度会上升,而且非常的耗 cpu 和 耗时间,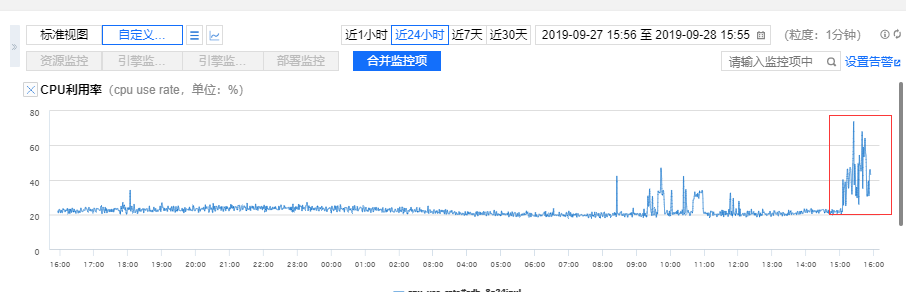
考虑到可能对线上业务造成影响,所以就先回滚成原先的排序方式了。 果然改回之后,就不会有慢查询了。 所以就只能先用 sql convert 的方式来兼容了。
备注
其实最优方式,就是将 库,表,列的字符集全部设置为 utf8mb4, 而排序方式都设置为 utf8mb4_general_ci。 除非你有存放二进制的需求。
(之前建表的时候,用默认的 utf8 来创建,也是太年轻了,到现在业务复杂度太大了,反而很难去调整了。)