前言
去年有通过 aws 的 Lambda 服务来解决缩略图的问题: 项目使用 aws 的 lambda服务来生成s3的缩略图,不过那时候是国内七牛缩略图,国外 S3 缩略图各自的策略,他们的缩略图的 URL 是不一样的。因为我们会在用户上传图片的时候,判断这个用户的所在国家,如果是中国的话,就传到七牛那边去,否则就传到 S3。
但是这边会有一个问题,就是如果我在国内传了一个图片,这时候是会传到七牛那边去的,但是一旦我到国外去,访问这个图片的话,也是会访问七牛的图片(因为S3根本就没有上传,我们只上传到七牛,所以保存的也是七牛的路径),这时候线路就不会得到优化了。
新的策略-图片CDN
现在我们有另一个全球的项目,在这个项目里面,要求用户上传的所有的图片资源无论是七牛还是S3都要传一份,这个是因为考虑到用户的使用场景有可能会有跨国的问题,所以就是相当于我们对用户上传的资源做了一层 CDN ,如果用户在国内访问的话,就会去取七牛的图片,如果在国外访问的话,就会去取 cloudfront 的图片。
图片CDN域名要一致
如果要实现这种结果的话,那么无论是七牛还是S3,对外的域名肯定是同一个,比如 img.example.com, 只要用户访问 img.example.com/123.jpg ,那么这时候 DNS 解析如果是在中国的话,就会 CNAME 到七牛对应 bucket 的域名,然后获取对应路径的图片, 如果解析是国外的,那么就会 CNAME 到 cloudfront 对应的 S3 的 bucket, 然后去取对应路径的图片。
所以我们用了 AWS 的 router 53 的服务,就可以实现这种针对不同地区的不同指向了。
Amazon Route 53 是一种可用性高、可扩展性强的云域名系统 (DNS) Web 服务。
它的目的是为开发人员和企业提供一种非常可靠且经济高效的方式,把名称(如 www.example.com)转换为计算机用于互相连接的数字 IP 地址(如 192.0.2.1),从而将最终用户路由到 Internet 应用程序。Amazon Route 53 也与 IPv6 完全兼容。
截图如下:

可以看到,针对这个域名来说,如果地理位置是 CN 的话,那么会解析到七牛那边的 DNS 地址,否则就会解析到 S3 bucket 对应的 cloudfront。 接下来我们就以 img.example.com 这个域名来说。
对于七牛来说,其实就是建一个存放图片资源的 bucket,比如 img-example-com, 然后建立一个 CDN 加速域名,域名为 img.example.com,这样子 router 53 那边做 CNAME 解析的时候,就可以匹配上了,就可以到这个 bucket 来取数据了。
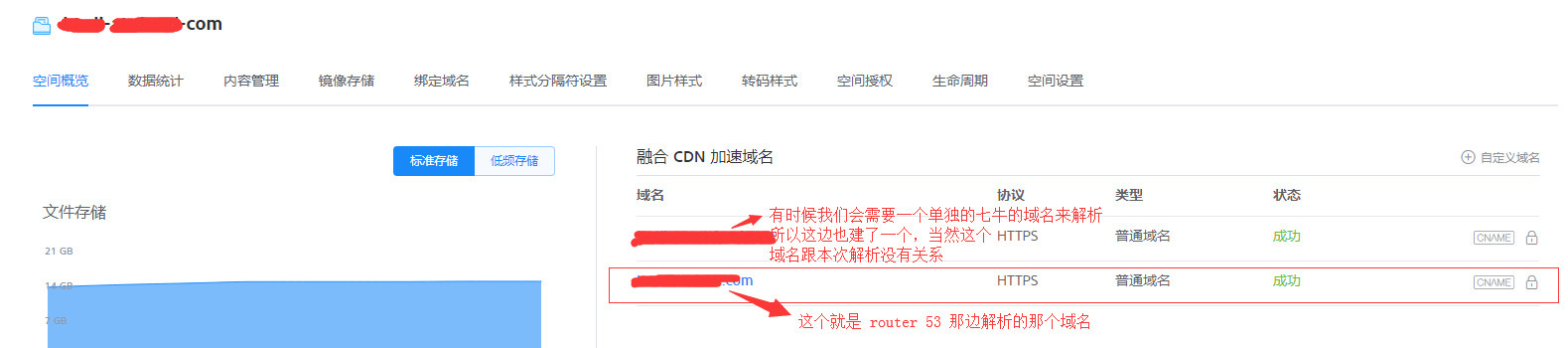
对于 S3 来说,也是一样的处理方式,也是在 S3 上建一个存放图片资源的 bucket,比如 img-example-com,然后创建一个针对这个 S3 的 cloudfront 的 CDN, 然后把 CDN 的解析域名也指向 img.example.com, 这样子, router 53 也才可以匹配得上。
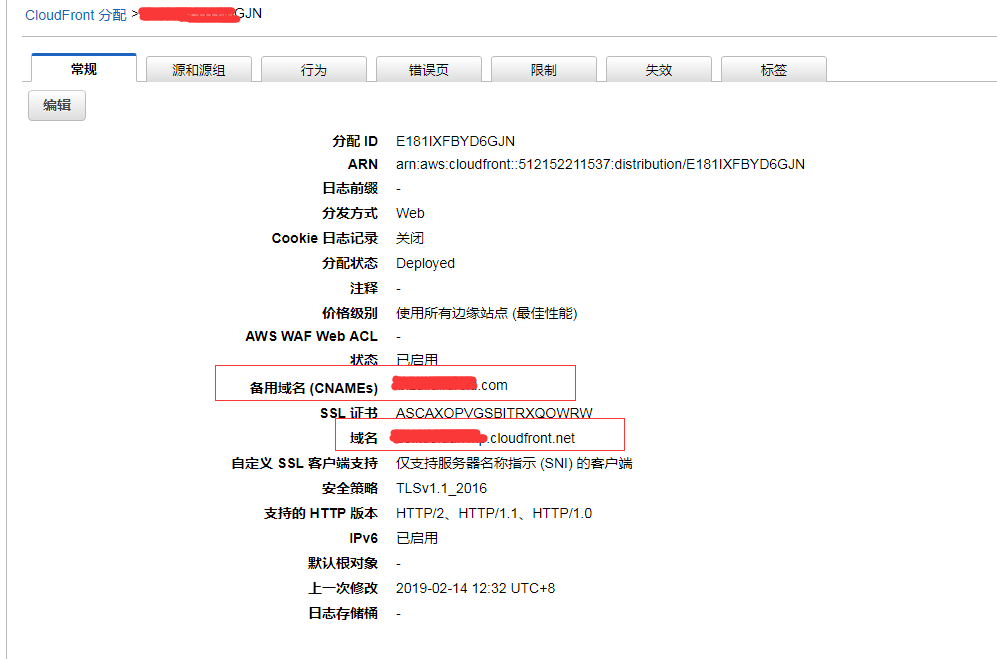
这样子就可以了,接下来要实测一下。 我们分别往 S3 和 七牛的 bucket 上传一张相同的图片。 比如 img.example.com/123.jpg , 然后查看是否可以访问成功。
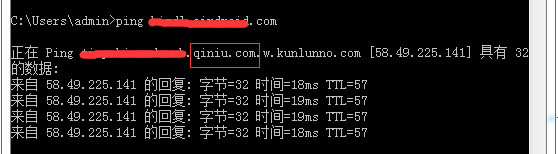
因为是国内,所以默认是七牛的 CDN:

可以看到访问成功了,这个 ip 就是七牛的某一个 CDN 的 ip:
接下来测试 cloudfront 的情况,首先先得到这个 cloudfront 的 ip 地址,然后将 img.example.com 的 host 指向这个 ip:
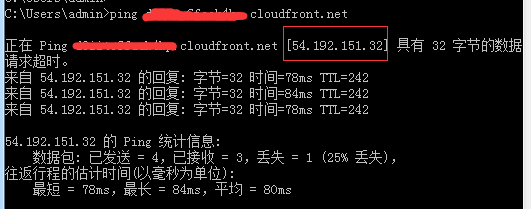
1 | 54.192.151.32 img.example.com |
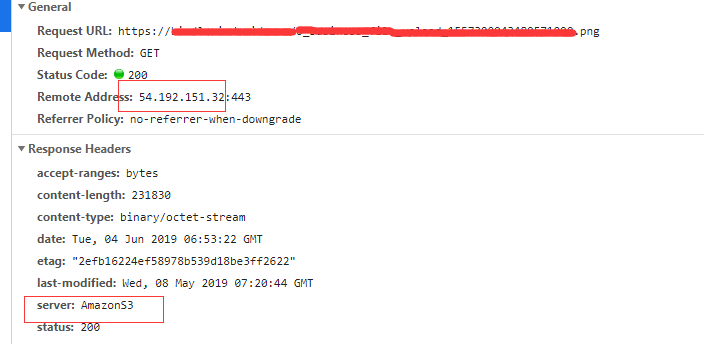
测试正常。
缩略图域名问题
我们已经将原图的 URL 做了一层针对不同地区的 CDN 了。但是缩略图呢?? 我们知道无论是七牛还是S3,其实都有缩略图方案,七牛本身bucket就支持缩略图策略,S3 通过 Lambda 函数也可以实现缩略图: 项目使用 aws 的 lambda服务来生成s3的缩略图。
但是问题就出现在,无论是七牛的缩略图还是 S3 的缩略图,对外的路径肯定是要一样的,这个要跟原图一样,也是要有一层 CDN 的,七牛的还好,因为他的缩略图机制就是在原来的bucket上做的,但是我们之前做的 S3 通过 Lambda 函数生成缩略图是存放在另一个 bucket的。 这样就七牛和S3的缩略图的访问路径就不一样了,这样就违反了我们做 CDN 的初衷了。
假设我们要针对某一个功能上传的图片要做两层缩略图,一层是 10% 的缩放比,一层是 50% 的缩放比。 而且所有通过这个功能上传的图片的前缀都是一样的,比如都是 ams_store_image 这个前缀。
七牛的缩略图
七牛的缩略图在 项目使用 aws 的 lambda服务来生成s3的缩略图 其实已经讲过了,就是在这个 bucket 上创建你想要的缩略图的样式。针对这两种缩略图,我们就建了两个。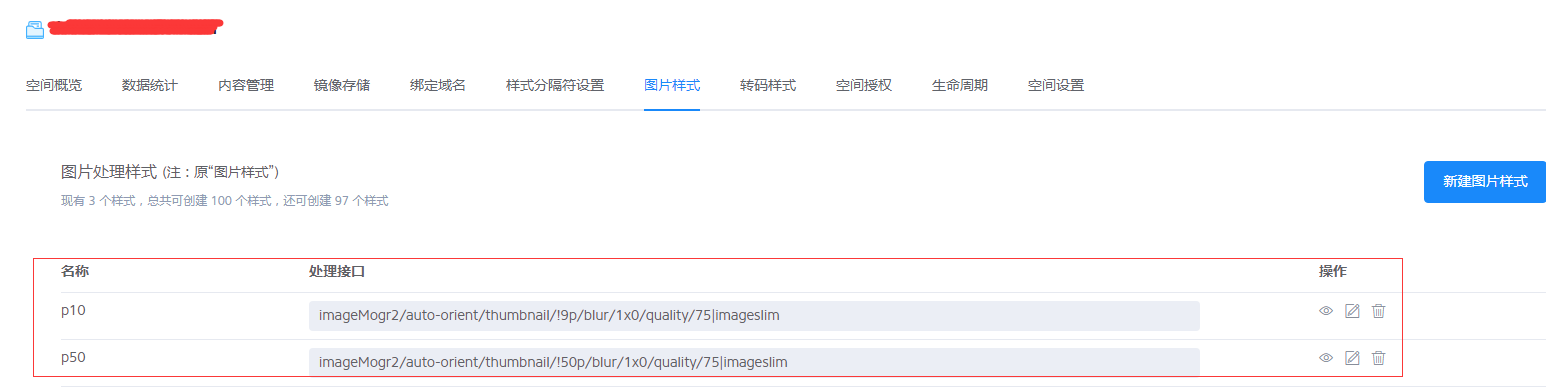
这边有预览图,我们用的是 原图按百分比缩放 的方式, 然后设置你要的缩放比例(一个是 10%, 一个是 50%),选择的是不裁剪,不加水印,并且输出的格式跟原图一致。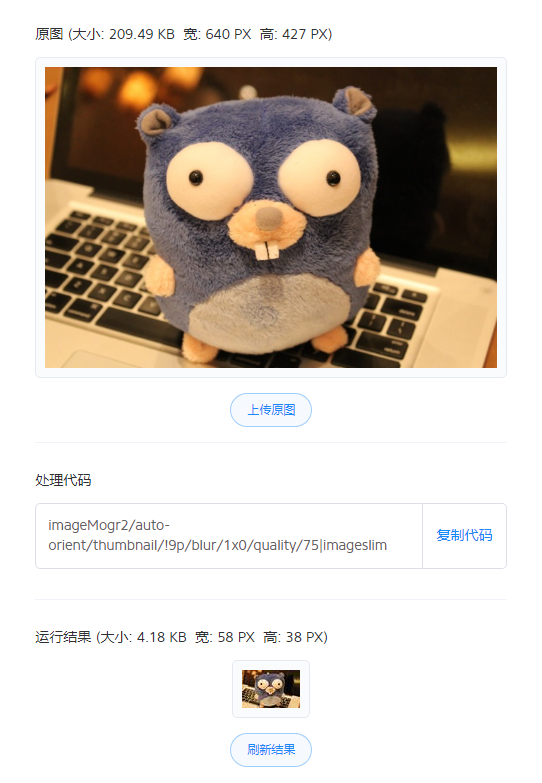
然后选择默认的样式连接符是中划线。 这样就可以了,假设原图是 img.airdroid.com/123.jpg, 那么他的
- 10% 的缩放图就是:img.airdroid.com/123.jpg-p10
- 50% 的缩略图就是:img.airdroid.com/123.jpg-p50
这样子七牛创建的两种缩略图就搞定了。
S3 的缩略图
因为七牛的缩略图的 URL 是不能改变的,按照一定的既定规则,为了保证对外的缩略图 URL 要一致, 那么我们只能让 S3 生成的缩略图的 URL 要跟七牛的一样。
但是一般用 Lambda 生成缩略图,一般缩略图要放在另一个bucket,一般是 {bucket}resized 这种格式,所以我们后面生成缩略图就不能这样子了,而是要放到跟原来的bucket一样。
所以具体的逻辑应该是:
- 上传文件 123.jpg 到 img-example-com bucket 触发 Lambda 事件,接下来判断这个图片的前缀和后缀是否符合我们要生成缩略图的图片,如果不存在,就跳过(事实上这一块不会在代码里面做,而是S3 触发器会帮我们做)。
- 如果符合,接下来判断 123.jpg-p10 (123.jpg-p50) 这个缩略图是否存在这个bucket,如果已经存在,说明缩略图已经有了,就跳过。
- 如果不存在,就将 123.jpg 原图下载到内存 buffer 里面,然后按照百分比进行裁剪(10% 和 50%),重新命名为 123.jpg-p10 (123.jpg-p50), 然后将缩略图传到源bucket里面。
这样就完了,但是要注意几个细节:
- 当我把缩略图上传到bucket的时候,一样会触发 Lambda 函数,不过因为后缀已经不符合我们的裁剪条件了,所以直接在第一步就跳过了。所以后缀的判断就很重要(S3 触发器设置)
- 前缀的判断也很重要,为了节省资源,我们只针对某些特定功能上传的图片进行裁剪,不需要对所有的上传的图片进行裁剪,所以这边要有前缀的判断,而这个前缀就需要上传的程序来指定,比如如果是通过某一个功能上传的图片,服务端全部都会在这个图片的 filename 那边加上 xxx-xxx 的前缀
- 虽然 Lambda 执行环境他有自己的临时硬盘空间,但是一旦使用了,用来存放下载的图片,裁剪完之后,一定要记得删掉。所以这次我们下载原图的时候,直接存放在内存里面就行了。后面就不用再去删掉了。
认识 Lambda
因为在去年自我上次使用 Lambda 生成缩略图之后, Lambda 这个功能也改了很多。所以我这边再重新介绍一下。具体关于 Lambda 的使用文档,可以看这边:AWS Lambda
我这边就按照正式流程,稍微过一下(因为我是在实现了之后,再写 blog 复盘的,所以之前建的那些流程和图都没有截下来,我就简单模拟了一下流程):
创建一个函数
进入 Lambda 后台,点击创建函数,填写函数名称,并选择运行的语言环境,这边有很多环境可以选,有 Python,nodejs, Go, Java 等等,主要看你熟悉什么语言。 我这边选择的是 Python 3.6 的运行环境。因为上次我创建的那一个 Lambda 函数的运行环境也是 Python 3.6。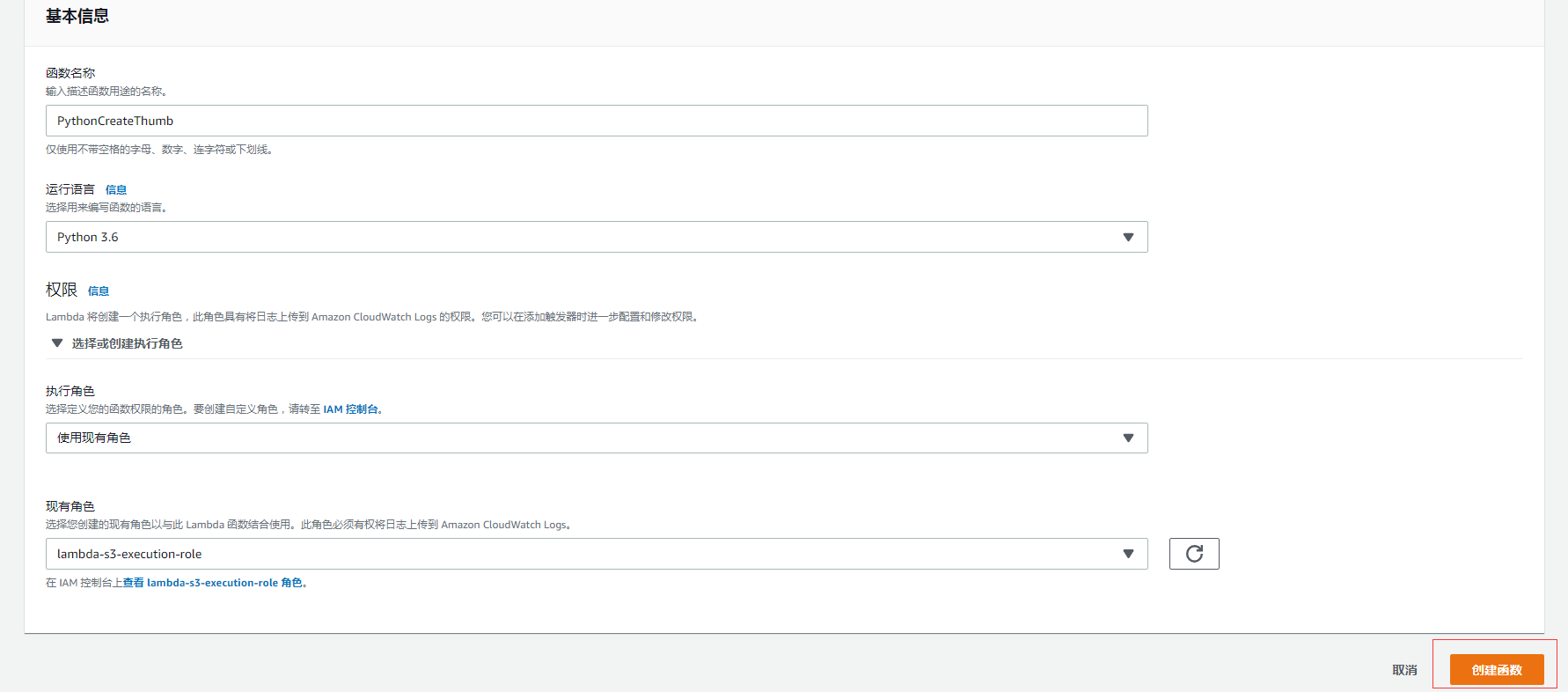
创建好了之后,界面的这样子的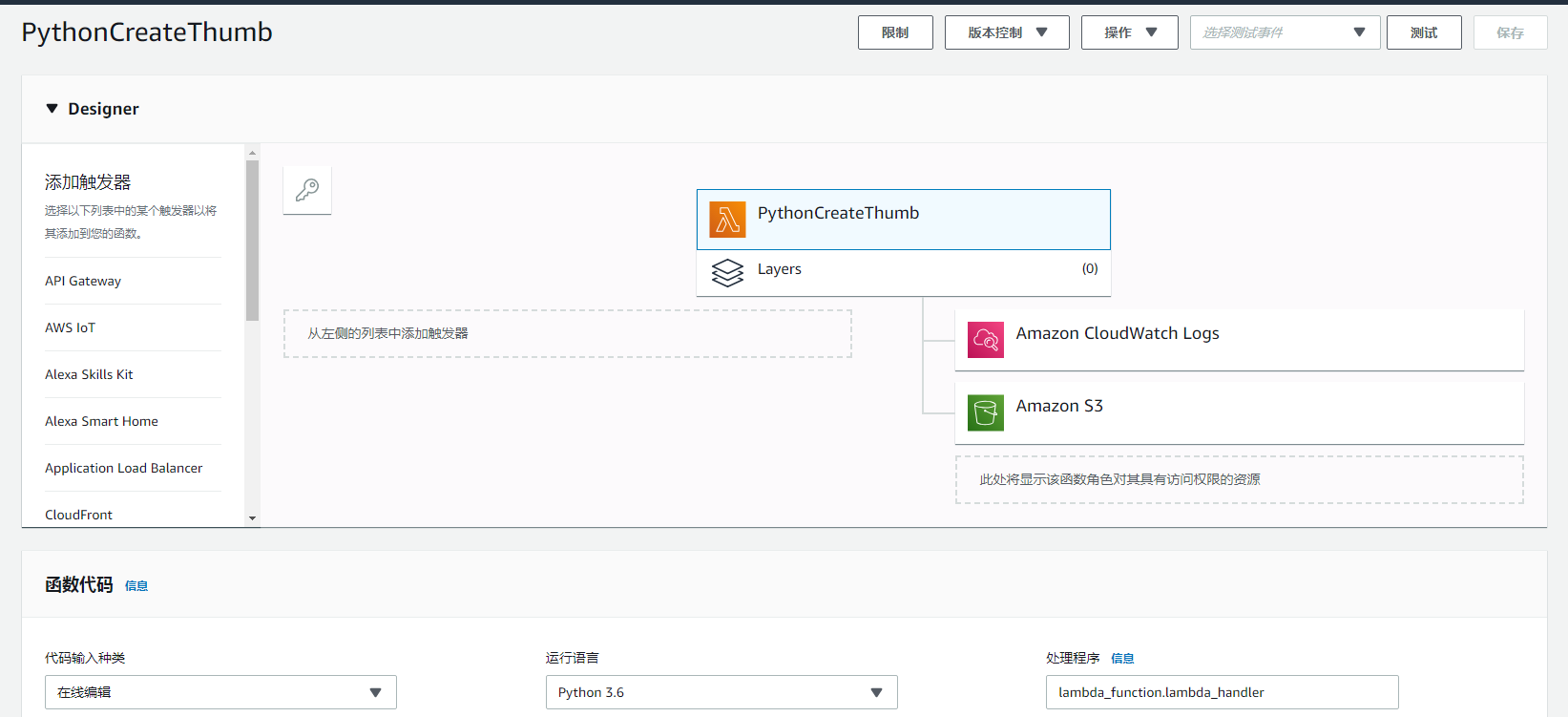
跟我去年建的不太一样的是,多了一个叫做 Layers 的东西,并且下面竟然可以直接在线编辑 Python 代码。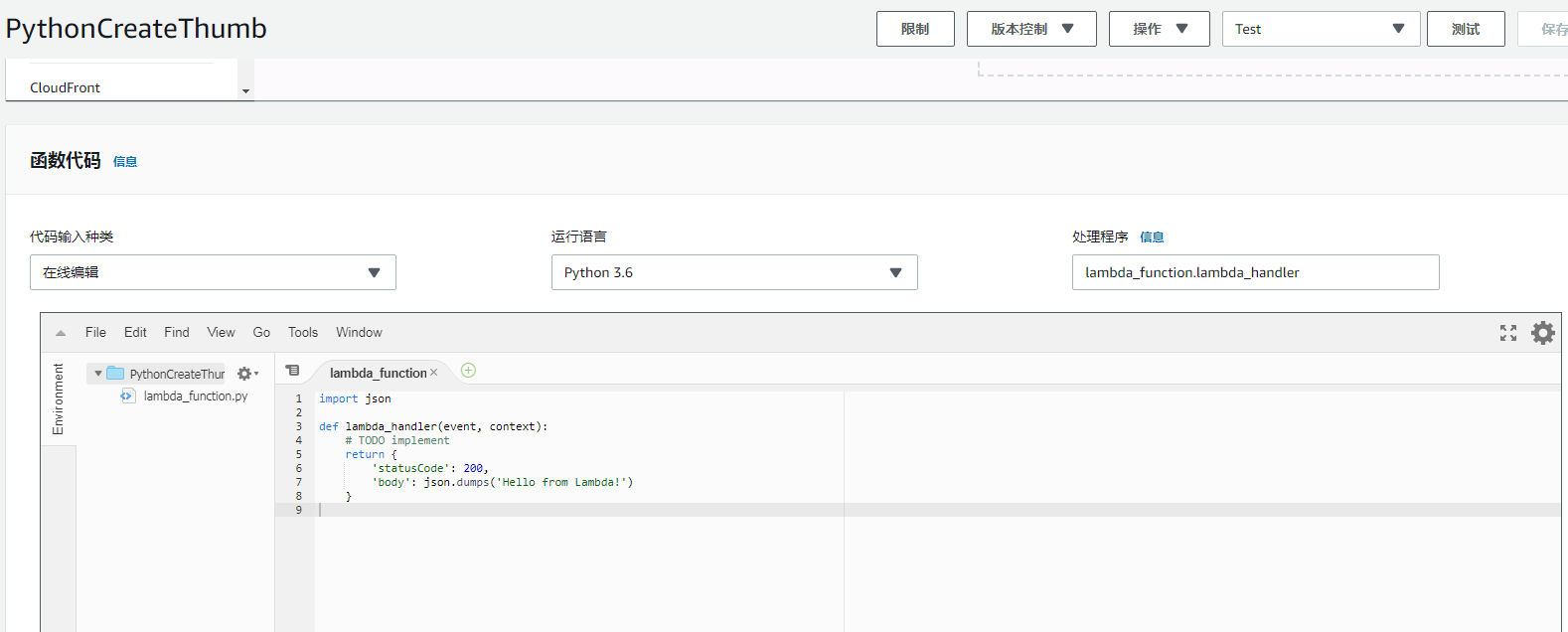
创建一个 layer 层
这次跟我去年创建的最大的差别就是多了一个叫做 layer 的层机制。那么这个 layer 是干啥用的。
您可以将 Lambda 函数配置为以层的形式拉入其他代码和内容。层是包含库、自定义运行时或其他依赖项的 ZIP 存档。利用层,您可以在函数中使用库,而不必将库包含在部署程序包中。
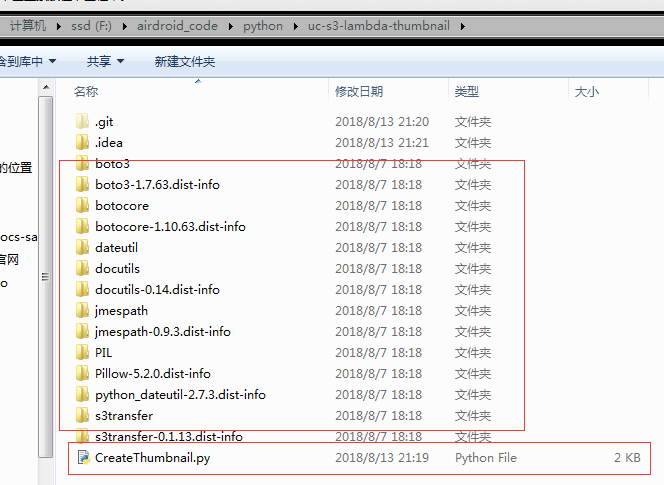
说白了就是存放第三方库的地方,去年我在上传 Python 代码的时候, 真正可编辑的代码文件只有一个: CreateThumbnail.py, 其他的全部都是依赖的第三方库:
那么这次我如果还想实现类似的功能,第三方库我就不需要再传了,而是直接创建一个包含这些第三方库的 Python layer 层就行了。
点击左边菜单栏的 层,然后点击右上角的创建层:
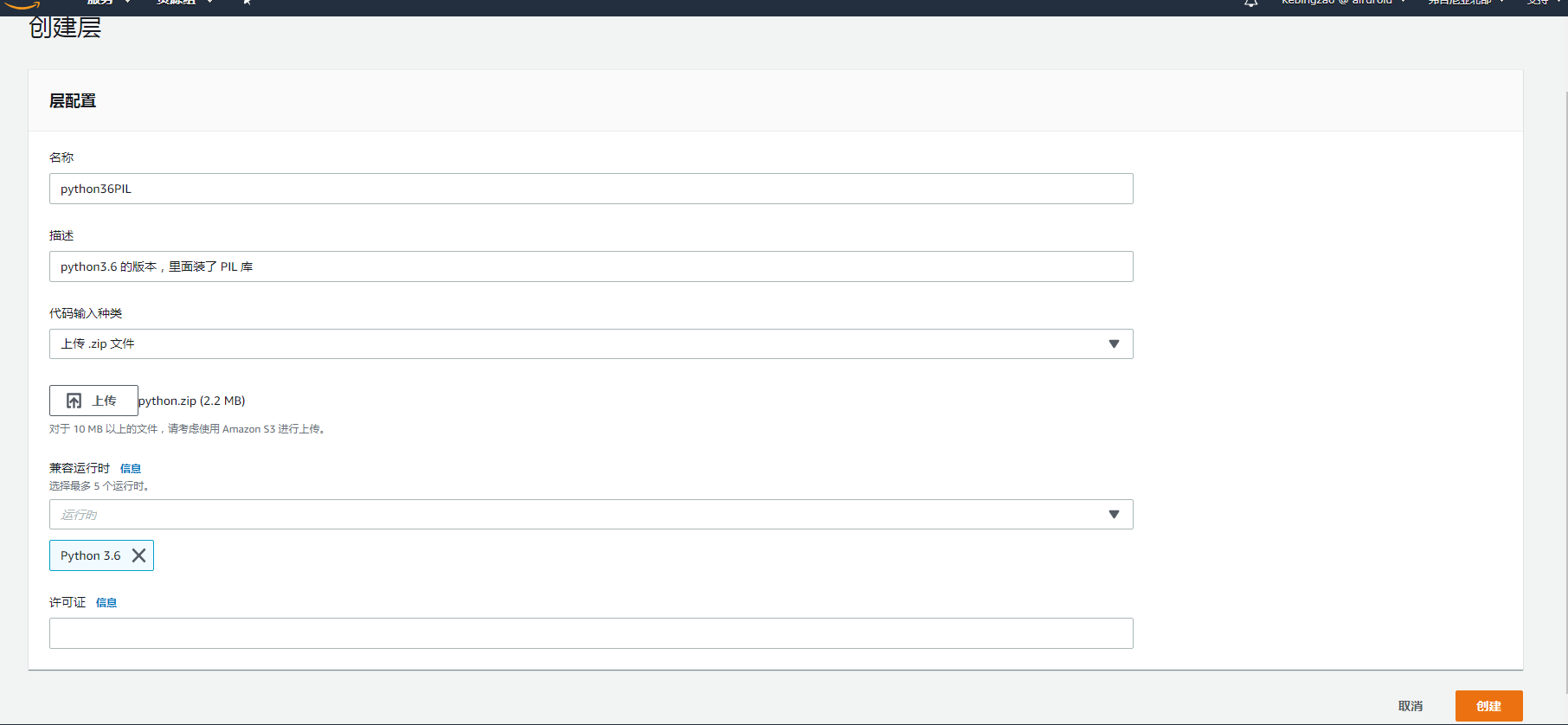
填入相关信息,选择运行的环境为 Python 3.6,并且上传第三方 zip 包,他是有格式要求的,因为我们 Python 环境,所以最外层是 python 文件夹,里面才是各个第三方包:
1 | python.zip |
具体可以看这个说明:在层中包括库依赖项
点击创建,这时候就多了 Python的 层。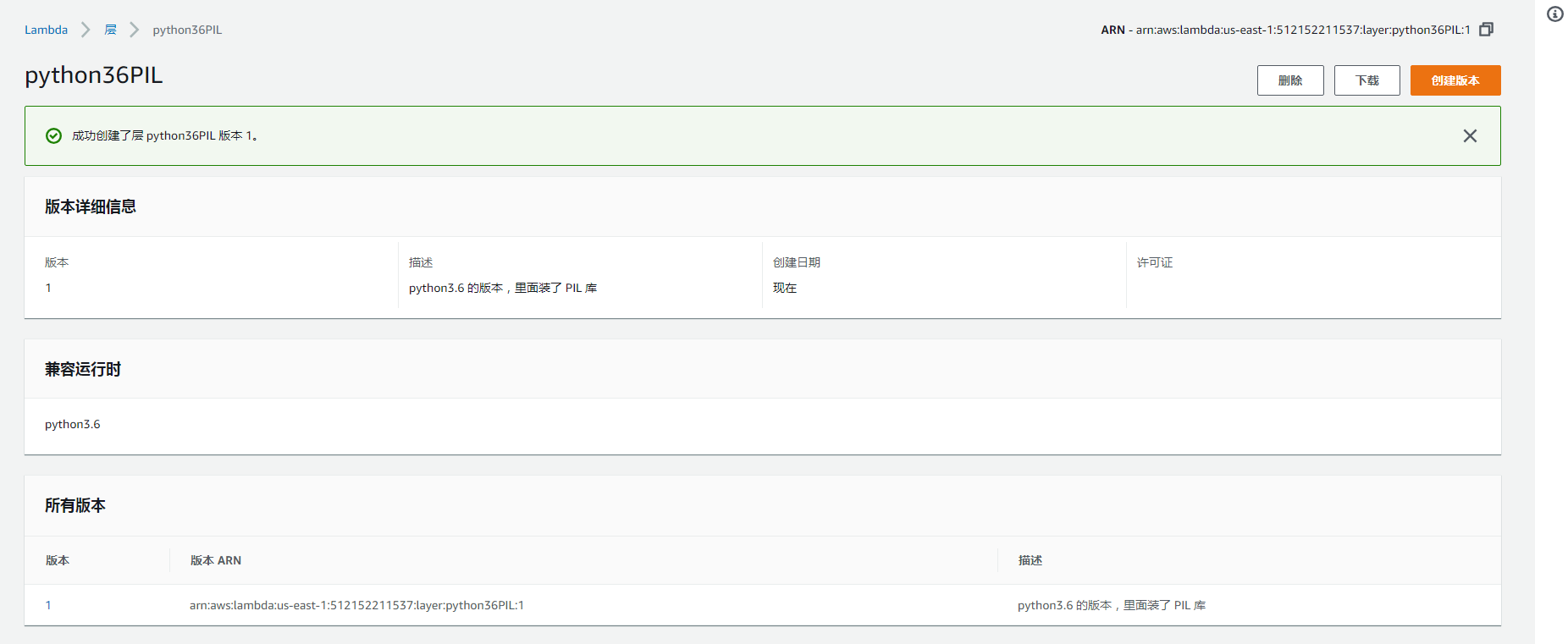

可以看到多了一个叫做 python36PIL 的层。
将层添加到函数
既然层创建好了,那么就添加到这个函数里面去: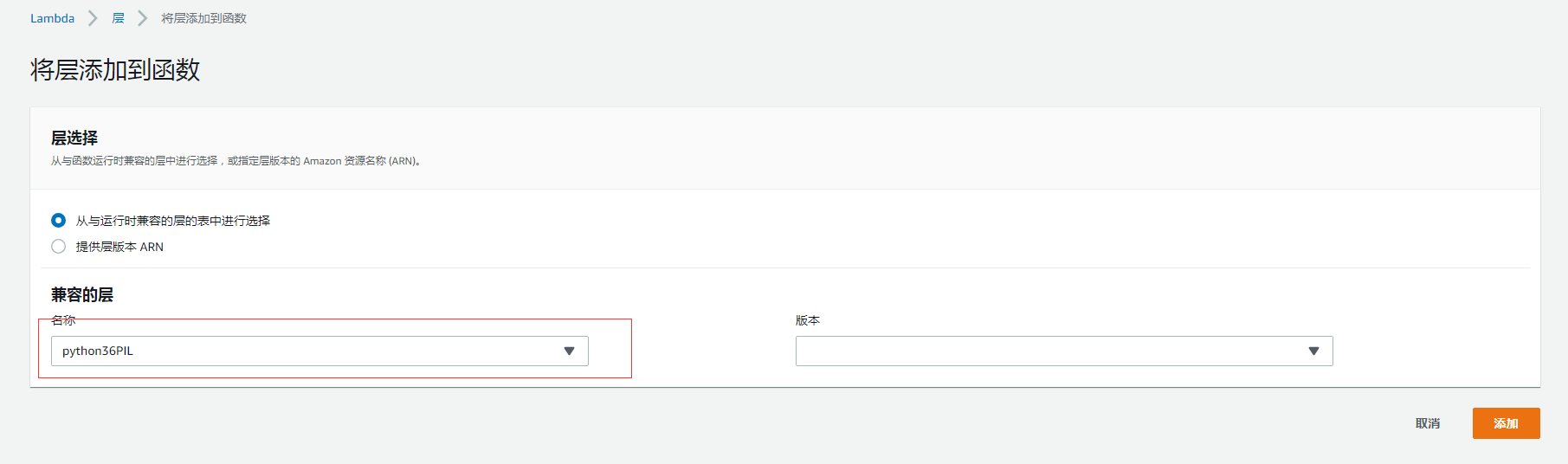
点击右上角的保存,这样就为这个函数添加了一个含有python 3.6 第三方包的层了。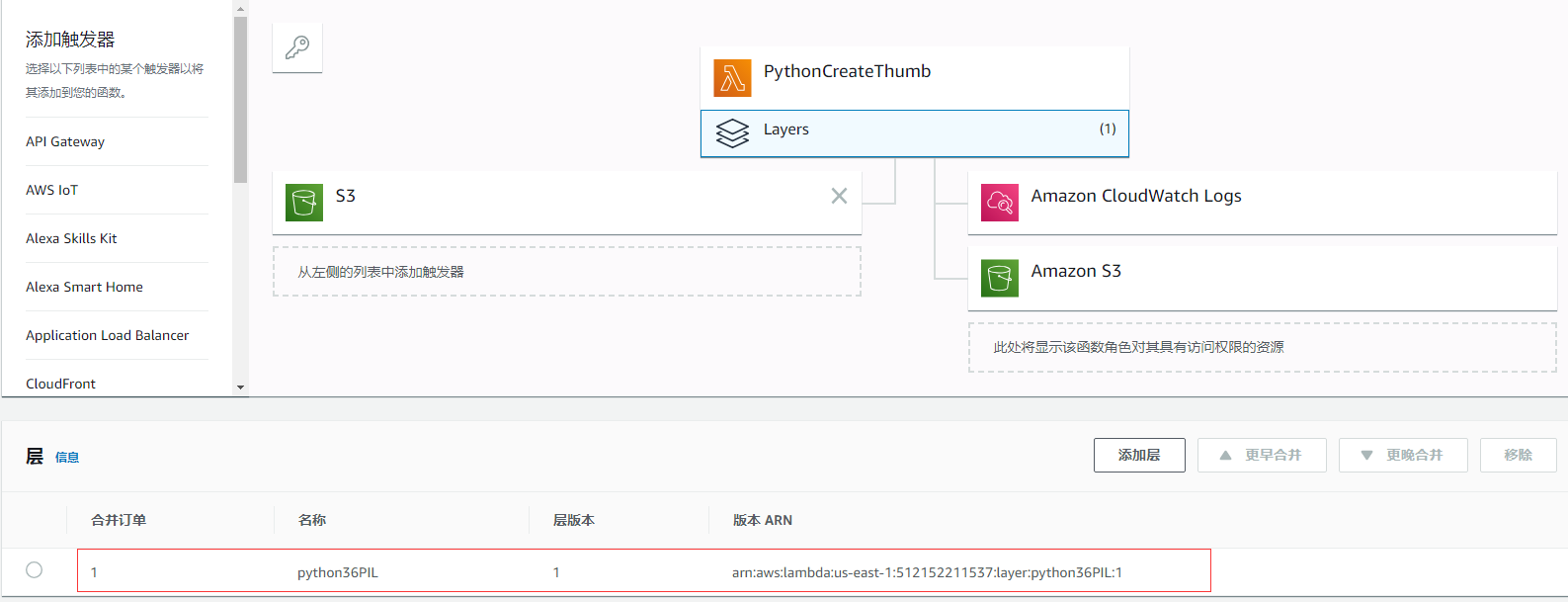
直接在线编辑执行的那个文件
既然已经有层来存放第三方库了,那么就只剩下一个入口文件了,而这个入口文件是可以直接写在这个在线编辑器的: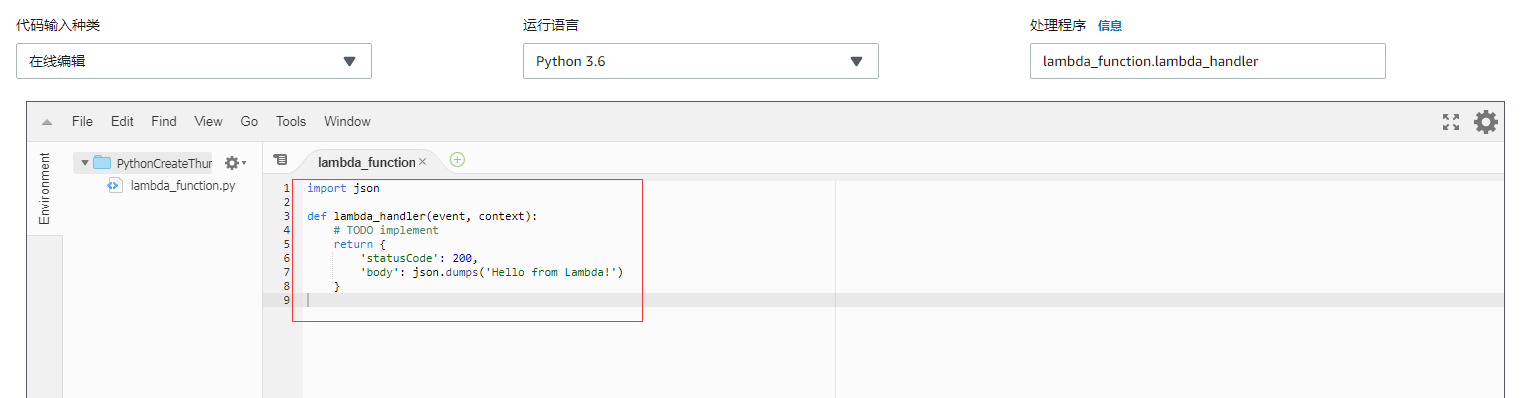
当然上面是预设值。所以后面直接改成我们的执行代码就可以了,1
2
3
4
5
6
7
8from __future__ import print_function
...
from PIL import Image, ImageFile
import PIL.Image
ImageFile.LOAD_TRUNCATED_IMAGES = True
def handler(event, context):
// do something
但是这边一定要注意一个问题,因为第三方库已经放到 layer 里面了,所以我们如果要引用 layer 里面的包,比如 PIL, 这边要预设一个 python 的环境变量,从而让 Lambda 函数在执行的时候,可以在 layer 层里面找到对应的包。
具体文档可以看:
- AWS Lambda 环境变量
- 关于python的执行环境变量的值,可以在这边找到:适用于 Lambda 函数的环境变量
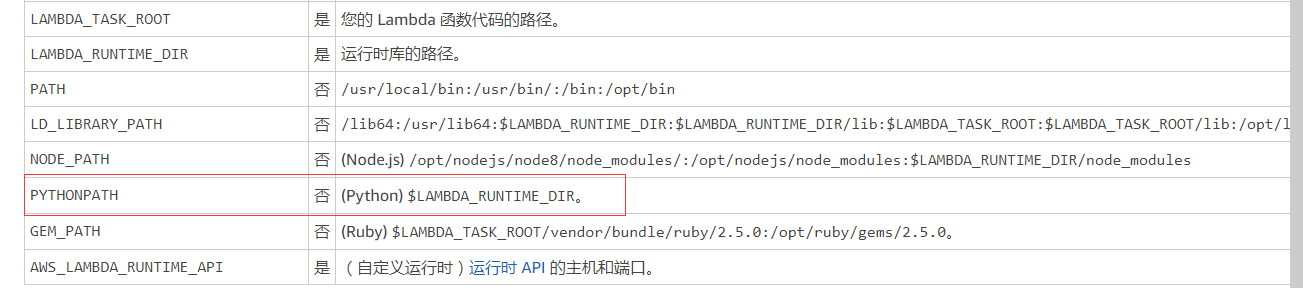
因为这个不是预设值,所以我是需要在这个函数里面手动添加的。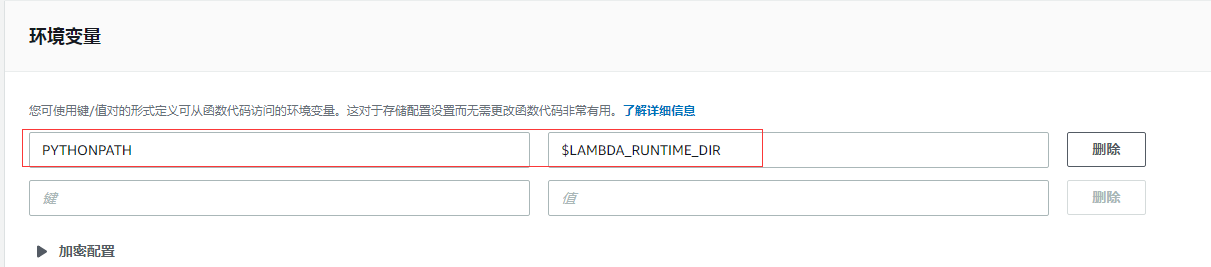
这样编辑器里面的入口文件就可以正常引用 layer 层里面的第三方包了。
添加 S3 bucket 的事件
接下来就是添加 S3 bucket 对应的触发器事件,这个跟我之前做的那个是一样的设置,只不过之前我还得跑到 S3 那边的 bucket 的配置项里面去设置,这次就直接在 Lambda 函数页面就可以配置了,很方便,不需要两地跑。
选择要应用的 bucket,并且选择要触发的事件,输入前缀和后缀。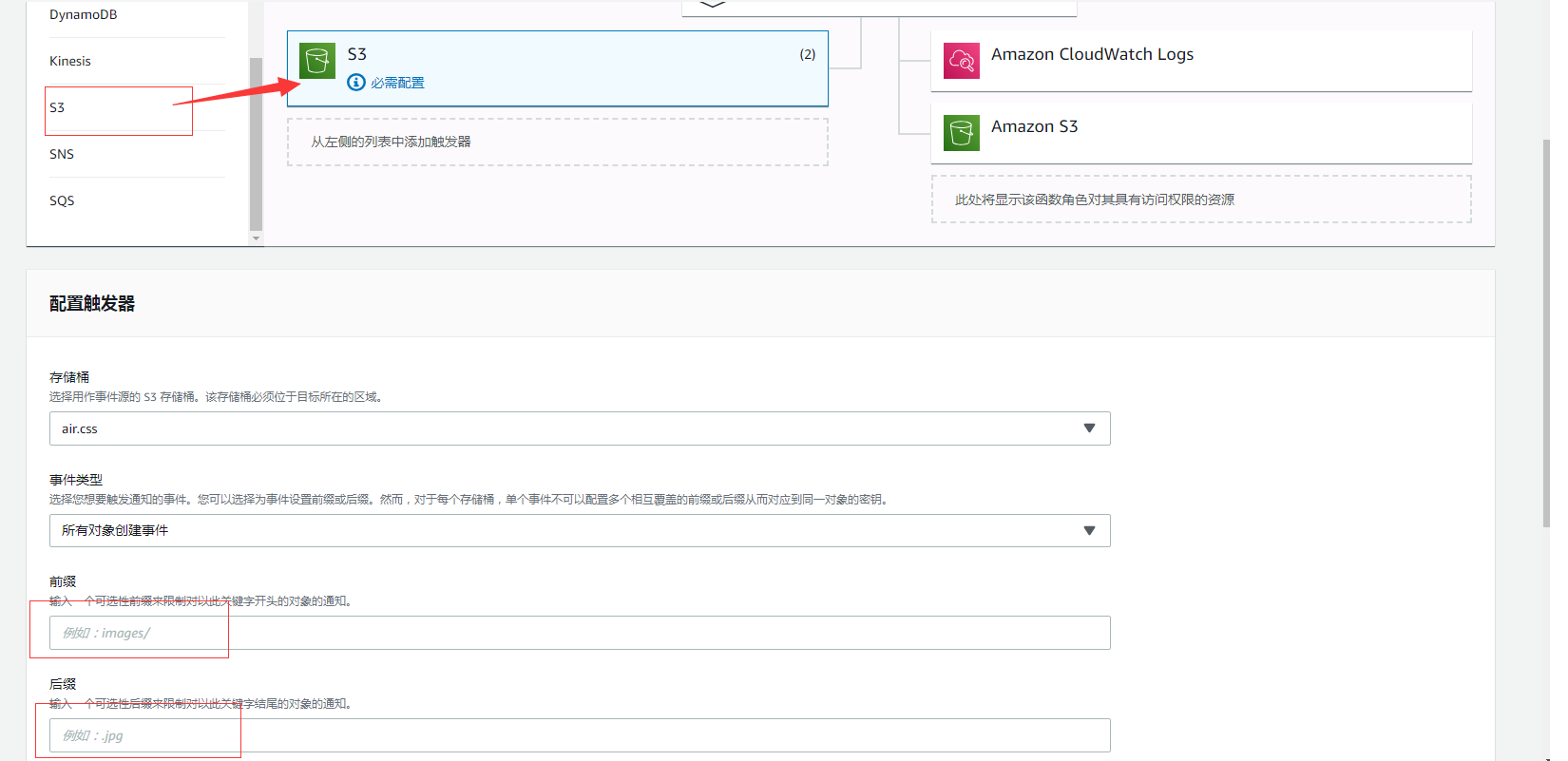
设置 CloudWatch Log 和 S3 的 ACL
这个跟之前一样,就不多说了。
在线测试
既然可以在线编辑入口文件逻辑,那么就可以在线进行测试了。因此我们可以自己配置一个测试事件,然后进行测试:
创建一个简单的 test 事件。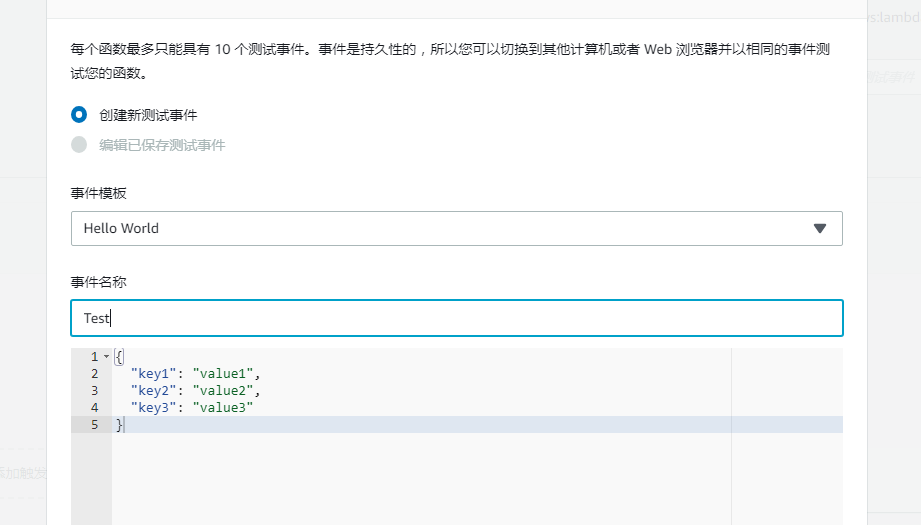
然后直接点击测试。就可以看到输出log了,下面的编辑器的 console 控制台也会对应输出 log: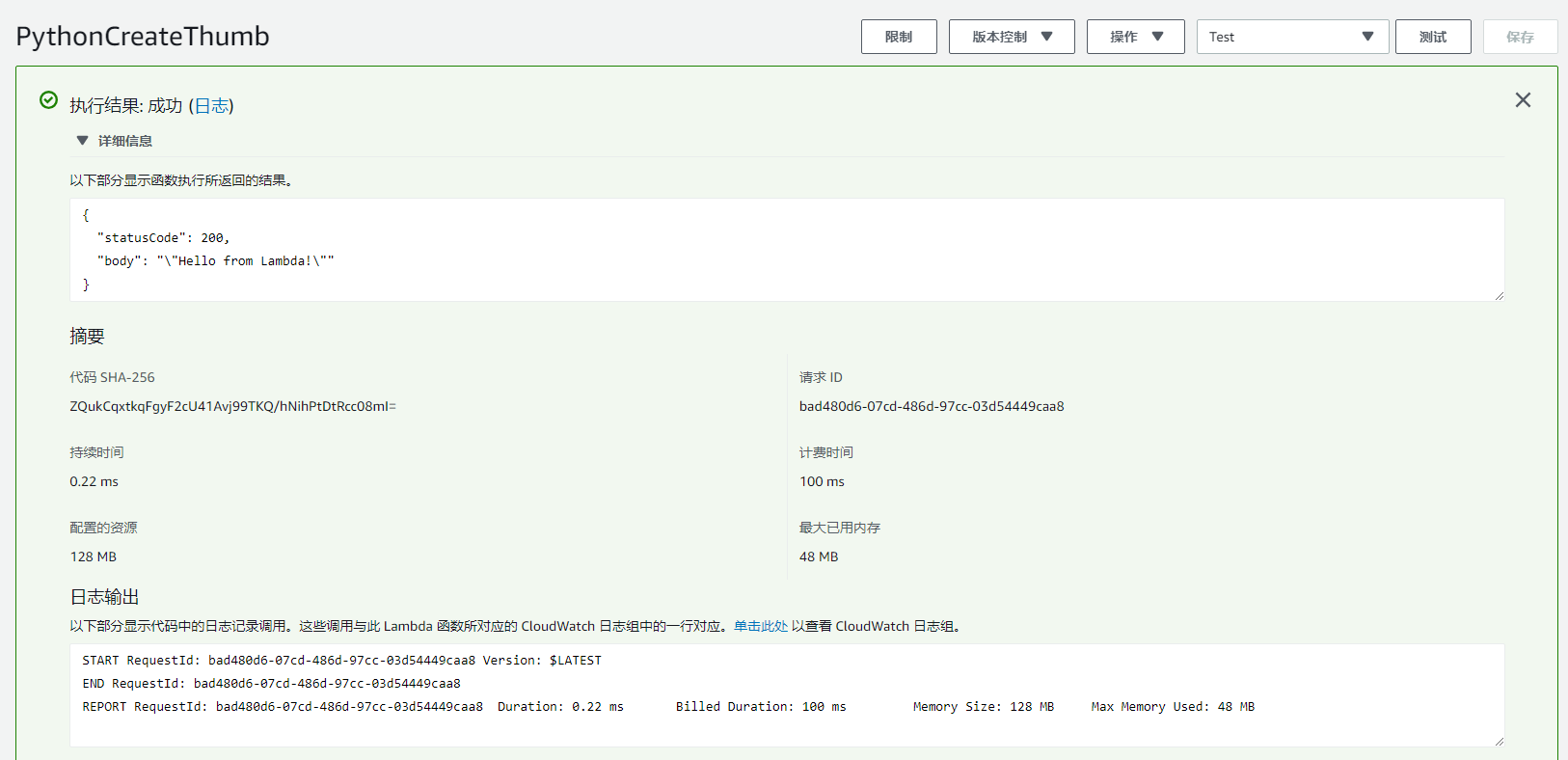
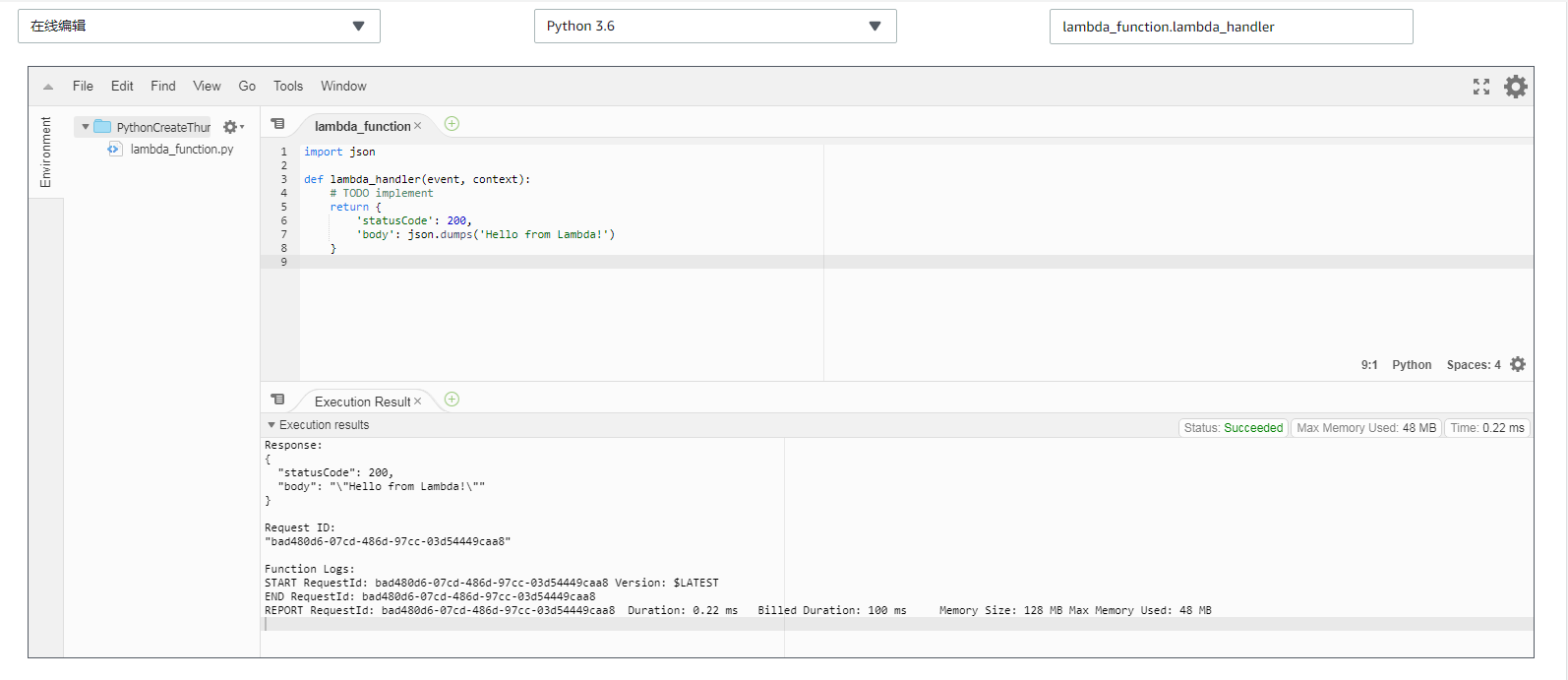
这样子基本上一个完成的流程就演示完成了。接下来我们进入到具体的实作环境
使用Lambda函数创建缩略图
上面的操作逻辑,已经讲的很清楚了,要注意的细节也说的很清楚了。接下来就开始实作,我们这一次不选用 python 语言来写,而是选用 nodejs 来写,换一种口味。
创建一个函数
选择 node 环境为 8.1
添加层
添加一个层,主要是需要用到的第三方库: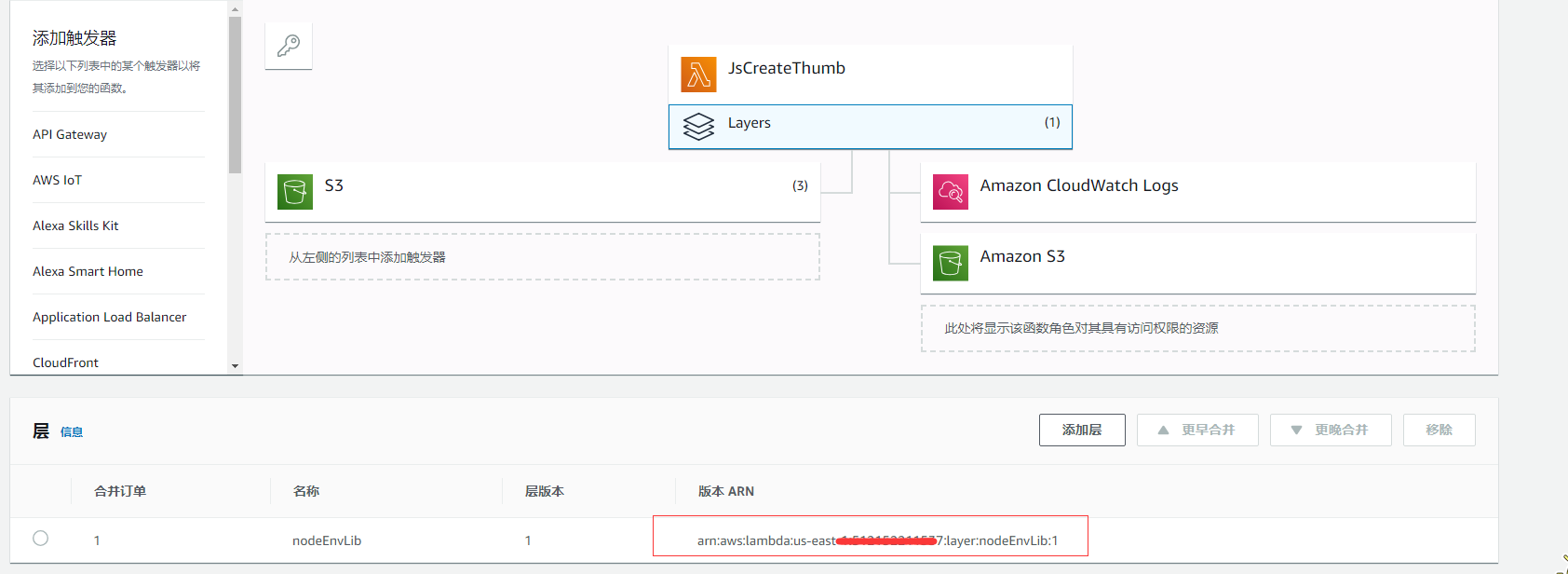
所涉及到的 package.json 如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18{
"name": "index",
"version": "1.0.0",
"description": "",
"main": "index.js",
"dependencies": {
"aws-sdk": "^2.462.0",
"async": "^3.0.0",
"gm": "^1.23.1",
"util": "^0.12.0"
},
"devDependencies": {},
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"author": "",
"license": "ISC"
}
简单的来说,就先本地创建一个项目,然后npm install 一下,然后再把 node_modules 目录外面再套上一层 nodejs 目录,最后打成 zip 包传上去就行了。
写代码
直接在线上编辑器写代码,代码主要是参照这个官方实例,然后做些调整就行了:将 AWS Lambda 与 Amazon S3 结合使用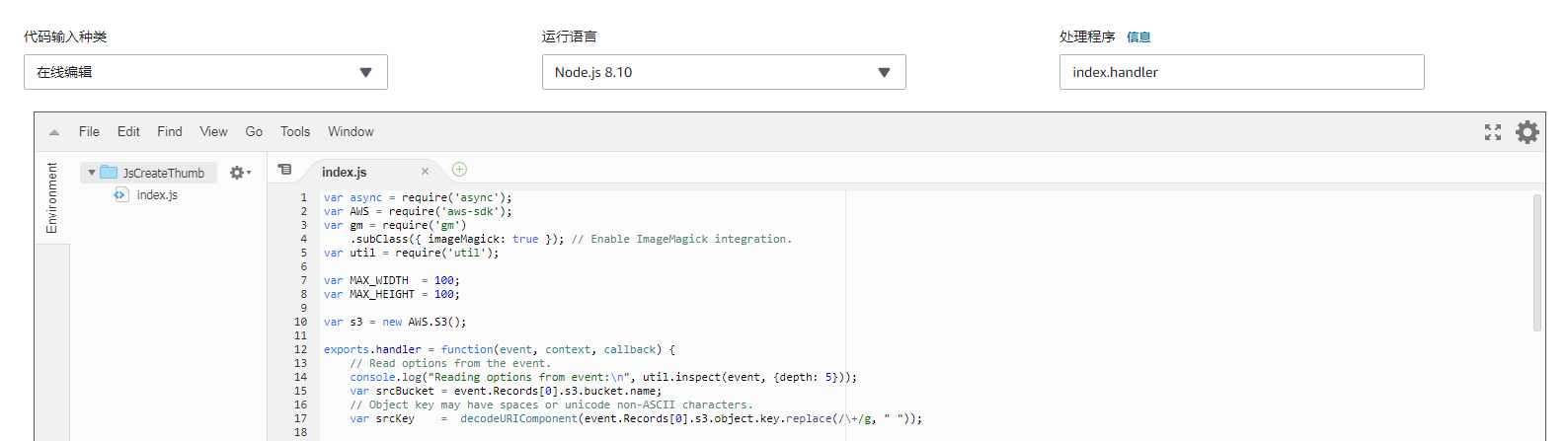
具体代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124var async = require('async');
var AWS = require('aws-sdk');
var gm = require('gm')
.subClass({ imageMagick: true }); // Enable ImageMagick integration.
var util = require('util');
var MAX_WIDTH = 100;
var MAX_HEIGHT = 100;
var s3 = new AWS.S3();
exports.handler = function(event, context, callback) {
// Read options from the event.
console.log("Reading options from event:\n", util.inspect(event, {depth: 5}));
var srcBucket = event.Records[0].s3.bucket.name;
// Object key may have spaces or unicode non-ASCII characters.
var srcKey = decodeURIComponent(event.Records[0].s3.object.key.replace(/\+/g, " "));
// Infer the image type.
var typeMatch = srcKey.match(/\.([^.]*)$/);
if (!typeMatch) {
callback("Could not determine the image type.");
return;
}
var imageType = typeMatch[1].toLocaleLowerCase();
if (imageType != "jpg" && imageType != "jpeg" &&imageType != "png" ) {
callback('Unsupported image type: ${imageType}');
return;
}
//获取环境变量
var env = process.env;
typeof env.SUFFIX_ARR === undefined ? callback("env variable error") : "";
var suffixArr = JSON.parse(env.SUFFIX_ARR);
var separator = env.SEPARATOR;
suffixArr.forEach(function(v,i){
//缩略图的key
var keyWithSuffix = srcKey+separator+v;
//图片缩放的比例
var ratio = v.split("p")[1];
ratio = parseInt(ratio);
if (ratio<=0){
console.log("ratio error ");
}else{
//转成百分比
ratio = ratio/100;
}
// Download the image from S3, transform, and upload to a different S3 bucket.
async.waterfall([
function checkExit(next){
s3.getObject({
Bucket: srcBucket,
Key:keyWithSuffix
},function(err,data) {
if (err){
next();
}else{
next(new Error("img has exit"));
}
});
},
function download(next) {
// Download the image from S3 into a buffer.
s3.getObject({
Bucket: srcBucket,
Key: srcKey
},
next);
},
function transform(response, next) {
console.log("transform");
// next(null, response.ContentType, response.Body);
gm(response.Body).size(function(err, size) {
// Infer the scaling factor to avoid stretching the image unnaturally.
console.log("gm debug");
var width = ratio * size.width;
var height = ratio * size.height;
console.log("resize");
// Transform the image buffer in memory.
this.resize(width, height)
.toBuffer(imageType, function(err, buffer) {
if (err) {
console.log("resize fail")
next(err);
} else {
console.log("resize success")
next(null, response.ContentType, buffer);
}
});
});
},
function upload(contentType, data, next) {
// Stream the transformed image to a different S3 bucket.
console.log("upload to s3")
s3.putObject({
Bucket: srcBucket,
Key: keyWithSuffix,
Body: data,
ContentType: contentType
},
next);
}
], function (err) {
if (err) {
console.error(
'Unable to resize ' + srcBucket + '/' + srcKey +
' and upload to ' + srcBucket + '/' + keyWithSuffix +
' due to an error: ' + err
);
} else {
console.log(
'Successfully resized ' + srcBucket + '/' + srcKey +
' and uploaded to ' + srcBucket + '/' +keyWithSuffix
);
}
callback(null, "message");
}
);
});
};
逻辑就不多说了,就跟我上面分析的逻辑一样,不过要注意几个东西,尤其是环境变量,这边要设置几个环境变量: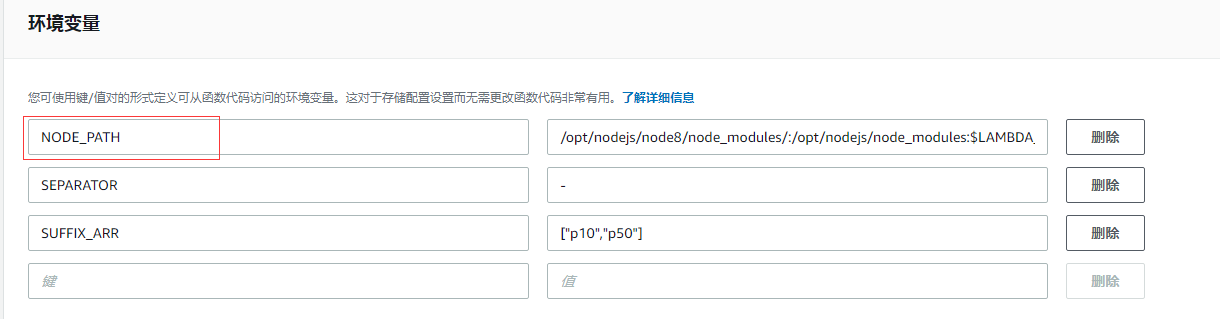
NODE_PATH 就不用多说了,因为要引用 layer 里面的库,那么就要设置 node path,这边主要讲另外两个,
- SEPARATOR 这个就是分隔符,因为要跟七牛的缩略图的格式一样,所以这边也要设置中划线的分隔符
- SUFFIX_ARR 后缀数组,其实就是要生成的缩略图的比例,这个是一个数组,[“p10”,”p50”],一样为了跟七牛的格式一致,所以后缀名也要一样,然后将缩放比例也隐藏在后缀名里面,其实就是后两位
接下来添加对应 S3 bucket的事件
针对 jpg, jpeg, png, 这三种图片格式,并且是有设置前缀的。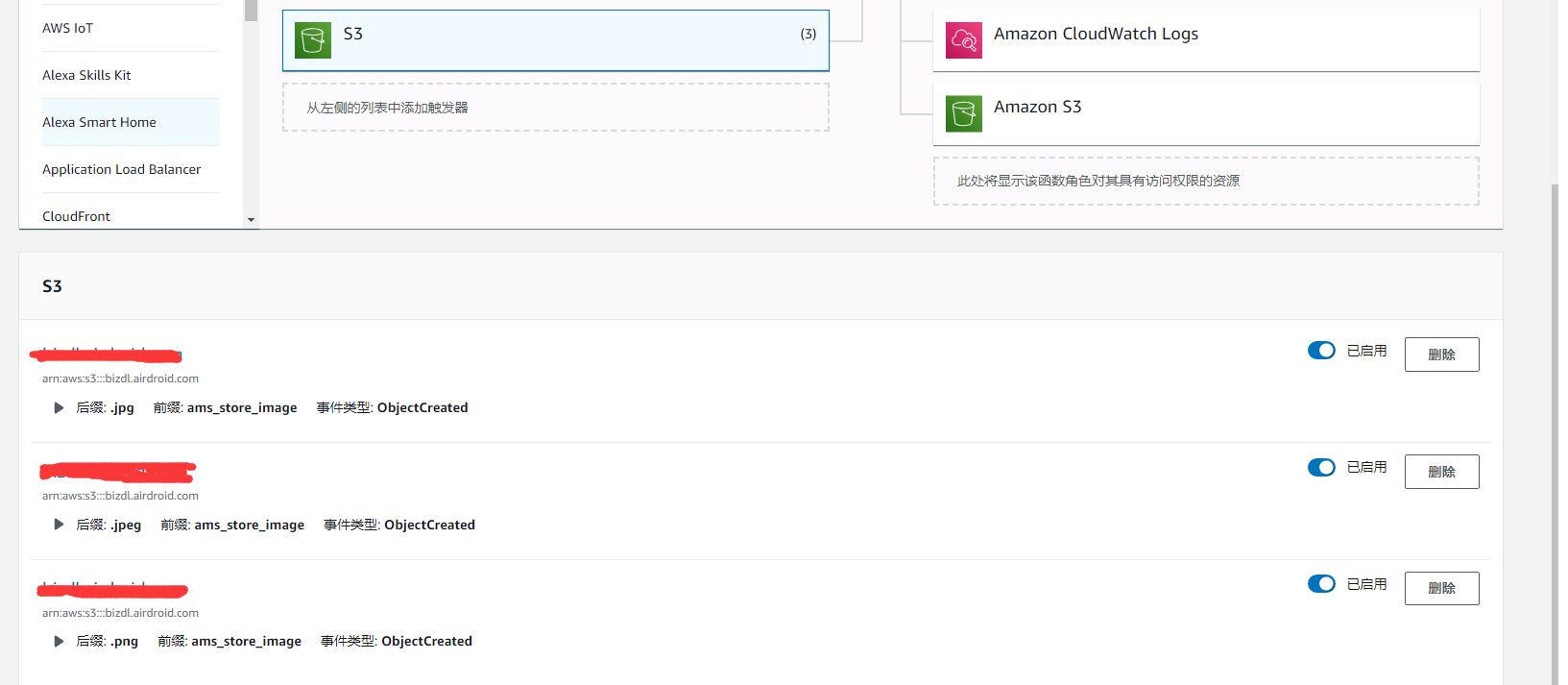
设置超时时间
之前的时间是 3s,担心对于大图片有时候会超时,所以就设置成长一点,加了一分钟: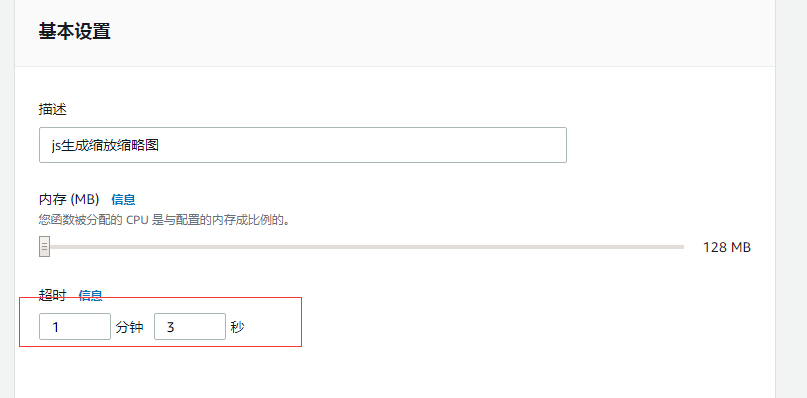
测试
全部配好了,接下来就是测试了,我们创建一个测试事件,因为我们是依赖 S3 的 put 事件,所以我们就创建了一个基于 Amazon S3 Put 的事件: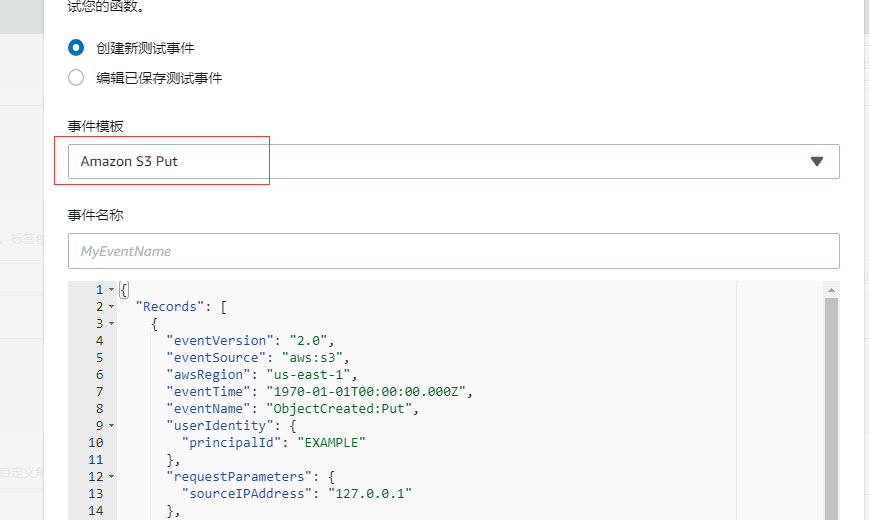
然后要修改一下,找到这个 bucket 的某一张图片,填对对应的值: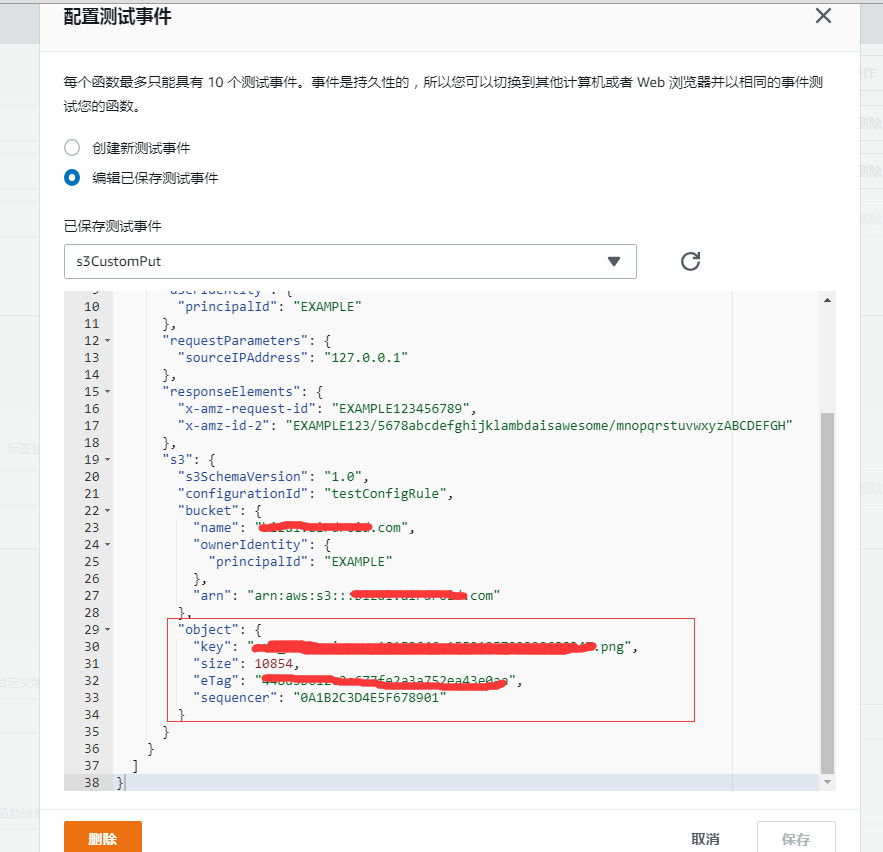
对应的数据要去 bucket 里面对应的资源去拿: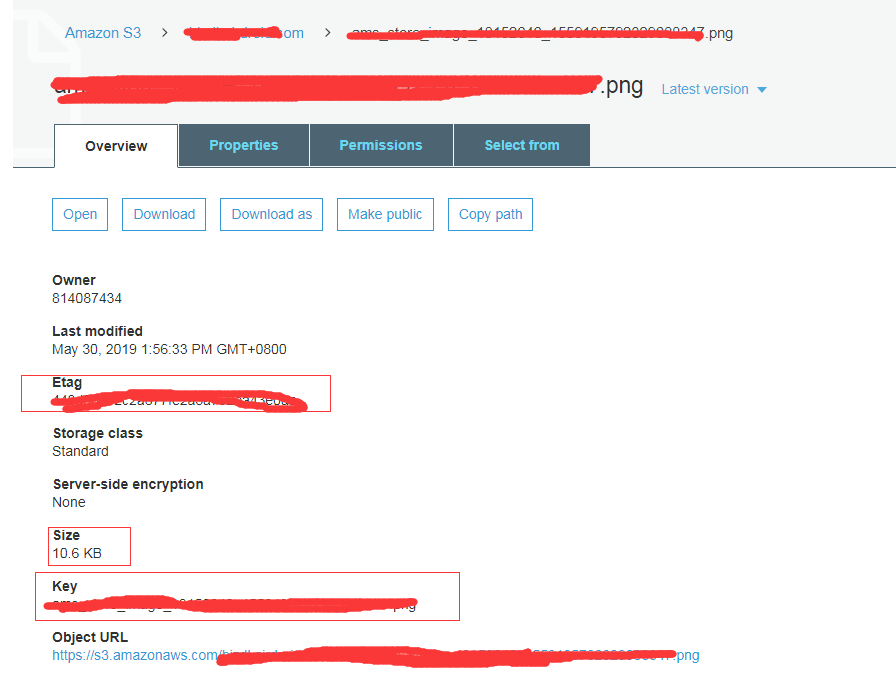
接下来开始测试:点击测试,就会开始触发 S3 的 PUT,然后就会开始触发我们的函数,就会针对这个图片文件进行分析和处理: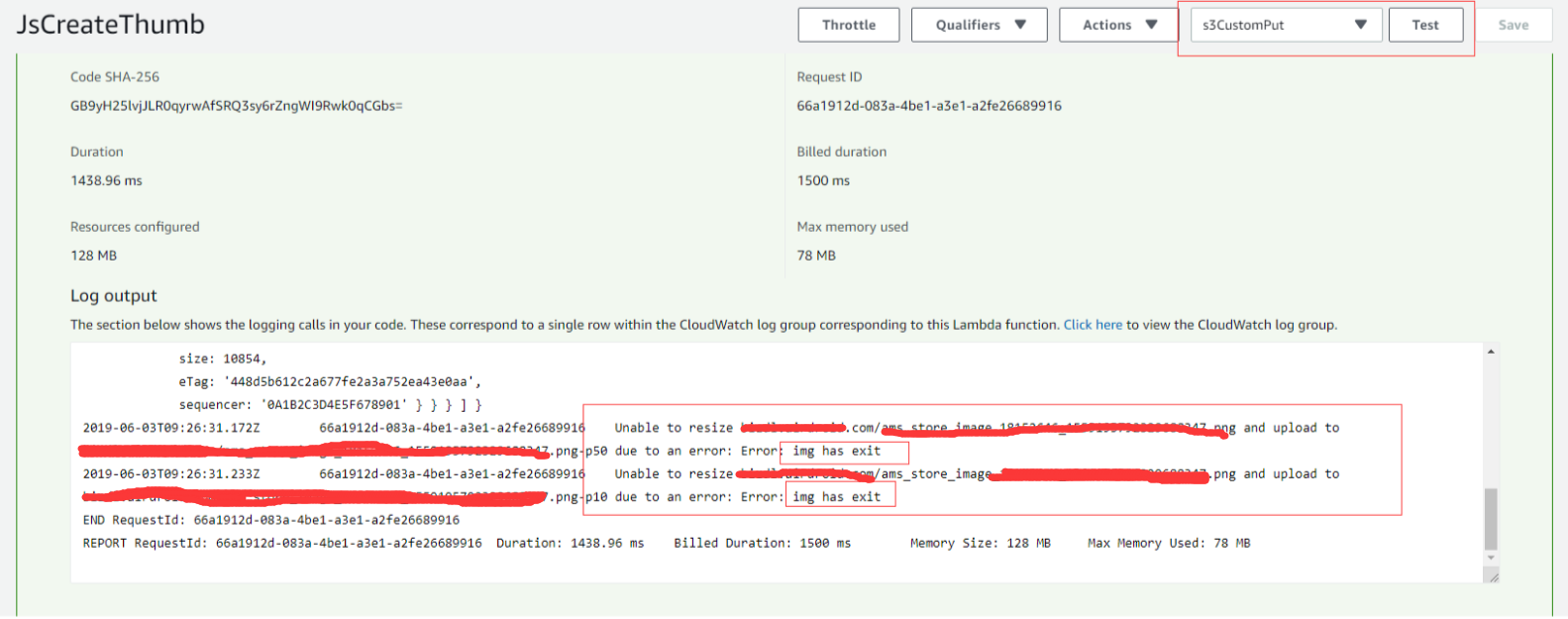
当然编辑器下面的console也会输出log,这两个 log 是一样的,所以我只贴一份, 而且因为这个文件之前就被我们测试过了,所以缩略图已经在bucket存在了,所以就会返回img has exist, 所以这个测试是对的。
总结
通过以上对 S3 Lambda 的处理,我们就可以将 S3 的缩略图处理的跟七牛的缩略图的路径一样,就跟原图一样, 从而实现缩略图的基于不同地区的 CDN 路由解析。从而大大的提高了访问速度。
不过要注意一点的是,S3 的 Lambda 函数处理毕竟是需要时间的,所以有时候,一上传之后,马上就访问缩略图,这时候这个缩略图路径是不存在的,会报错误,所以要等一会儿再请求才能请求的到。