前言
之前从 基于 prometheus 打造监控报警后台 (1) - 初试和安装 我们安装了 prometheus 服务,并且监控了当前的主机。 但是数据是有抓取了,怎么看指标乃至图表呢?
从后台查询指标
我们可以从 prometheus ui 后台的 graph 里面来查看, 他有两个 tab 视图展示,一个是 Graph 的图表展示,一个是 Table 的表格展示, 通过输入某一个指标 (Metric),我们就可以查看所有实例中有关于这个指标的所有的数据。 其中有表格形式展示的, 也有图表形式展示,图表形式还可以自己选择时间区间
然后查询的方式,提供了一种称为 PromQL 的函数式查询语言,可以让用户实时选择和聚合时间序列数据。表达式的结果可以显示为图形,也可以以表格数据的形式查看,或者由外部系统通过HTTP API 使用。
PromQL(Prometheus Query Language)是 Prometheus 自己开发的表达式语言,语言表现力很丰富,内置函数也很多。使用它可以对时序数据进行筛选和聚合。
关于查询的话,官网有提供了几个查询实例可供参考: 查询示例
其中包括几个常见的,比如:
返回所有带有指标的时间序列 prometheus_http_requests_total (这个是一个瞬时向量):1
prometheus_http_requests_total
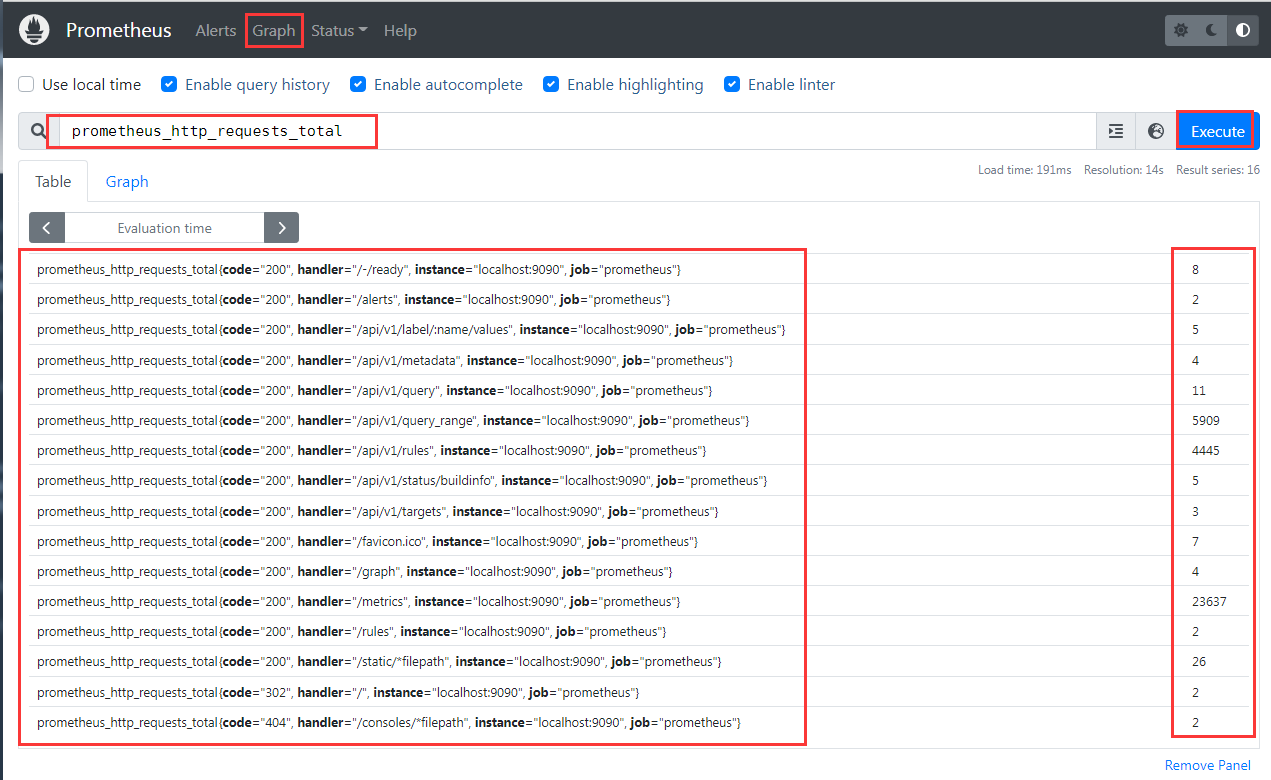
返回所有带有度量prometheus_http_requests_total 和给定 job 标签 handler 的时间序列:1
prometheus_http_requests_total{job="prometheus",handler="/metrics"}
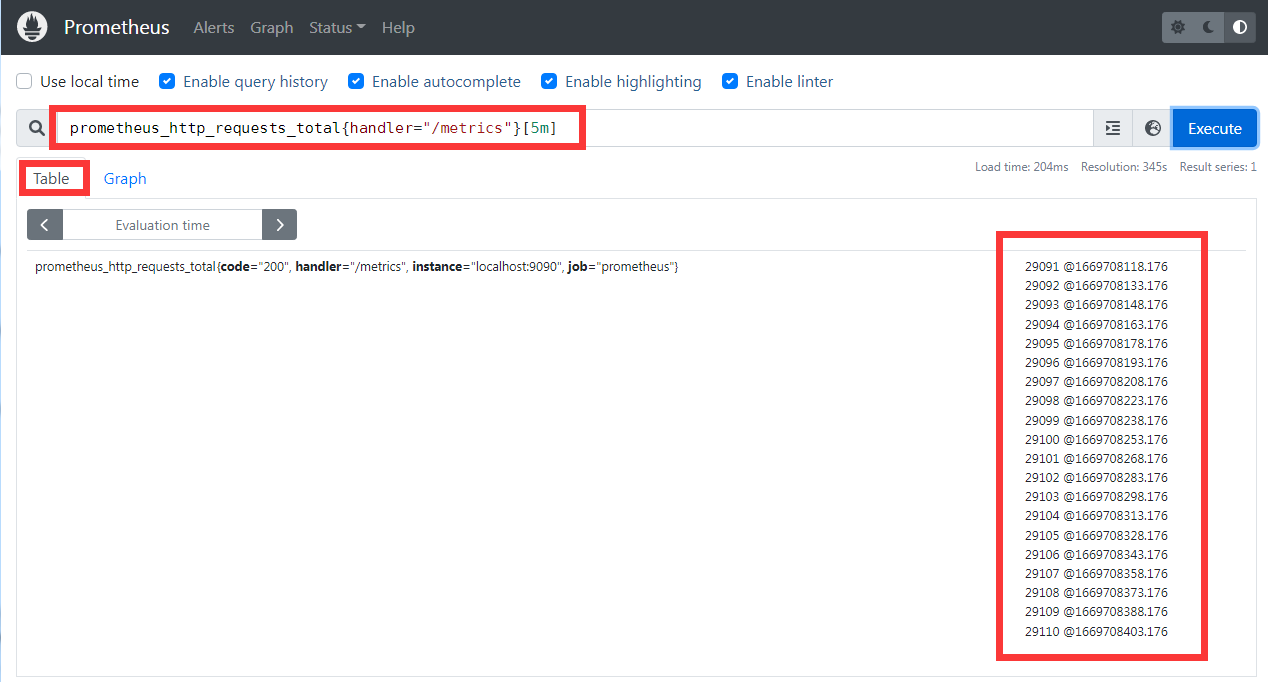
返回同一向量的整个时间范围(在本例中为查询时间之前的 5 分钟),使其成为一个范围向量:1
prometheus_http_requests_total{handler="/metrics"}[5m]
请注意,在
Graph tab页面无法直接绘制生成范围向量的表达式 ,但可以在Table tab视图中查看。 比如这个
当然也可以使用正则表达式,您可以仅为名称与特定模式匹配的作业选择时间序列,在本例中,所有以以下结尾的作业 server:1
http_requests_total{job=~".*server"}
Prometheus 中的所有正则表达式都使用 RE2 语法。
PromQL 表达式语言数据类型
在 Prometheus 的表达式语言中,表达式或子表达式可以计算为四种类型之一:
- 即时向量(Instant vector) - 一组时间序列,每个时间序列包含一个样本,所有样本共享相同的时间戳。也就是说,表达式的返回值中只会包含该时间序列中的最新的一个样本值。而相应的这样的表达式称之为瞬时向量表达式
- 范围向量(Range vector) - 一组时间序列,其中包含每个时间序列随时间变化的一系列数据点。这些是通过将时间选择器附加到方括号中的瞬时向量(例如
[5m]5 分钟)而生成的 - 标量(Scalar)- 一个简单的数字浮点值
- 字符串(String) - 一个简单的字符串值;目前未使用
关于 PromQL 的更多的语法,可以看: QUERYING PROMETHEUS, 后面会单独找个篇幅讲一下这个
接下来要分析这些指标数据之前,我们先熟悉几个概念。
作业(job)和实例(instance)
在查看指标之前,先科普一个概念 -> 作业和实例
这一块官方文档其实描述的很清楚,在 Prometheus 术语中,可以抓取的端点称为实例,通常对应于单个进程。具有相同目的的实例集合,例如为可伸缩性或可靠性而复制的过程,称为作业。
简单来说,就是作业其实就是配置文件 scrape_configs 节点中的 job 节点, 而实例就是 job 节点中的 target 节点,以上个例子的配置文件的抓取配置来看:1
2
3
4
5
6
7
8scrape_configs:
- job_name: "prometheus"
static_configs:
- targets: ["localhost:9090"]
- job_name: "node1"
static_configs:
- targets: ["localhost:9100"]
说明有两个作业:
- prometheus
- node1
每一个作业都对应一台实例 (可以配置多个)。 而 prometheus server 就会去定期(根据 scrape_interval 参数)去执行这些作业,然后具体体现在去这些作业下配置的实例的 url 上去拉数据。
自动生成的标签和时间序列
prometheus 他是一个时序数据库, 从根本上存储的所有数据都是时间序列数据(Time Series Data,简称时序数据)。时序数据是具有时间戳的数据流,该数据流属于某个度量指标(metrics name)和该度量指标下的多个标签(labelset)。
每个时间序列(Time Series,简称时序)由度量指标和一组标签键值对唯一确定。
以我们刚才装的 prometheus server 来说, 他的抛送请求的数据是这样子的
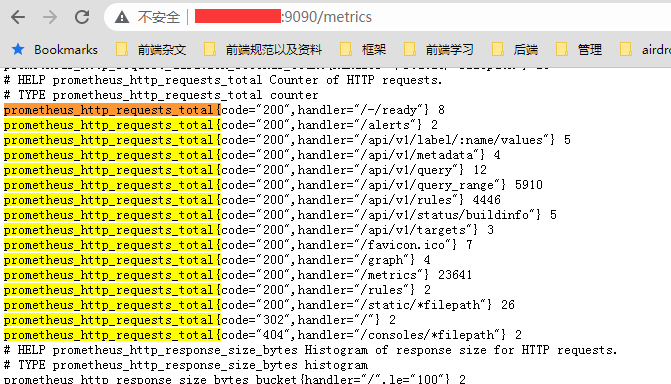
而这个每一行(非 # 开头的注释行)就是一个时间序列数据,都会被 prometheus 存入到时序数据库。
当 Prometheus 抓取目标时,它会自动将一些标签附加到抓取的时间序列上,用于识别抓取的目标:
- job:目标所属的已配置作业名称。
- instance:
<host>:<port>被抓取的目标 URL 部分。
所以我们可以看到在抛送的时候,没有 job 和 instance 这两个标签,但是查询的时候,会出现这两个标签,因为这两个是自动添加

不仅如此,在 prometheus 每次抓取的时候,都会自动添加以下的几个 时间序列数据:
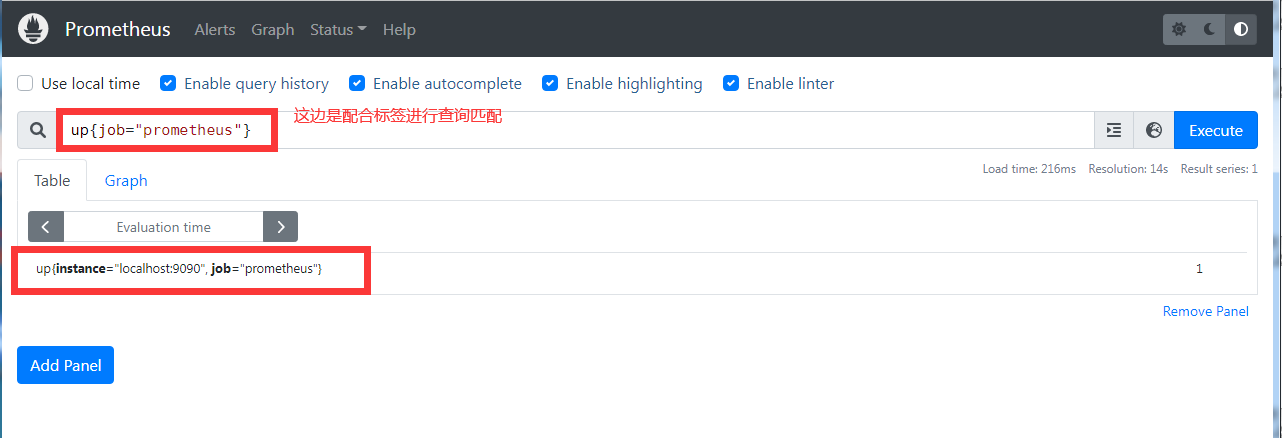
up{job="<job-name>", instance="<instance-id>"}:1如果实例健康,即可达,或者0如果抓取失败。scrape_duration_seconds{job="<job-name>", instance="<instance-id>"}:抓取的持续时间。scrape_samples_post_metric_relabeling{job="<job-name>", instance="<instance-id>"}:应用度量重新标记后剩余的样本数。scrape_samples_scraped{job="<job-name>", instance="<instance-id>"}:目标暴露的样本数。scrape_series_added{job="<job-name>", instance="<instance-id>"}:本次抓取中新系列的大概数量。v2.10 中的新功能
up 时间序列对于实例可用性监控很有用。
所以虽然我们在 metrics 接口看不到这些数据, 但是在后台使用指标查询的时候,是可以查询到的,比如这样子
数据模型
上述说过,每个时间序列(Time Series,简称时序)由度量指标和一组标签键值对唯一确定。 而在 prometheus 中,会将所有的数据存储为时间序列,属于同一指标和同一组标记维度的时间戳值流。
Prometheus 会将所有采集到的样本数据以时间序列的方式保存在内存数据库中,并且定时保存到硬盘上(默认2小时,可以根据启动参数进行修改)。时间序列是按照时间戳和值的序列顺序存放的,我们称之为向量(vector),每条时间序列通过指标名称(metrics name)和一组标签集(labelset)命名。
如下所示,可以将时间序列理解为一个以时间为 X 轴的数字矩阵:
1 | ^ |
在时间序列中的每一个点称为一个样本(sample),样本由以下三部分组成:
- 指标(metric):指标名和描述当前样本特征的标签集合。
- 时间戳(timestamp):一个精确到毫秒的时间戳
- 样本值(value): 一个 float64 的浮点型数据表示当前样本的值
其中指标(metric) 由两部分组成: 指标名称 + 标签组键值对:1
[metric name]{[label name]=[label value], ...}
比如度量指标为 prometheus_http_requests_total,标签为 code="200"、handler="/metrics" 的抛送数据可以这样子写1
prometheus_http_requests_total{code="200",handler="/metrics"} 23641
但是这个并不是完整的一个时间序列样本的数据模型,因为时序数据肯定是要带上时间的, 所以真的入库,是以这样子的方式入库的1
2<---------------------------- metric -----------------------><-- timestamp --><-value->
prometheus_http_requests_total{code="200",handler="/metrics"} @1434417560938 => 23641
之所以
"/metrics"不显示时间戳是因为这个是 prometheus 自己当下采集的时候统一标记加的。不需要数据抛送接口额外加
指标的名称可以反映被监控样本的含义(比如,
http_request_total表示当前系统接收到的 HTTP 请求总量)。指标名称只能由 ASCII 字符、数字、下划线以及冒号组成并必须符合正则表达式[a-zA-Z_:][a-zA-Z0-9_:]*。
标签(label)反映了当前样本的特征维度,通过这些维度 Prometheus 可以对样本数据进行过滤,聚合等。标签的名称只能由 ASCII 字符、数字以及下划线组成并满足正则表达式
[a-zA-Z_][a-zA-Z0-9_]*。 标签值可以包含任何 Unicode 字符。
具有空标签值的标签被认为等同于不存在的标签。
指标类型
从存储上来讲所有的监控指标都是相同的,但是在不同的场景下这些指标又有一些细微的差异。
例如,在 Node Exporter 返回的样本中指标 node_load1 反应的是当前系统的负载状态,随着时间的变化这个指标返回的样本数据是在不断变化的。而指标 node_cpu_seconds_total 所获取到的样本数据却不同,它是一个持续增大的值,因为其反应的是 CPU 的累计使用时间,从理论上讲只要系统不关机,这个值是会一直变大。
为了能够帮助用户理解和区分这些不同监控指标之间的差异,Prometheus 定义了 4 种不同的指标类型:
- Counter(计数器)
- Gauge(仪表盘)
- Histogram(直方图)
- Summary(摘要)
正常情况下,我们可以在抛送的时序数据的对应的注释中,来查看这个指标的类型,比如:1
2
3# HELP prometheus_http_requests_total Counter of HTTP requests.
# TYPE prometheus_http_requests_total counter
prometheus_http_requests_total{code="200",handler="/-/ready"} 8
1. Counter(计数器)
Counter (只增不减的计数器) 类型的指标其工作方式和计数器一样,只增不减,所以它对于存储诸如服务的 HTTP 请求数量或使用的 CPU 时间之类的信息非常有用。
常见的监控指标,如 http_requests_total、node_cpu_seconds_total 都是 Counter 类型的监控指标。
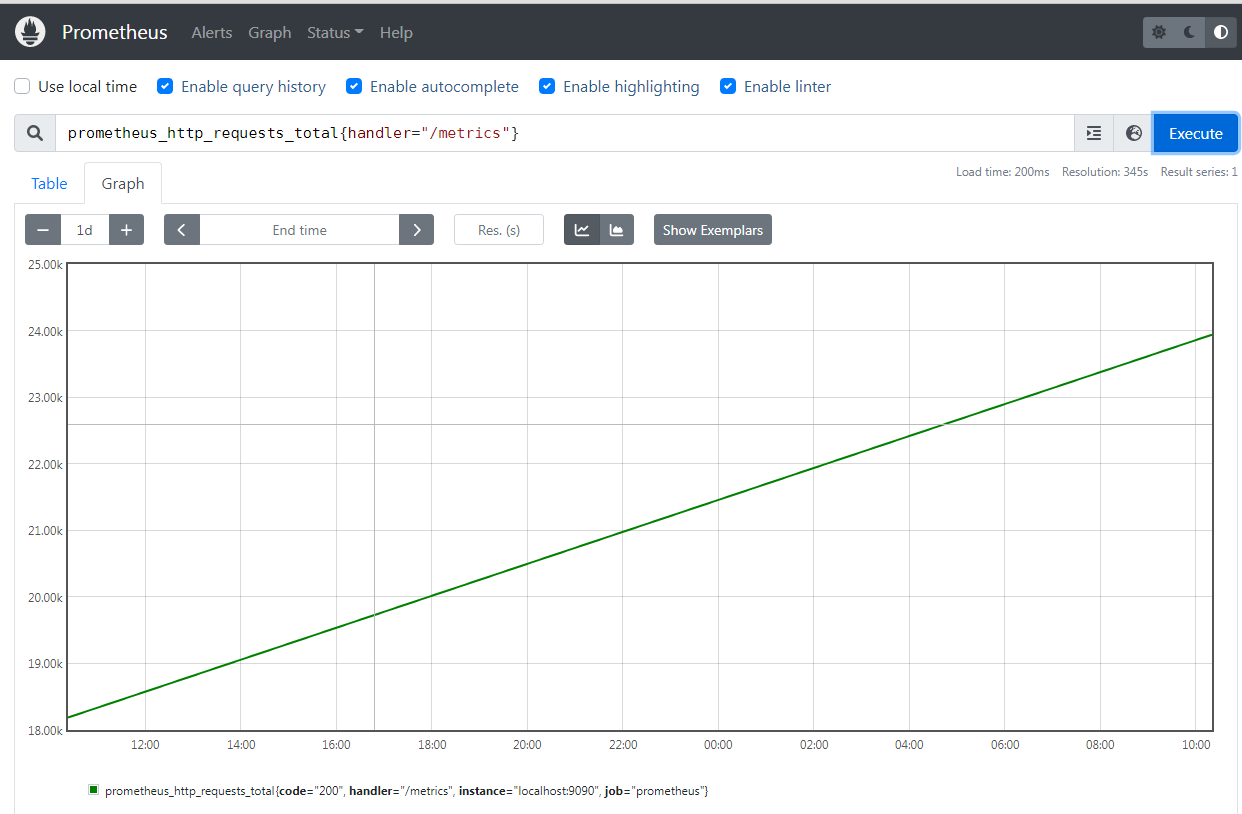
这个就是一个很明显的 Counter 类型的监控指标
可能你会觉得一直增加的数据没什么用处,了解服务从开始有多少请求有什么价值吗?但是需要记住,每个指标都存储了时间戳的,所有你的 HTTP 请求数现在可能是 1000 万,但是 Prometheus 也会记录之前某个时间点的值,我们可以去查询过去一个小时内的请求数,当然更多的时候我们想要看到的是请求数增加或减少的速度有多快,因此通常情况对于 Counter 指标我们都是去查看变化率而不是本身的数字。
PromQL 内置的聚合操作和函数可以让用户对这些数据进行进一步的分析,例如,通过 rate() 函数获取 prometheus server HTTP 请求的增长率:
1 | rate(prometheus_http_requests_total{job="prometheus"}[5m]) |
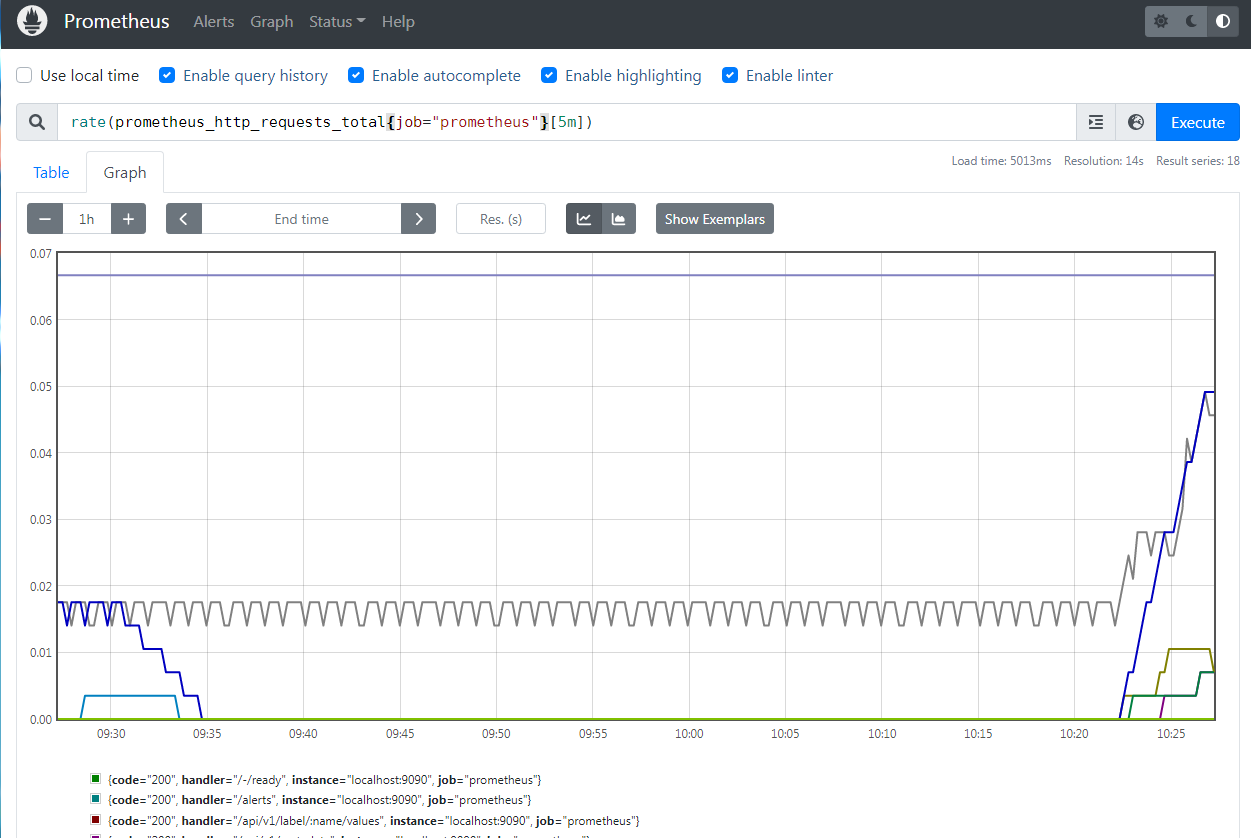
2. Gauge (仪表盘)
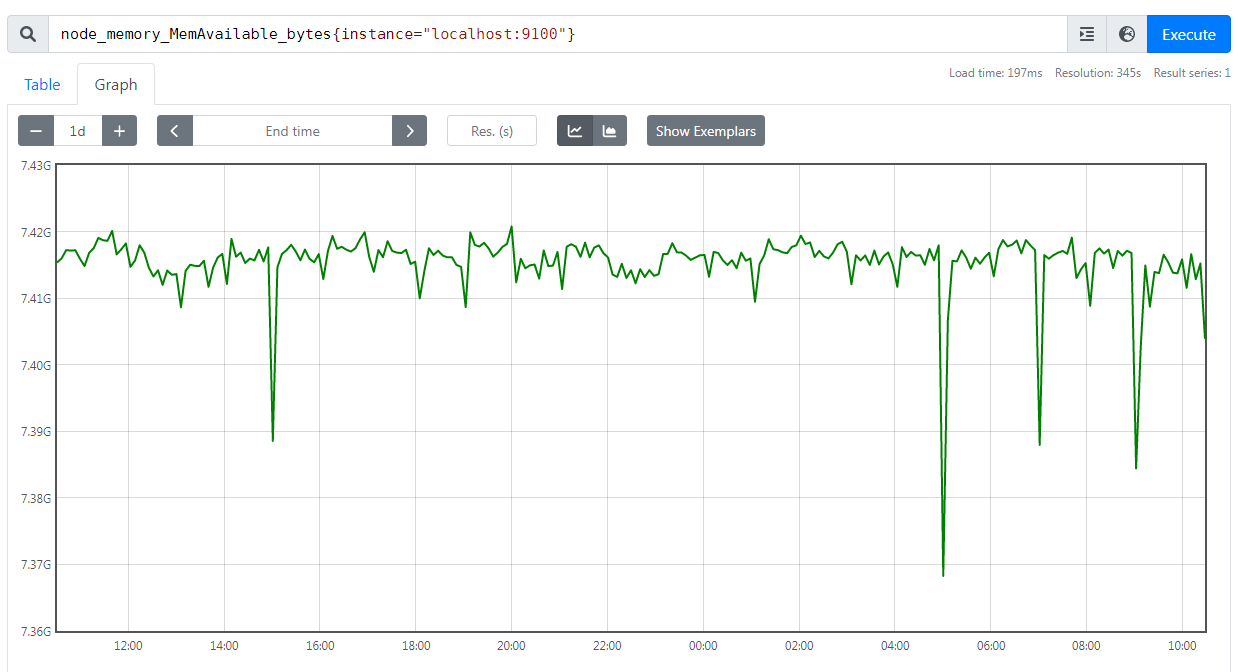
与 Counter 不同,Gauge(可增可减的仪表盘)类型的指标侧重于反应系统的当前状态,因此这类指标的样本数据可增可减。
常见指标如 node_memory_MemFree_bytes(当前主机空闲的内存大小)、node_memory_MemAvailable_bytes(可用内存大小)都是 Gauge 类型的监控指标。
由于 Gauge 指标仍然带有时间戳存储,所有我们可以看到随时间变化的值,通常可以直接把它们绘制出来,这样就可以看到值本身而不是变化率了,通过 Gauge 指标,用户可以直接查看系统的当前状态。
PromQL 的功能类似于 max_over_time,min_over_time 并且 avg_over_time, delta 可以用于仪表指标, 比如计算 CPU 温度在两个小时内的差异:1
delta(cpu_temp_celsius{host="node01"}[2h])
还可以直接使用 predict_linear() 对数据的变化趋势进行预测。例如,预测系统磁盘空间在 4 个小时之后的剩余情况:1
predict_linear(node_filesystem_free_bytes[1h], 4 * 3600)
3. Histogram(直方图)
与前两种相比,直方图是一种更复杂的度量类型。直方图可用于任何基于桶值计算的计算值。桶边界可以由开发者配置。一个常见的例子是回复请求所需的时间,称为延迟。
举例:假设我们想要观察处理 API 请求所花费的时间。直方图允许我们将它们存储在桶中,而不是存储每个请求的请求时间。
我们为所用时间定义桶,例如 lower or equal 0.3、le 0.5、le 0.7、le 1和le 1.2。 所以这些是我们的桶,一旦计算出请求所花费的时间,它就会被添加到桶边界高于测量值的所有桶的计数中。
在 Prometheus Server 自身返回的样本数据中,我们也能找到类型为 Histogram 的监控指标 prometheus_http_request_duration_seconds_bucket , 也就是上述所说的,用于按区间计算某一个 api 的直方图1
2
3
4
5
6
7
8
9
10
11
12
13
14# HELP prometheus_http_request_duration_seconds Histogram of latencies for HTTP requests.
# TYPE prometheus_http_request_duration_seconds histogram
prometheus_http_request_duration_seconds_bucket{handler="/graph",le="0.1"} 4
prometheus_http_request_duration_seconds_bucket{handler="/graph",le="0.2"} 4
prometheus_http_request_duration_seconds_bucket{handler="/graph",le="0.4"} 4
prometheus_http_request_duration_seconds_bucket{handler="/graph",le="1"} 4
prometheus_http_request_duration_seconds_bucket{handler="/graph",le="3"} 4
prometheus_http_request_duration_seconds_bucket{handler="/graph",le="8"} 4
prometheus_http_request_duration_seconds_bucket{handler="/graph",le="20"} 4
prometheus_http_request_duration_seconds_bucket{handler="/graph",le="60"} 4
prometheus_http_request_duration_seconds_bucket{handler="/graph",le="120"} 4
prometheus_http_request_duration_seconds_bucket{handler="/graph",le="+Inf"} 4
prometheus_http_request_duration_seconds_sum{handler="/graph"} 0.000327554
prometheus_http_request_duration_seconds_count{handler="/graph"} 4
上述就是 prometheus server 用来统计 /graph 路由请求时间的直方图, 可以看到他分为了这几个区间
| bucket | count |
|---|---|
| 0 - 0.1 | 4 个 |
| 0 - 0.2 | 4 个 |
| 0 - 0.4 | 4 个 |
| 0 - 1 | 4 个 |
| 0 - 3 | 4 个 |
| 0 - 8 | 4 个 |
| 0 - 20 | 4 个 |
| 0 - 60 | 4 个 |
| 0 - 120 | 4 个 |
0 - > 120 (+Inf) |
4 个 |
注意:+Inf 桶是默认添加的。
而且这个直方图是累计叠加的,所有大于该值的桶都要加 1 (所以大区间的值会包含小区间的值)。 从上面可以看出所有的区间都是 4 个, 所以在这个时间周期之类, prometheus server 有响应了 4 次的 /graph 请求,并且所有的响应时间都小于 0.1s
假设这时候服务器的负载高一点,有一个请求的响应时间是 0.5s 的情况下,那么上面的区间数字就会变成
| bucket | count |
|---|---|
| 0 - 0.1 | 4 个 |
| 0 - 0.2 | 4 个 |
| 0 - 0.4 | 4 个 |
| 0 - 1 | 5 个 |
| 0 - 3 | 5 个 |
| 0 - 8 | 5 个 |
| 0 - 20 | 5 个 |
| 0 - 60 | 5 个 |
| 0 - 120 | 5 个 |
0 - > 120 (+Inf) |
5 个 |
这时候就可以看到 0.5s 以下的区间还是 4 个, 但是 0.5 以上的区间就会变成 5 个了。
而一组直方图数据中,除了一组对应的区间之外,还有有两个带有 _sum 和 _count 后缀的总结数据,对于上例就是这两个:1
2prometheus_http_request_duration_seconds_sum{handler="/graph"} 0.000327554
prometheus_http_request_duration_seconds_count{handler="/graph"} 4
这个也很好理解,count 表示当前时间周期内请求该 api 的总次数, 而 sum 表示当前时间周期内所有该 api 的请求时间总和。
而且为了更方便的对直方图进行理解,我们可以在 prometheus 后台的 graph 中去应用一些函数
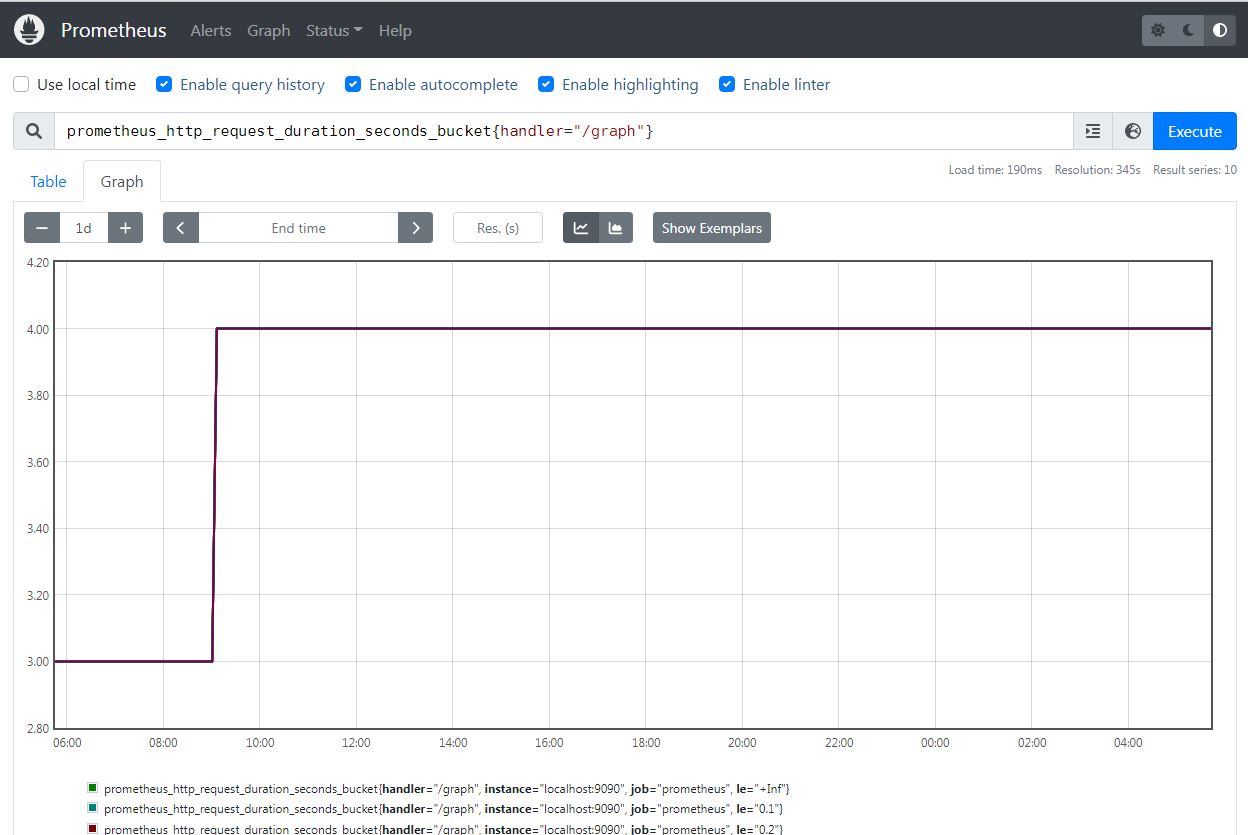
比如 histogram_quantile() 函数可用于从直方图中计算分位数
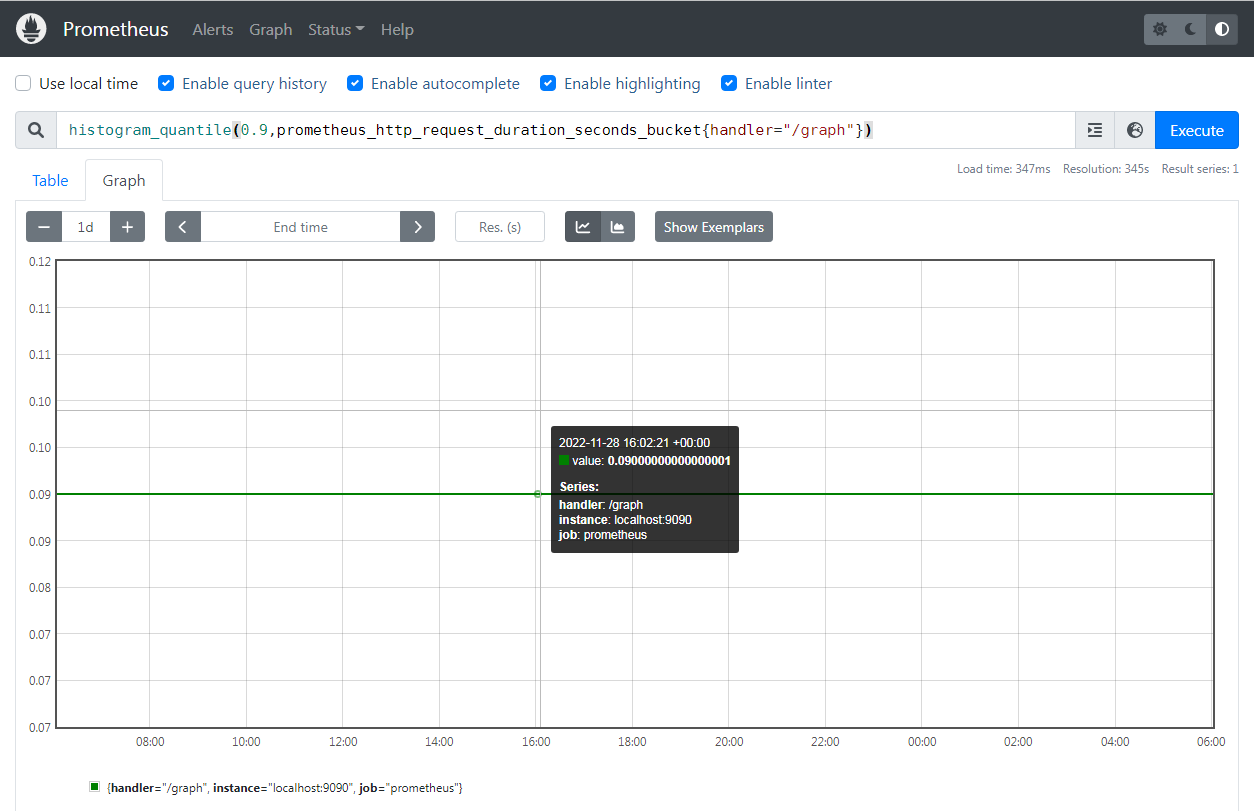
该图显示第 90 个百分位数为 0.09
4. Summary(摘要)
summary 类似于 histogram,也是一组数据。不同的是,它统计的不是区间的个数而是统计分位数。
summary 用于记录某些东西的平均大小,可能是计算所需的时间或处理的文件大小,摘要显示两个相关的信息:count(事件发生的次数)和 sum(所有事件的总大小)
还是一样以 prometheus server 的某一个指标为例:1
2
3
4
5
6
7
8
9# HELP prometheus_target_interval_length_seconds Actual intervals between scrapes.
# TYPE prometheus_target_interval_length_seconds summary
prometheus_target_interval_length_seconds{interval="15s",quantile="0.01"} 14.999039337
prometheus_target_interval_length_seconds{interval="15s",quantile="0.05"} 14.999308066
prometheus_target_interval_length_seconds{interval="15s",quantile="0.5"} 14.999972474
prometheus_target_interval_length_seconds{interval="15s",quantile="0.9"} 15.000511797
prometheus_target_interval_length_seconds{interval="15s",quantile="0.99"} 15.000882762
prometheus_target_interval_length_seconds_sum{interval="15s"} 1.06375554951154e+06
prometheus_target_interval_length_seconds_count{interval="15s"} 70917
这个是一组 summary 类型的指标, 表示每间隔 15s 抓取的配置,而实际情况执行的抓取间隔指标。 可以看到 summary 和 histogram, 都是一组指标再加两个总结 (sum 和 count)
不过他跟 histogram 不一样,他是以统计分位数来做区间统计。 也就是对于上例的数据来说,对于间隔 15s 的抓取配置来说, 总共执行了 70917 了,总的执行时间是 1.06375554951154e+06, 其中中位数(quantile=0.5) 的真实抓取的间隔时间为 14.999972474
summary 非常有用,但是因为是平均值,所以会隐藏一些细节,比如想查看时间都花在哪里了, 这时候就只需要 histogram 这种更详细的区间桶的方式来展示。 而因为它们是在应用程序级别计算的,因此不可能聚合来自同一进程的多个实例的指标。 但是用 histogram 可以做到
总结
本节主要是解释了 prometheus 最重要的数据模型和指标类型, 只有先理解这些概念,在后续更深入的学习中才不会有理解障碍。
并且简单使用了 prometheus 的 ui 后台通过使用 PromQL 语法来查询数据, 结果值有瞬时向量的值,也有范围向量。
但是也反应出了 prometheus 的数据查询后台其实功能是薄弱的,最多用来 debug 一下还行,如果要做成图表面板乃至 dashboard 的仪表盘,根本没办法做
所以官方也推荐要另外找一个视图渲染的后台来对 prometheus 的数据进行更好的数据渲染, 目前最流行的就是用 Grafana 来做数据渲染
所以下一节,我们就安装一下 Grafana 来对我们之前抓取的数据进行图表和仪表盘(dashboard)渲染。
参考资料: