前言
之前在做组内的知识库的时候,考虑到其轻量化和易编写性(只需要写 markdown 文件), 选用了 docsify 这个基于 vue 的文档生成器。 套用他的概述就是
docsify 可以快速帮你生成文档网站。不同于 GitBook、Hexo 的地方是它不会生成静态的 .html 文件,所有转换工作都是在运行时。
如果你想要开始使用它,只需要创建一个 index.html 就可以开始编写文档并直接部署在 GitHub Pages。
事实上确实非常的轻量和好用,但是有个问题,一直体验没有那么好,就是搜索, 因为随着文档越来越多, 有时候想要根据一个关键字搜索一个文档, 却发现搜索不到。
search 插件的用法
其实 docsify 是有 全文 search 的插件的,具体看: 全文搜索 - Search, 写法也没毛病, 配置也很简单, 甚至源代码都很好理解,也不复杂。
全文搜索插件会根据当前页面上的超链接获取文档内容,在 localStorage 内建立文档索引。
默认过期时间为一天,当然我们可以自己指定需要缓存的文件列表或者配置过期时间。
但是问题就出在他的配置上: 他是事先通过读取传入的 paths 参数将这些 md 文件转换为搜索索引块,然后存放到 localstorage 中的,后面整个查询其实就是前端查询, 并没有后端介入 (docsify 部署不需要后端,只需要一个 web server 托管,也不需要构建,因为请求的 vue js 会将 md 文件转换为 html 文件,这也是他轻便的根本原因), 不过也正是因为它是前端搜索,而且他的搜索源是在 localstorage 上面的。
然后他是通过我们传入的 paths 数组里面的 md 文件,他会去爬这些 md 文件的内容,然后建立搜索块,最后存放在 localstorage 中1
2
3
4
5
6search : [
'/', // => /README.md
'/guide', // => /guide.md
'/get-started', // => /get-started.md
'/zh-cn/', // => /zh-cn/README.md
],
或者是完全的配置参数:1
2
3
4
5
6
7
8
9search: {
maxAge: 86400000, // 过期时间,单位毫秒,默认一天
paths: [
'/', // => /README.md
'/guide', // => /guide.md
'/get-started', // => /get-started.md
'/zh-cn/', // => /zh-cn/README.md
],
}
也就是如果这样子配置,那么你的搜索池就是上面的 4 个 md 文件,其他 md 文件是没有在搜索池的。
当然这样子很麻烦,所以他提供了另一种搜索方式,就是:1
search: 'auto', // 默认值
或者是:1
paths: 'auto'
当你设置为 auto 的时候,他就会去找 导航栏,也就是 _sidebar.md 里面的所有的索引目录所对应的 md 文件。 然后把这些文件当做搜索池,去建立对应的 搜索索引块,然后再存到 localstorage 中, 具体代码部分如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33function init(config, vm) {
var isAuto = config.paths === 'auto';
var expireKey = resolveExpireKey(config.namespace);
var indexKey = resolveIndexKey(config.namespace);
var isExpired = localStorage.getItem(expireKey) < Date.now();
INDEXS = JSON.parse(localStorage.getItem(indexKey));
if (isExpired) {
INDEXS = {};
} else if (!isAuto) {
return
}
var paths = isAuto ? getAllPaths(vm.router) : config.paths;
var len = paths.length;
var count = 0;
paths.forEach(function (path) {
if (INDEXS[path]) {
return count++
}
Docsify
.get(vm.router.getFile(path), false, vm.config.requestHeaders)
.then(function (result) {
INDEXS[path] = genIndex(path, result, vm.router, config.depth);
len === ++count && saveData(config.maxAge, expireKey, indexKey);
});
});
}
举个例子,比如我在 _sidebar.md 是这种设置的:1
2
3
4* [目录](/)
* [官网](/xxx_web_www/)
* [管理后台](/xxx_business_admin/)
* [web端](/xxx/)
那么当我设置成 auto 之后, 这时候 localstorage 就会变成
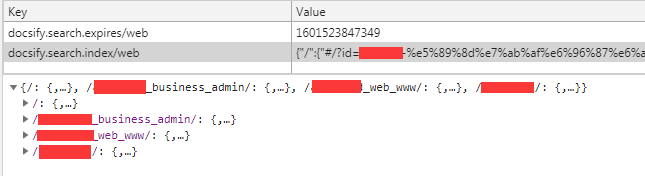
搜索池就变成这四个 md 文件了, 也就是说,如果你所有的 md 文件都在 导航栏文件_sidebar.md 中, 那么你的 localstorage 中的搜索池就是全部,这个也是我们想要的。
但是事实上,这个是很难实现的。因为不太可能你写一个 md 文件,都要去修改导航栏文件。 所以维护这个 导航栏文件 成本太高。
用脚本直接填充 paths
既然 paths 里面的 md 文件就是搜索池,那么只要将全部的 md 文件都放到这个数组里面就可以了。 所以我这边的方式,就是脚本去将所有的 md 文件写入到这个数组中。 原来的 index.html 的配置是这样子的:1
2
3
4
5
6
7
8
9
10search: {
maxAge: 86400000,
// todo 这个数组是执行脚本得到的,不需要人工修改,具体请查看 gulpfile.js
/*gulp*/paths: [],
// 允许创建的搜索索引块,定位到 6 级标题
depth: 6,
placeholder: '搜索...',
noData: '未找到结果,换个搜索词试试?',
namespace: 'web',
},
所以我们只要将这个 docsify 项目的的所有的 md 文件名称都跑出来,然后放到这个 paths 的数组就行了, 有很多种方式可以执行, 我这边选择了我比较熟练的 gulp 来操作, 具体 gulp 脚本如下:
1 | ; |
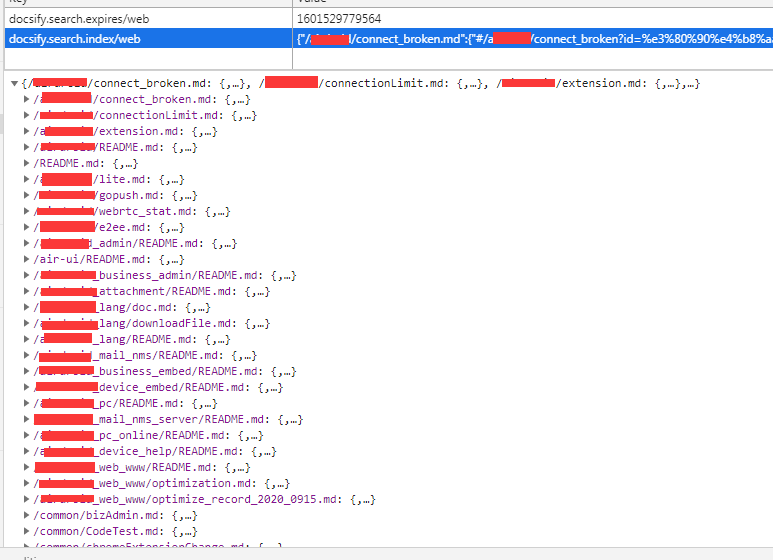
逻辑其实非常简单,就是遍历这个目录,找到所有的 md 后缀的文件,同时允许我可以忽略掉有些文件夹或者文件。最后得到一个包含全部 md 文件的数组,然后替换 index.html 的 paths 的值。 这样子就可以了。 最后执行的结果, index.html 的这个配置就变成 (因为数组太长了,我只取了一部分):1
2
3
4
5
6
7
8
9search: {
maxAge: 86400000,
// todo 这个数组是执行脚本得到的,不需要人工修改,具体请查看 gulpfile.js
/*gulp*/paths: ["/README.md","/xxx/connect_broken.md","/xxx/connectionLimit.md","/xxx/extension.md","/xxx/README.md","/xxx/lite.md","/xxx/gopush.md","/xxx/webrtc_stat.md","/xxx/e2ee.md","/xxx_admin/README.md","/air-ui/README.md","/xxx_business_admin/README.md","/xxx_attachment/README.md","/xxx_lang/doc.md","/xxx_lang/downloadFile.md","/xxx_lang/README.md","/xxx_mail_nms/README.md","/xxx_business_embed/README.md","/xxx_device_embed/README.md","/xxx_pc/README.md","/xxx_mail_nms_server/README.md","/xxx_pc_online/README.md","/xxx_device_help/README.md","/xxx_web_www/README.md","/xxx_web_www/optimization.md"],
depth: 6,
placeholder: '搜索...',
noData: '未找到结果,换个搜索词试试?',
namespace: 'web',
},
然后在浏览器查看的结果就是:
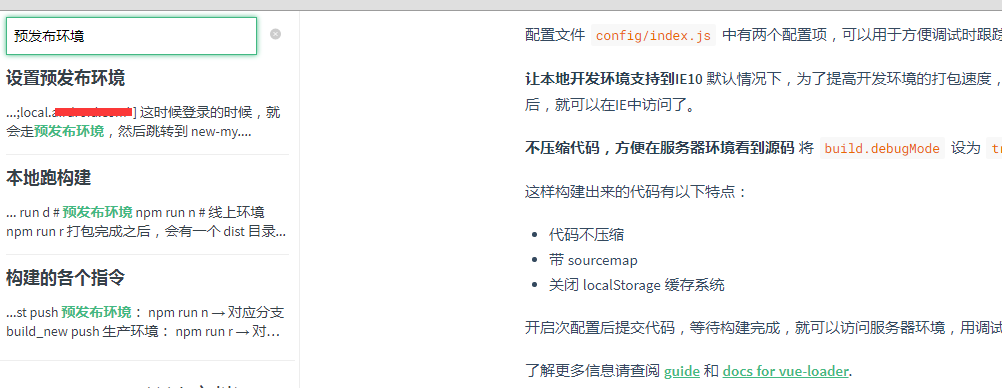
这样子搜索才是真正的全文搜索了:
后面只要定时写文档的时候,执行一下 gulp 脚本就行了。
备注
不过这边要注意一点的是, 因为是前端搜索,而且是存在 localstorage 中,而 localstorage 只能存 5M 的数据,一旦存储的数据超过 5M ,那么就会报错了。
所以如果后面出现这种情况,可能的去改一下这个 search.js 的源代码, 将其改成存放到 indexDB 才行。 这个等后面需要改的时候,我再去修改源代码,也不难。 现在先用着吧